albanD
6e2bb1c054
End of the .data removal in torch/optim ( #34211 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/34211
Test Plan: Imported from OSS
Differential Revision: D20248684
Pulled By: albanD
fbshipit-source-id: 2294bfa41b82ff47f000bc98860780f59d7d4421
2020-03-09 06:40:39 -07:00
Eleanor Dwight Holland
6a97777f72
Remove use of .data from optimizers ( #33640 )
...
Summary:
Removes all uses of `.data` from optimizers.
Or tries to.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33640
Reviewed By: vincentqb
Differential Revision: D20203216
Pulled By: albanD
fbshipit-source-id: 9bfe78bbed00fd4aaa690801cff0201f0bd680a0
2020-03-03 13:21:55 -08:00
Xiao Wang
c1dd70688a
Fix deprecated python "add" calls ( #33428 )
...
Summary:
This PR fixed those python "add" calls using deprecated signature `add(Scalar, Tensor)`. The alternative signature `add(Tensor, alpha = Scalar)` is used.
cc csarofeen zasdfgbnm ptrblck ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33428
Differential Revision: D20002534
Pulled By: vincentqb
fbshipit-source-id: 81f2dd6170a47a9b53a17e5817c26e70d8afa130
2020-02-26 09:02:31 -08:00
Enealor
e085c55e53
Fix \\ warnings/errors when building optim documentation ( #32911 )
...
Summary:
This PR fixes the warnings and errors attributed to the use of `\\` outside of a proper environment. While rendered correctly in the documentation, it produces the warning
```
LaTeX-incompatible input and strict mode is set to 'warn': In LaTeX, \\ or \newline does nothing in display mode [newLineInDisplayMode]
```
on the CI tools and errors with
```
ParseError: KaTeX parse error: Expected 'EOF', got '\\' at position (x): ...
```
when not set to warn.
This PR also makes minor formatting adjustments. The `CosineAnnealingLR` documentation has been adjusted to remove an unnecessarily large fraction and to improve spacing. The `SGD` documentation has been adjusted so that variables are consistently typeset and so that it follows the convention of punctuating equations. I attached images of the current documentation, the new documentation and a marked version to highlight differences.
* SGD:
New: 
Current: 
Marked new: 
* CosineAnnealingLR:
New: 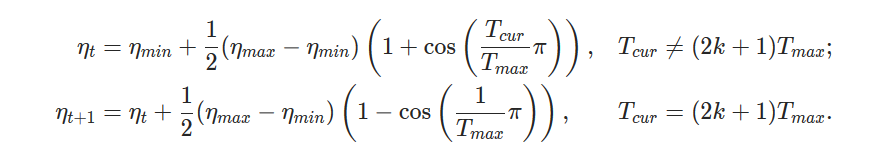
Current: 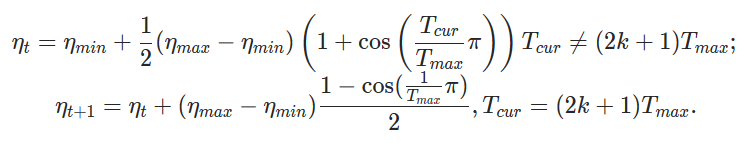
Marked new: 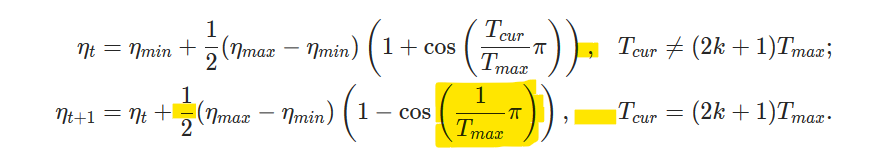
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32911
Differential Revision: D19697114
Pulled By: ezyang
fbshipit-source-id: 567304bd4adcfa4086eae497cb818cf74375fe5d
2020-02-03 09:54:38 -08:00
albanD
b0871f211b
Make all optimizers consistent so that they don't change gradients inplace
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/30257
Test Plan: Imported from OSS
Differential Revision: D18665461
Pulled By: albanD
fbshipit-source-id: cfdafef919468a41007881b82fd288b7128baf95
2019-11-26 12:16:25 -08:00
Horace He
bb41e62e3b
Updated SGD docs with subscripts ( #23985 )
...
Summary:
Fixes https://github.com/pytorch/pytorch/issues/23982
Obvious improvement imo.
Also changed `rho` to `mu`, since `rho` and `p` look very similar.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/23985
Differential Revision: D16733037
Pulled By: Chillee
fbshipit-source-id: 5431615d1983f24d6582da6fc8103ac0093b5832
2019-08-09 10:32:40 -07:00
Neta Zmora
1c76746f61
SGD: remove unneeded multiply-add initialization operations ( #18114 )
...
