Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48965
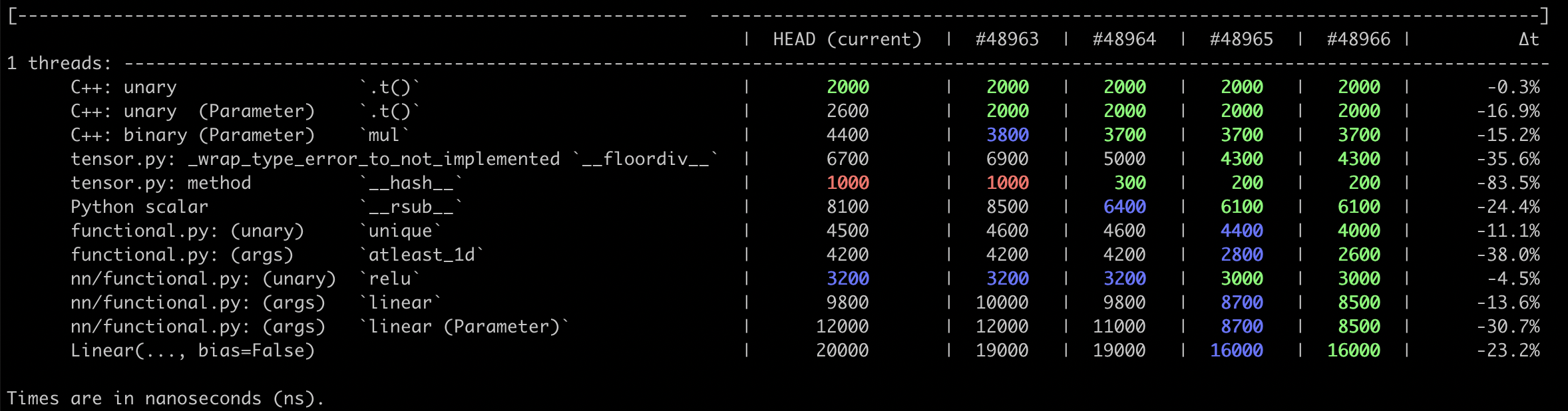
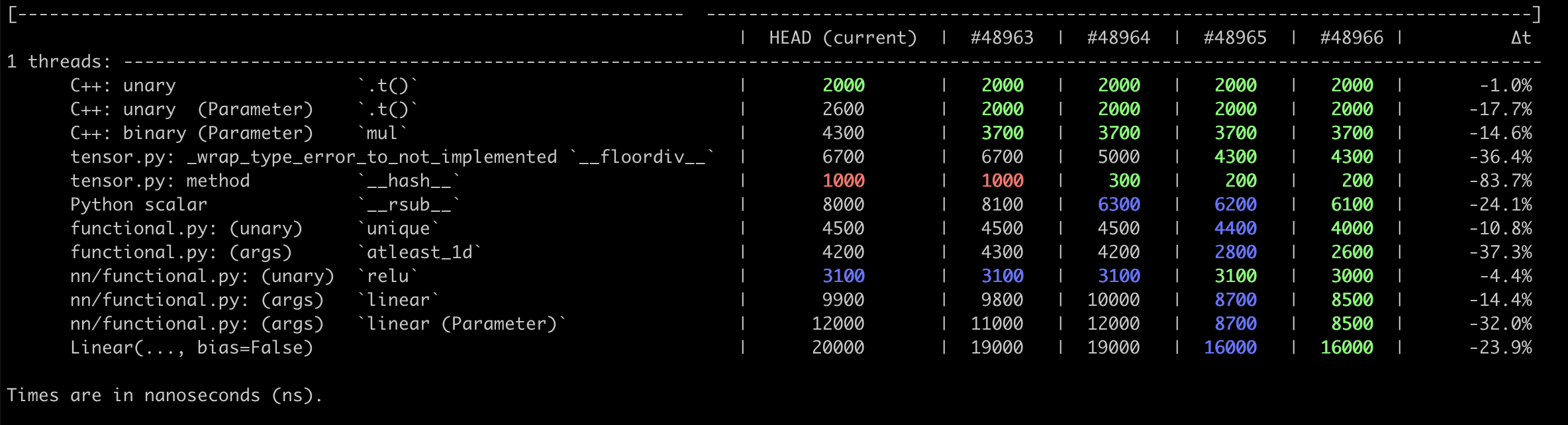
This PR pulls `__torch_function__` checking entirely into C++, and adds a special `object_has_torch_function` method for ops which only have one arg as this lets us skip tuple construction and unpacking. We can now also do away with the Python side fast bailout for `Tensor` (e.g. `if any(type(t) is not Tensor for t in tensors) and has_torch_function(tensors)`) because they're actually slower than checking with the Python C API.
