Summary:
The `i` variable in `Line 272` may cause ambiguity in understanding. I think it should be named as `epoch` variable.
Fixes #{issue number}
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45944
Reviewed By: agolynski
Differential Revision: D24219486
Pulled By: vincentqb
fbshipit-source-id: 2af0408594613e82a1a1b63971650cabde2b576e
Summary:
This PR adds a description of `torch.optim.swa_utils` added in https://github.com/pytorch/pytorch/pull/35032 to the docs at `docs/source/optim.rst`. Please let me know what you think!
vincentqb andrewgordonwilson
Pull Request resolved: https://github.com/pytorch/pytorch/pull/41228
Reviewed By: ngimel
Differential Revision: D22609451
Pulled By: vincentqb
fbshipit-source-id: 8dd98102c865ae4a074a601b047072de8cc5a5e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27254
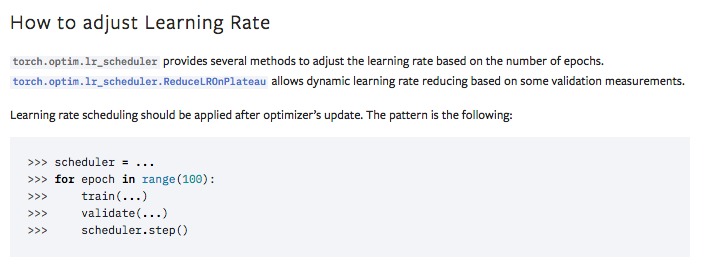
`MultiplicativeLR` consumes a function providing the multiplicative factor at each epoch. It mimics `LambdaLR` in its syntax.
Test Plan: Imported from OSS
Differential Revision: D17728088
Pulled By: vincentqb
fbshipit-source-id: 1c4a8e19a4f24c87b5efccda01630c8a970dc5c9
Summary:
# What is this?
This is an implementation of the AdamW optimizer as implemented in [the fastai library](803894051b/fastai/callback.py) and as initially introduced in the paper [Decoupled Weight Decay Regularization](https://arxiv.org/abs/1711.05101). It decouples the weight decay regularization step from the optimization step during training.
There have already been several abortive attempts to push this into pytorch in some form or fashion: https://github.com/pytorch/pytorch/pull/17468, https://github.com/pytorch/pytorch/pull/10866, https://github.com/pytorch/pytorch/pull/3740, https://github.com/pytorch/pytorch/pull/4429. Hopefully this one goes through.
# Why is this important?
Via a simple reparameterization, it can be shown that L2 regularization has a weight decay effect in the case of SGD optimization. Because of this, L2 regularization became synonymous with the concept of weight decay. However, it can be shown that the equivalence of L2 regularization and weight decay breaks down for more complex adaptive optimization schemes. It was shown in the paper [Decoupled Weight Decay Regularization](https://arxiv.org/abs/1711.05101) that this is the reason why models trained with SGD achieve better generalization than those trained with Adam. Weight decay is a very effective regularizer. L2 regularization, in and of itself, is much less effective. By explicitly decaying the weights, we can achieve state-of-the-art results while also taking advantage of the quick convergence properties that adaptive optimization schemes have.
# How was this tested?
There were test cases added to `test_optim.py` and I also ran a [little experiment](https://gist.github.com/mjacar/0c9809b96513daff84fe3d9938f08638) to validate that this implementation is equivalent to the fastai implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21250
Differential Revision: D16060339
Pulled By: vincentqb
fbshipit-source-id: ded7cc9cfd3fde81f655b9ffb3e3d6b3543a4709
Summary:
This implements a cyclical learning rate (CLR) schedule with an optional inverse cyclical momentum. More info about CLR: https://github.com/bckenstler/CLR
This is finishing what #2016 started. Resolves#1909.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18001
Differential Revision: D14451845
Pulled By: sampepose
fbshipit-source-id: 8f682e0c3dee3a73bd2b14cc93fcf5f0e836b8c9
{kind=link}