Summary:
The momentum buffer is initialized to the value of
d_p, but the current code takes the long way to do this:
1. Create a buffer of zeros
2. Multiply the buffer by the momentum coefficient
3. Add d_p to the buffer
All of these can be collapsed into a single step:
1. Create a clone of d_p
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18114
Differential Revision: D14509122
Pulled By: ezyang
fbshipit-source-id: 4a79b896201d5ff20770b7ae790c244ba744edb8
2019-03-19 10:34:17 -07:00
Tongzhou Wang
a2880531ea
fix SGD lr check ( #6244 )
2018-04-03 21:29:18 -04:00
lazypanda1
063946d2b3
Added parameter range checks for all optimizers ( #6000 )
2018-03-28 11:22:23 +02:00
SsnL
f76d6c029c
Sparse Adam optimizer for sparse gradients ( #3137 )
...
* sparse adam
* Favor dense addition over sparse_mask
2017-11-06 14:20:51 -05:00
SsnL
ba05dc5549
dense buffer ( #3139 )
2017-10-17 00:51:37 +02:00
Taehoon Lee
61e4723132
Fix typos ( #2472 )
2017-08-25 14:13:38 -04:00
Leonid Vlasenkov
46a868dab7
[Ready] Limit docs line length ( #1900 )
...
* some docs are ready
* docs
* docs
* fix some more
* fix some more
2017-07-10 10:24:54 -04:00
Soumith Chintala
85954032d9
fix doc formatting
2017-04-05 22:02:29 -04:00
Nitish Shirish Keskar
1a04b92226
add note regarding SGD momentum
2017-04-05 20:45:41 -04:00
Martin Raison
f17cfe4293
sparse tensor operations ( #735 )
2017-03-03 18:37:03 +01:00
Adam Paszke
3277d83648
Add Nesterov Momentum ( #887 )
2017-03-01 20:49:59 +01:00
Adam Paszke
ecfcf39f30
Improve optimizer serialization
...
Also, add optimizer.load_state_dict
2017-01-24 17:30:50 -05:00
Adam Paszke
95f0fa8a92
Change .grad attribute of Variables to be a Variable
2017-01-16 12:59:47 -05:00
Adam Paszke
604e13775f
Add optim docs
2017-01-16 12:59:47 -05:00
Adam Paszke
75d850cfd2
Fix optim docs
2016-12-30 00:15:06 -05:00
Sam Gross
126a1cc398
Add Sphinx docs
2016-12-28 00:03:39 +01:00
Sam Gross
162170fd7b
Add optional weight decay to optim.SGD ( #269 )
2016-11-29 20:35:40 -05:00
Adam Paszke
09493603f6
Change optimizer API
2016-11-08 18:12:56 +01:00
Adam Paszke
df59b89fbb
Add more optimizers
2016-11-07 22:50:56 +01:00
Adam Paszke
4db6667923
Allow specifying per-parameter optimization parameters
2016-10-04 18:21:50 -07:00
Adam Paszke
58b134b793
Allow exporting optimizer state as a dict
2016-10-04 17:33:49 -07:00
Soumith Chintala
9842be4b15
setting default dampening value to 0
2016-09-13 10:28:33 -07:00
Adam Paszke
ff785e5f17
Make optimizers accept a closure
2016-08-25 09:23:39 -07:00
Adam Paszke
7bcb2a4081
Initial optim version
2016-08-23 19:03:30 -07:00
Adam Paszke
2f342af22f
Move optim to legacy
2016-08-01 12:01:46 -04:00
Adam Paszke
554a1d8336
Add optim
2016-07-21 16:42:06 -04:00
{kind=link}
{kind=link}
{kind=link}
{kind=link}
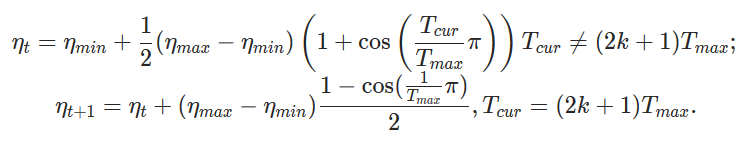{kind=link}
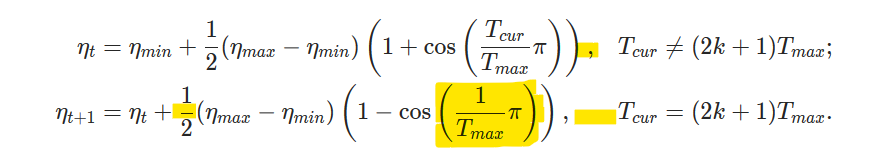{kind=link}