Test Plan: Existing unit tests. Benchmarks are in #48966
Reviewed By: ezyang
Differential Revision: D25590732
Pulled By: robieta
fbshipit-source-id: 6bd74788f06cdd673f3a2db898143d18c577eb42
Summary:
Fixes https://github.com/pytorch/pytorch/issues/47979
For MHA module, it is preferred to use the combined weight branch as much as possible when query/key/value are same (in case of same values by `torch.equal` or exactly same object by `is` ops). This PR will enable the faster branch when a single object with `nan` is passed to MHA.
For the background knowledge
```
import torch
a = torch.tensor([float('NaN'), 1, float('NaN'), 2, 3])
print(a is a) # True
print(torch.equal(a, a)) # False
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48126
Reviewed By: gchanan
Differential Revision: D25042082
Pulled By: zhangguanheng66
fbshipit-source-id: 6bb17a520e176ddbb326ddf30ee091a84fcbbf27
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/46758
It's in general helpful to support int32 indices and offsets, especially when such tensors are large and need to be transferred to accelerator backends. Since it may not be very useful to support the combination of int32 indices and int64 offsets, here we enforce that these two must have the same type.
Test Plan: unit tests
Reviewed By: ngimel
Differential Revision: D24470808
fbshipit-source-id: 94b8a1d0b7fc9fe3d128247aa042c04d7c227f0b
Summary:
Fix https://github.com/pytorch/pytorch/issues/44601
I added bicubic grid sampler in both cpu and cuda side, but haven't in AVX2
There is a [colab notebook](https://colab.research.google.com/drive/1mIh6TLLj5WWM_NcmKDRvY5Gltbb781oU?usp=sharing) show some test results. The notebook use bilinear for test, since I could only use distributed version of pytorch in it. You could just download it and modify the `mode_torch=bicubic` to show the results.
There are some duplicate code about getting and setting values, since the helper function used in bilinear at first clip the coordinate beyond boundary, and then get or set the value. However, in bicubic, there are more points should be consider. I could refactor that part after making sure the overall calculation are correct.
Thanks
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44780
Reviewed By: mrshenli
Differential Revision: D24681114
Pulled By: mruberry
fbshipit-source-id: d39c8715e2093a5a5906cb0ef040d62bde578567
Summary:
Many of our functions contain same warnings about results reproducibility. Make them use common template.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45748
Reviewed By: colesbury
Differential Revision: D24089114
Pulled By: ngimel
fbshipit-source-id: e6aa4ce6082f6e0f4ce2713c2bf1864ee1c3712a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44433
Not entirely sure why, but changing the type of beta from `float` to `double in autocast_mode.cpp and FunctionsManual.h fixes my compiler errors, failing instead at link time
fixing some type errors, updated fn signature in a few more files
removing my usage of Scalar, making beta a double everywhere instead
Test Plan: Imported from OSS
Reviewed By: mrshenli
Differential Revision: D23636720
Pulled By: bdhirsh
fbshipit-source-id: caea2a1f8dd72b3b5fd1d72dd886b2fcd690af6d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43680
As discussed [here](https://github.com/pytorch/pytorch/issues/43342),
adding in a Python-only implementation of the triplet-margin loss that takes a
custom distance function. Still discussing whether this is necessary to add to
PyTorch Core.
Test Plan:
python test/run_tests.py
Imported from OSS
Reviewed By: albanD
Differential Revision: D23363898
fbshipit-source-id: 1cafc05abecdbe7812b41deaa1e50ea11239d0cb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44486
SmoothL1Loss had a completely different (and incorrect, see #43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the SmoothL1Loss CriterionTests to verify that the target derivative is checked.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23630699
Pulled By: gchanan
fbshipit-source-id: 0f94d1a928002122d6b6875182867618e713a917
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43025
- Use new overloads that better reflect the arguments to interpolate.
- More uniform interface for upsample ops allows simplifying the Python code.
- Also reorder overloads in native_functions.yaml to give them priority.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37177
ghstack-source-id: 106938111
Test Plan:
test_nn has pretty good coverage.
Relying on CI for ONNX, etc.
Didn't test FC because this change is *not* forward compatible.
