OK, so this PR used to be about reducing the number of constants we specialize on, but it turns out that unspecialization was ~essentially never used (because we still constant specialized way too aggressively) and I ended up having to fix a bunch of issues to actually get tests to pass. So this PR is now "make int unspecialization actually work". As part of this, I have to turn off unspecialization by default, as there are still latent bugs in inductor.
The general strategy is that an unspecialized int is represented as a SymInt. Representing it as a 0d tensor (which is what the code used to do) is untenable: (1) we often need unspecialized ints to participate in size computations, but we have no way of propagating sympy expressions through tensor compute, and (2) a lot of APIs work when passed SymInt, but not when passed a Tensor. However, I continue to represent Numpy scalars as Tensors, as they are rarely used for size computation and they have an explicit dtype, so they are more accurately modeled as 0d tensors.
* I folded in the changes from https://github.com/pytorch/pytorch/pull/95099 as I cannot represent unspecialized ints as SymInts without also turning on dynamic shapes. This also eliminates the necessity for test_unspec.py, as toggling specialization without dynamic shapes doesn't do anything. As dynamic shapes defaults to unspecializing, I just deleted this entirely; for the specialization case, I rely on regular static shape tests to catch it. (Hypothetically, we could also rerun all the tests with dynamic shapes, but WITH int/float specialization, but this seems... not that useful? I mean, I guess export wants it, but I'd kind of like our Source heuristic to improve enough that export doesn't have to toggle this either.)
* Only 0/1 integers get specialized by default now
* A hodgepodge of fixes. I'll comment on the PR about them.
Fixes https://github.com/pytorch/pytorch/issues/95469
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95621
Approved by: https://github.com/jansel, https://github.com/Chillee
Summary: When running the benchmark test with --accuracy, two eager runs
should return the same result. If not, we want to detect it early, but
comparing against fp64_output may hide the non-deterministism in eager.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95616
Approved by: https://github.com/ZainRizvi
I believe this fixes the AllenaiLongformerBase problem in periodic.
The longer version of the problem is here is we are currently optimistically converting all item() calls into unbacked SymInt/SymFloat, but sometimes this results in a downstream error due to a data-dependent guard. Fallbacks for this case are non-existent; this will just crash the model. This is bad. So we flag guard until we get working fallbacks.
What could these fallbacks look like? One idea I have is to optimistically make data-dependent calls unbacked, but then if it results in a crash, restart Dynamo analysis with the plan of graph breaking when the item() call immediately happened.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94987
Approved by: https://github.com/Skylion007, https://github.com/malfet
```
GuardOnDataDependentSymNode: It appears that you're trying to get a value out of symbolic int/float whose value is data-dependent (and thus we do not know the true value.) The expression we were trying to evaluate is Eq(i3, -1). Scroll up to see where each of these data-dependent accesses originally occurred.
While executing %as_strided : [#users=1] = call_method[target=as_strided](args = (%pad,), kwargs = {size: (12, %add, 768, 64), stride: (%getitem, %mul, %getitem_1, %getitem_2)})
Original traceback:
File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/transformers/models/longformer/modeling_longformer.py", line 928, in <graph break in _sliding_chunks_matmul_attn_probs_value>
chunked_value = padded_value.as_strided(size=chunked_value_size, stride=chunked_value_stride)
```
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94986
Approved by: https://github.com/albanD
Summary: It looks like setting torch.backends.cudnn.deterministic to
True is not enough for eliminating non-determinism when testing
benchmarks with --accuracy, so let's turn off cudnn completely.
With this change, mobilenet_v3_large does not show random failure on my
local environment. Also take this chance to clean up CI skip lists.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94363
Approved by: https://github.com/ezyang
Preferring dash over underscore in command-line options. Add `--command-arg-name` to the argument parser. The old arguments with underscores `--command_arg_name` are kept for backward compatibility.
Both dashes and underscores are used in the PyTorch codebase. Some argument parsers only have dashes or only have underscores in arguments. For example, the `torchrun` utility for distributed training only accepts underscore arguments (e.g., `--master_port`). The dashes are more common in other command-line tools. And it looks to be the default choice in the Python standard library:
`argparse.BooleanOptionalAction`: 4a9dff0e5a/Lib/argparse.py (L893-L895)
```python
class BooleanOptionalAction(Action):
def __init__(...):
if option_string.startswith('--'):
option_string = '--no-' + option_string[2:]
_option_strings.append(option_string)
```
It adds `--no-argname`, not `--no_argname`. Also typing `_` need to press the shift or the caps-lock key than `-`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94505
Approved by: https://github.com/ezyang, https://github.com/seemethere
The functorch setting still exists, but now it is no longer necessary:
we infer use of Python dispatcher by checking if the ambient
FakeTensorMode has a ShapeEnv or not. The setting still exists,
but it is for controlling direct AOTAutograd use now; for PT2,
it's sufficient to use torch._dynamo.config.dynamic_shapes.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94469
Approved by: https://github.com/Chillee, https://github.com/voznesenskym, https://github.com/jansel
Summary: It looks like setting torch.backends.cudnn.deterministic to
True is not enough for eliminating non-determinism when testing
benchmarks with --accuracy, so let's turn off cudnn completely.
