Wanchao Liang
08caf15502
[optimizer] refactor Adam to use functional API ( #44791 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/44791
Test Plan: Imported from OSS
Reviewed By: ailzhang
Differential Revision: D23935257
Pulled By: wanchaol
fbshipit-source-id: 6f6e22a9287f5515d2e4e6abd4dee2fe7e17b945
2020-09-25 17:13:08 -07:00
Xiang Gao
6bc77f4d35
Use amax/maximum instead of max in optimizers ( #43797 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/43797
Reviewed By: malfet
Differential Revision: D23406641
Pulled By: mruberry
fbshipit-source-id: 0cd075124aa6533b21375fe2c90c44a5d05ad6e6
2020-09-15 10:39:40 -07:00
farhadrgh
4b4273a04e
Update Adam documentation ( #41679 )
...
Summary:
This PR fixes https://github.com/pytorch/pytorch/issues/41477
Adam implementation is doing L2 regularization and not decoupled weight decay. However, the change mentioned in https://github.com/pytorch/pytorch/issues/41477 was motivated by Line 12 of algorithm 2 in [Decoupled Weight Decay Regularization](https://arxiv.org/pdf/1711.05101.pdf ) paper.
Please let me know if you have other suggestions about how to deliver this info in the docs.
cc ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41679
Reviewed By: izdeby
Differential Revision: D22671329
Pulled By: vincentqb
fbshipit-source-id: 2caf60e4f62fe31f29aa35a9532d1c6895a24224
2020-07-23 09:25:41 -07:00
albanD
6e2bb1c054
End of the .data removal in torch/optim ( #34211 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/34211
Test Plan: Imported from OSS
Differential Revision: D20248684
Pulled By: albanD
fbshipit-source-id: 2294bfa41b82ff47f000bc98860780f59d7d4421
2020-03-09 06:40:39 -07:00
Eleanor Dwight Holland
6a97777f72
Remove use of .data from optimizers ( #33640 )
...
Summary:
Removes all uses of `.data` from optimizers.
Or tries to.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33640
Reviewed By: vincentqb
Differential Revision: D20203216
Pulled By: albanD
fbshipit-source-id: 9bfe78bbed00fd4aaa690801cff0201f0bd680a0
2020-03-03 13:21:55 -08:00
Xiao Wang
c1dd70688a
Fix deprecated python "add" calls ( #33428 )
...
Summary:
This PR fixed those python "add" calls using deprecated signature `add(Scalar, Tensor)`. The alternative signature `add(Tensor, alpha = Scalar)` is used.
cc csarofeen zasdfgbnm ptrblck ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33428
Differential Revision: D20002534
Pulled By: vincentqb
fbshipit-source-id: 81f2dd6170a47a9b53a17e5817c26e70d8afa130
2020-02-26 09:02:31 -08:00
Nikolay Novik
d19a50bf27
Add missing weight_decay parameter validation for Adam and AdamW ( #33126 )
...
Summary:
Adam and AdamW are missing parameter validation for weight_decay. Other optimisers have this check present.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33126
Differential Revision: D19860366
Pulled By: vincentqb
fbshipit-source-id: 286d7dc90e2f4ccf6540638286d2fe17939648fc
2020-02-20 11:11:51 -08:00
albanD
b0871f211b
Make all optimizers consistent so that they don't change gradients inplace
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/30257
Test Plan: Imported from OSS
Differential Revision: D18665461
Pulled By: albanD
fbshipit-source-id: cfdafef919468a41007881b82fd288b7128baf95
2019-11-26 12:16:25 -08:00
Vitaly Fedyunin
877c96cddf
explicitly provide memory format when calling to *_like operators
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/30008
Test Plan: Imported from OSS
Differential Revision: D18575981
Pulled By: VitalyFedyunin
fbshipit-source-id: ec3418257089ad57913932be1a8608cd20ce054c
2019-11-19 16:19:29 -08:00
Farhad Ramezanghorbani
fed5ca192c
Adam/AdamW implementation minor fix ( #22628 )
...
Summary:
I have noticed a small discrepancy between theory and the implementation of AdamW and in general Adam. The epsilon in the denominator of the following Adam update should not be scaled by the bias correction [(Algorithm 2, L9-12)](https://arxiv.org/pdf/1711.05101.pdf ). Only the running average of the gradient (_m_) and squared gradients (_v_) should be scaled by their corresponding bias corrections.
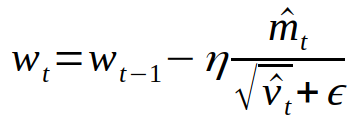
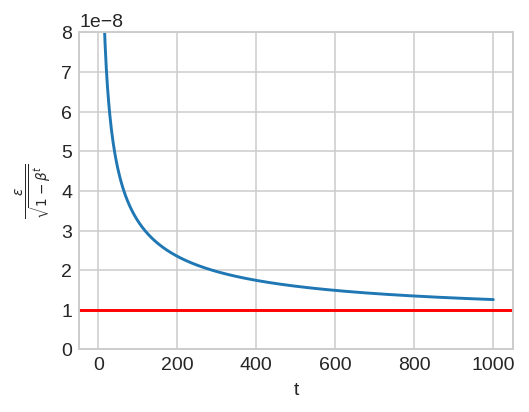
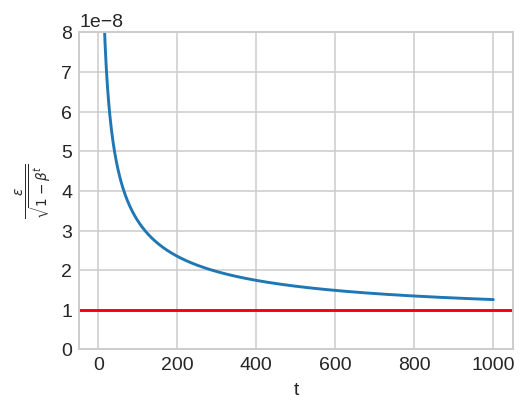
In the current implementation, the epsilon is scaled by the square root of `bias_correction2`. I have plotted this ratio as a function of step given `beta2 = 0.999` and `eps = 1e-8`. In the early steps of optimization, this ratio slightly deviates from theory (denoted by the horizontal red line).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22628
Differential Revision: D16589914
Pulled By: vincentqb
fbshipit-source-id: 8791eb338236faea9457c0845ccfdba700e5f1e7
2019-08-01 11:42:04 -07:00
Soumith Chintala
cf235e0894
fix lint after new flake8 release added new style constraints ( #13047 )
...