To ensure backwards compatibility, I ran this code before this change
```python
def test_func(arg):
interp = torch.nn.functional.interpolate
with_size = interp(arg, size=(16,16))
with_scale = interp(arg, scale_factor=[2.1, 2.2], recompute_scale_factor=False)
with_compute = interp(arg, scale_factor=[2.1, 2.2])
return (with_size, with_scale, with_compute)
traced_func = torch.jit.trace(test_func, torch.randn(1,1,1,1))
sample = torch.randn(1, 3, 7, 7)
output = traced_func(sample)
assert not torch.allclose(output[1], output[2])
torch.jit.save(traced_func, "model.pt")
torch.save((sample, output), "data.pt")
```
then this code after this change
```python
model = torch.jit.load("model.pt")
sample, golden = torch.load("data.pt")
result = model(sample)
for r, g in zip(result, golden):
assert torch.allclose(r, g)
```
Reviewed By: AshkanAliabadi
Differential Revision: D21209991
fbshipit-source-id: 5b2ebb7c3ed76947361fe532d1dbdd6faa3544c8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44471
L1Loss had a completely different (and incorrect, see #43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the L1Loss CriterionTests to verify that the target derivative is checked.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23626008
Pulled By: gchanan
fbshipit-source-id: 2828be16b56b8dabe114962223d71b0e9a85f0f5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44437
MSELoss had a completely different (and incorrect, see https://github.com/pytorch/pytorch/issues/43228) path when target.requires_grad was True.
This PR does the following:
1) adds derivative support for target via the normal derivatives.yaml route
2) kill the different (and incorrect) path for when target.requires_grad was True
3) modify the MSELoss CriterionTests to verify that the target derivative is checked.
TODO:
1) do we still need check_criterion_jacobian when we run grad/gradgrad checks?
2) ensure the Module tests check when target.requires_grad
3) do we actually test when reduction='none' and reduction='mean'?
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D23612166
Pulled By: gchanan
fbshipit-source-id: 4f74d38d8a81063c74e002e07fbb7837b2172a10
Summary:
According to pytorch/rfcs#3
From the goals in the RFC:
1. Support subclassing `torch.Tensor` in Python (done here)
2. Preserve `torch.Tensor` subclasses when calling `torch` functions on them (done here)
3. Use the PyTorch API with `torch.Tensor`-like objects that are _not_ `torch.Tensor`
subclasses (done in https://github.com/pytorch/pytorch/issues/30730)
4. Preserve `torch.Tensor` subclasses when calling `torch.Tensor` methods. (done here)
5. Propagating subclass instances correctly also with operators, using
views/slices/indexing/etc. (done here)
6. Preserve subclass attributes when using methods or views/slices/indexing. (done here)
7. A way to insert code that operates on both functions and methods uniformly
(so we can write a single function that overrides all operators). (done here)
8. The ability to give external libraries a way to also define
functions/methods that follow the `__torch_function__` protocol. (will be addressed in a separate PR)
This PR makes the following changes:
1. Adds the `self` argument to the arg parser.
2. Dispatches on `self` as well if `self` is not `nullptr`.
3. Adds a `torch._C.DisableTorchFunction` context manager to disable `__torch_function__`.
4. Adds a `torch::torch_function_enabled()` and `torch._C._torch_function_enabled()` to check the state of `__torch_function__`.
5. Dispatches all `torch._C.TensorBase` and `torch.Tensor` methods via `__torch_function__`.
TODO:
- [x] Sequence Methods
- [x] Docs
- [x] Tests
Closes https://github.com/pytorch/pytorch/issues/28361
Benchmarks in https://github.com/pytorch/pytorch/pull/37091#issuecomment-633657778
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37091
Reviewed By: ngimel
Differential Revision: D22765678
Pulled By: ezyang
fbshipit-source-id: 53f8aa17ddb8b1108c0997f6a7aa13cb5be73de0
Summary:
Raise and assert used to have a hard-coded error message "Exception". User provided error message was ignored. This PR adds support to represent user's error message in TorchScript.
This breaks backward compatibility because now we actually need to script the user's error message, which can potentially contain unscriptable expressions. Such programs can break when scripting, but saved models can still continue to work.
Increased an op count in test_mobile_optimizer.py because now we need aten::format to form the actual exception message.
This is built upon an WIP PR: https://github.com/pytorch/pytorch/pull/34112 by driazati
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41907
Reviewed By: ngimel
Differential Revision: D22778301
Pulled By: gmagogsfm
fbshipit-source-id: 2b94f0db4ae9fe70c4cd03f4048e519ea96323ad
Summary:
Current losses in PyTorch only include a (partial) implementation of Huber loss through `smooth l1` based on Fast RCNN - which essentially uses a delta value of 1. Changing/Renaming the [`_smooth_l1_loss()`](3e1859959a/torch/nn/functional.py (L2487)) and refactoring to include delta, enables to use the actual function.