With this change, mobilenet_v3_large does not show random failure on my
local environment. Also take this chance to clean up CI skip lists.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94363
Approved by: https://github.com/ezyang
Change the dynamo benchmark timeout from hard code to a parameter with default value 1200ms, cause the hard code 1200ms timeout led some single thread mode model crashed on CPU platform. With the parameter, users can specify the timeout freely.
Fixes#94281
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94284
Approved by: https://github.com/malfet
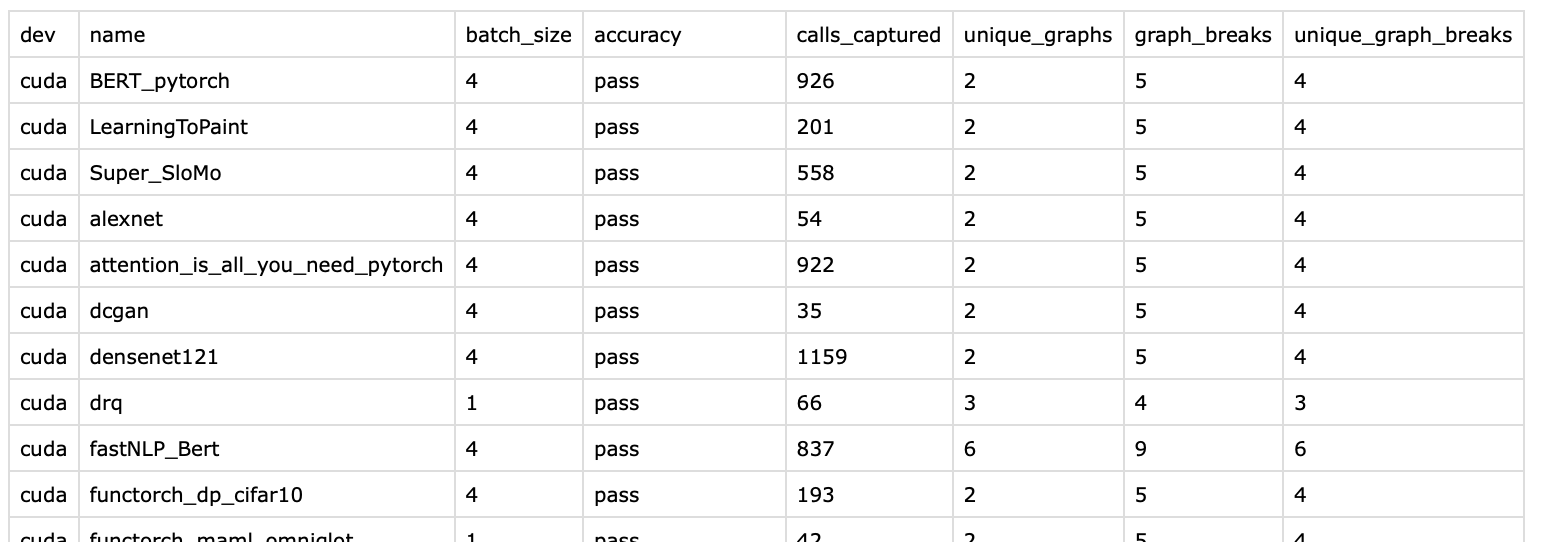
graph break != graph count - 1. Suppose you have a nested
inline function call f1 to f2 to f3. A graph break in f3
results in six graphs: f1 before, f2 before, f3 before, f3 after,
f2 after, f1 after.
Signed-off-by: Edward Z. Yang <ezyang@meta.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/94143
Approved by: https://github.com/voznesenskym
These backends have been broken for some time. I tried to get them
running again, but as far as I can tell they are not maintained.
Installing torch_tensorrt downgrades PyTorch to 1.12. If I manually
bypass that downgrade, I get import errors from inside fx2trt. Fixes that
re-add these are welcome, but it might make sense to move these wrappers
to the torch_tensorrt repo once PyTorch 2.0 support is added.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93822
Approved by: https://github.com/frank-wei
As @peterbell10 pointed out, it was giving incorrect results for `compression_ratio`
and `compression_latency` when you used `--diff-branch`.
This fixes this by running a separate subprocess for each branch to make sure you are not being affected by run for other branch.
Also added a couple of more significant figures
to numbers in summary table.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93989
Approved by: https://github.com/jansel
{kind=link}
{kind=link}