Summary:
fix lint after new flake8 release added new style constraints
Pull Request resolved: https://github.com/pytorch/pytorch/pull/13047
Differential Revision: D10527804
Pulled By: soumith
fbshipit-source-id: 6f4d02662570b6339f69117b61037c8394b0bbd8
2018-10-24 09:03:38 -07:00
Jerry Ma
383d340e88
Small optimization for adam ( #12107 )
...
Summary:
Apply weight decay for Adam in-place instead of via copy.
Synced offline with soumith , who mentioned that it should be OK. This is also consistent with other optimizers, e.g. eee01731a5/torch/optim/sgd.py (L93)https://github.com/pytorch/pytorch/pull/12107
Reviewed By: soumith
Differential Revision: D10071787
Pulled By: jma127
fbshipit-source-id: 5fd7939c79039693b225c44c4c80450923b8d673
2018-09-26 21:43:46 -07:00
rasbt
eee01731a5
Adds the default value for the amsgrad arg to the Adam docstring ( #9971 )
...
Summary:
Minor addition to the docstring of `torch.nn.optim.Adam`, adding the default argument description for the `amsgrad` argument to the docstring for concistency.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9971
Differential Revision: D9040820
Pulled By: soumith
fbshipit-source-id: 168744a6bb0d1422331beffd7e694b9d6f61900c
2018-07-28 09:23:45 -07:00
lazypanda1
063946d2b3
Added parameter range checks for all optimizers ( #6000 )
2018-03-28 11:22:23 +02:00
li-roy
df88373f88
set default ams param in adam optimizer ( #5501 )
2018-03-02 11:43:06 +01:00
lazypanda1
a061000250
Added check and test for betas parameter in Adam optimizer ( #5147 )
...
* Added check and test for betas parameter in Adam optimizer
* Simplified test
2018-02-11 20:24:43 -05:00
Dr. Kashif Rasul
68c0998cbe
added AMSgrad optimizer to Adam and SparseAdam ( #4034 )
...
* initial AMSGrad
* added test for amsgrad
* added amsgrad to adam
* fixed tests
* added option to sparse adam
* flake8
2017-12-18 13:24:49 -05:00
SsnL
f76d6c029c
Sparse Adam optimizer for sparse gradients ( #3137 )
...
* sparse adam
* Favor dense addition over sparse_mask
2017-11-06 14:20:51 -05:00
Martin Raison
f17cfe4293
sparse tensor operations ( #735 )
2017-03-03 18:37:03 +01:00
Adam McCarthy
7926324385
Corrected parameter typo in Adam docstring ( #697 )
2017-02-07 19:00:10 +01:00
Luke Yeager
e7c1e6a8e3
[pep8] Fix most lint automatically with autopep8
...
Here's the command I used to invoke autopep8 (in parallel!):
git ls-files | grep '\.py$' | xargs -n1 -P`nproc` autopep8 -i
Several rules are ignored in setup.cfg. The goal is to let autopep8
handle everything which it can handle safely, and to disable any rules
which are tricky or controversial to address. We may want to come back
and re-enable some of these rules later, but I'm trying to make this
patch as safe as possible.
Also configures flake8 to match pep8's behavior.
Also configures TravisCI to check the whole project for lint.
2017-01-28 01:15:51 +01:00
Adam Paszke
ecfcf39f30
Improve optimizer serialization
...
Also, add optimizer.load_state_dict
2017-01-24 17:30:50 -05:00
Sergey Zagoruyko
2748b920ab
make adam have the same lr as lua torch ( #576 )
2017-01-24 16:35:28 -05:00
Adam Paszke
95f0fa8a92
Change .grad attribute of Variables to be a Variable
2017-01-16 12:59:47 -05:00
Adam Paszke
604e13775f
Add optim docs
2017-01-16 12:59:47 -05:00
Adam Paszke
09493603f6
Change optimizer API
2016-11-08 18:12:56 +01:00
Adam Paszke
df59b89fbb
Add more optimizers
2016-11-07 22:50:56 +01:00
Adam Paszke
2f342af22f
Move optim to legacy
2016-08-01 12:01:46 -04:00
Adam Paszke
554a1d8336
Add optim
2016-07-21 16:42:06 -04:00
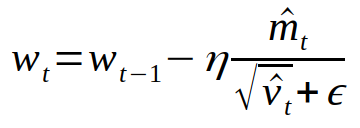{kind=link}
{kind=link}