Supplementary to this, I have also made a functional and criterion versions for anyone that wants to set the delta explicitly - based on the functional `smooth_l1_loss()` and the criterion `Smooth_L1_Loss()`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37599
Differential Revision: D21559311
Pulled By: vincentqb
fbshipit-source-id: 34b2a5a237462e119920d6f55ba5ab9b8e086a8c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41575
Fixes https://github.com/pytorch/pytorch/issues/34294
This updates the C++ argument parser to correctly handle `TensorList` operands. I've also included a number of updates to the testing infrastructure, this is because we're now doing a much more careful job of testing the signatures of aten kernels, using the type information about the arguments as read in from `Declarations.yaml`. The changes to the tests are required because we're now only checking for `__torch_function__` attributes on `Tensor`, `Optional[Tensor]` and elements of `TensorList` operands, whereas before we were checking for `__torch_function__` on all operands, so the relatively simplistic approach the tests were using before -- assuming all positional arguments might be tensors -- doesn't work anymore. I now think that checking for `__torch_function__` on all operands was a mistake in the original design.
The updates to the signatures of the `lambda` functions are to handle this new, more stringent checking of signatures.
I also added override support for `torch.nn.functional.threshold` `torch.nn.functional.layer_norm`, which did not yet have python-level support.
Benchmarks are still WIP.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34725
Reviewed By: mruberry
Differential Revision: D22357738
Pulled By: ezyang
fbshipit-source-id: 0e7f4a58517867b2e3f193a0a8390e2ed294e1f3
Summary:
BCELoss currently uses different broadcasting semantics than numpy. Since previous versions of PyTorch have thrown a warning in these cases telling the user that input sizes should match, and since the CUDA and CPU results differ when sizes do not match, it makes sense to upgrade the size mismatch warning to an error.
We can consider supporting numpy broadcasting semantics in BCELoss in the future if needed.
Closes https://github.com/pytorch/pytorch/issues/40023
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41426
Reviewed By: zou3519
Differential Revision: D22540841
Pulled By: ezyang
fbshipit-source-id: 6c6d94c78fa0ae30ebe385d05a9e3501a42b3652
Summary:
This is a duplicate of https://github.com/pytorch/pytorch/pull/38362
"This PR completes Interpolate's deprecation process for recomputing the scales values, by updating the default value of the parameter recompute_scale_factor as planned for pytorch 1.6.0.
The warning message is also updated accordingly."
I'm recreating this PR as previous one is not being updated.
cc gchanan
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39453
Reviewed By: hl475
Differential Revision: D21955284
Pulled By: houseroad
fbshipit-source-id: 911585d39273a9f8de30d47e88f57562216968d8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37173
This function is only called in one place, so inline it. This eliminates
boilerplate related to overloads and allows for further simplification
of shared logic in later diffs.
All shared local variables have the same names (from closed_over_args),
and no local variables accidentally collide.
ghstack-source-id: 106938108
Test Plan: Existing tests for interpolate.
Differential Revision: D21209995
fbshipit-source-id: acfadf31936296b2aac0833f704764669194b06f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37172
This improves readability by keeping cases with similar behavior close
together. It should also have a very tiny positive impact on perf.
ghstack-source-id: 106938109
Test Plan: Existing tests for interpolate.
Differential Revision: D21209996
fbshipit-source-id: c813e56aa6ba7370b89a2784fcb62cc146005258
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37171
Every one of these branches returns or raises, so there's no need for elif.
This makes it a little easier to reorder and move conditions.
ghstack-source-id: 106938110
Test Plan: Existing test for interpolate.
Differential Revision: D21209992
fbshipit-source-id: 5c517e61ced91464b713f7ccf53349b05e27461c
Summary:
## Description
* Updated assert statement to remove check on 3rd dimension (features) for keys and values in MultiheadAttention / Transform
* The feature dimension for keys and values can now be of different sizes
* Refer to https://github.com/pytorch/pytorch/issues/27623
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39402
Reviewed By: zhangguanheng66
Differential Revision: D21841678
Pulled By: Nayef211
fbshipit-source-id: f0c9e5e0f33259ae2abb6bf9e7fb14e3aa9008eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/38478
Before this PR, the QAT ConvBN module inlined the batch normalization code
in order to reproduce Conv+BN folding.
This PR updates the module to use BN directly. This is mathematically
equivalent to previous behavior as long as we properly scale
and fake quant the conv weights, but allows us to reuse the BN code
instead of reimplementing it.
In particular, this should help with speed since we can use dedicated
BN kernels, and also with DDP since we can hook up SyncBatchNorm.
Test Plan:
```
python test/test_quantization.py TestQATModule
```
Imported from OSS
Differential Revision: D21603230
fbshipit-source-id: ecf8afdd833b67c2fbd21a8fd14366079fa55e64
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/38120
Test Plan: build docs locally and attach a screenshot to this PR.
Differential Revision: D21477815
Pulled By: zou3519
fbshipit-source-id: 420bbcfcbd191d1a8e33cdf4a90c95bf00a5d226
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}