Fixes#112592
1) **File: torch/cuda/random.py**
```
Before:
/content/pytorch/torch/cuda/random.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/cuda/random.py:21 in public function `get_rng_state`:
D401: First line should be in imperative mood (perhaps 'Return', not 'Returns')
/content/pytorch/torch/cuda/random.py:43 in public function `get_rng_state_all`:
D202: No blank lines allowed after function docstring (found 1)
/content/pytorch/torch/cuda/random.py:43 in public function `get_rng_state_all`:
D401: First line should be in imperative mood (perhaps 'Return', not 'Returns')
/content/pytorch/torch/cuda/random.py:54 in public function `set_rng_state`:
D401: First line should be in imperative mood (perhaps 'Set', not 'Sets')
/content/pytorch/torch/cuda/random.py:79 in public function `set_rng_state_all`:
D208: Docstring is over-indented
/content/pytorch/torch/cuda/random.py:79 in public function `set_rng_state_all`:
D209: Multi-line docstring closing quotes should be on a separate line
/content/pytorch/torch/cuda/random.py:79 in public function `set_rng_state_all`:
D401: First line should be in imperative mood (perhaps 'Set', not 'Sets')
/content/pytorch/torch/cuda/random.py:79 in public function `set_rng_state_all`:
D414: Section has no content ('Args')
/content/pytorch/torch/cuda/random.py:88 in public function `manual_seed`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/cuda/random.py:88 in public function `manual_seed`:
D401: First line should be in imperative mood (perhaps 'Set', not 'Sets')
/content/pytorch/torch/cuda/random.py:110 in public function `manual_seed_all`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/cuda/random.py:110 in public function `manual_seed_all`:
D401: First line should be in imperative mood (perhaps 'Set', not 'Sets')
/content/pytorch/torch/cuda/random.py:128 in public function `seed`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/cuda/random.py:128 in public function `seed`:
D401: First line should be in imperative mood (perhaps 'Set', not 'Sets')
/content/pytorch/torch/cuda/random.py:146 in public function `seed_all`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/cuda/random.py:146 in public function `seed_all`:
D401: First line should be in imperative mood (perhaps 'Set', not 'Sets')
/content/pytorch/torch/cuda/random.py:167 in public function `initial_seed`:
D401: First line should be in imperative mood (perhaps 'Return', not 'Returns')
18
```
```
After:
/content/pytorch/torch/cuda/random.py:1 at module level:
D100: Missing docstring in public module
1
```
2) **File: torch/cuda/amp/autocast_mode.py**
```
Before: /content/pytorch/torch/cuda/amp/autocast_mode.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/cuda/amp/autocast_mode.py:18 in public class `autocast`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/cuda/amp/autocast_mode.py:23 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/cuda/amp/autocast_mode.py:38 in public method `__enter__`:
D105: Missing docstring in magic method
/content/pytorch/torch/cuda/amp/autocast_mode.py:44 in public method `__exit__`:
D105: Missing docstring in magic method
/content/pytorch/torch/cuda/amp/autocast_mode.py:49 in public method `__call__`:
D102: Missing docstring in public method
/content/pytorch/torch/cuda/amp/autocast_mode.py:90 in public function `custom_fwd`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/cuda/amp/autocast_mode.py:90 in public function `custom_fwd`:
D400: First line should end with a period (not 'f')
/content/pytorch/torch/cuda/amp/autocast_mode.py:90 in public function `custom_fwd`:
D401: First line should be in imperative mood; try rephrasing (found 'Helper')
/content/pytorch/torch/cuda/amp/autocast_mode.py:130 in public function `custom_bwd`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/cuda/amp/autocast_mode.py:130 in public function `custom_bwd`:
D400: First line should end with a period (not 'f')
/content/pytorch/torch/cuda/amp/autocast_mode.py:130 in public function `custom_bwd`:
D401: First line should be in imperative mood; try rephrasing (found 'Helper')
12
```
```
After:
/content/pytorch/torch/cuda/amp/autocast_mode.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/cuda/amp/autocast_mode.py:23 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/cuda/amp/autocast_mode.py:38 in public method `__enter__`:
D105: Missing docstring in magic method
/content/pytorch/torch/cuda/amp/autocast_mode.py:44 in public method `__exit__`:
D105: Missing docstring in magic method
/content/pytorch/torch/cuda/amp/autocast_mode.py:49 in public method `__call__`:
D102: Missing docstring in public method
5
```
3) **File: torch/cuda/amp/grad_scaler.py**
```
Before: /content/pytorch/torch/cuda/amp/grad_scaler.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/cuda/amp/grad_scaler.py:17 in private class `_MultiDeviceReplicator`:
D200: One-line docstring should fit on one line with quotes (found 3)
/content/pytorch/torch/cuda/amp/grad_scaler.py:39 in public class `OptState`:
D101: Missing docstring in public class
/content/pytorch/torch/cuda/amp/grad_scaler.py:50 in public class `GradScaler`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/cuda/amp/grad_scaler.py:50 in public class `GradScaler`:
D400: First line should end with a period (not 'g')
/content/pytorch/torch/cuda/amp/grad_scaler.py:115 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/cuda/amp/grad_scaler.py:354 in public method `step`:
D400: First line should end with a period (not ':')
/content/pytorch/torch/cuda/amp/grad_scaler.py:456 in public method `update`:
D401: First line should be in imperative mood (perhaps 'Update', not 'Updates')
/content/pytorch/torch/cuda/amp/grad_scaler.py:529 in public method `get_scale`:
D401: First line should be in imperative mood (perhaps 'Return', not 'Returns')
/content/pytorch/torch/cuda/amp/grad_scaler.py:544 in public method `get_growth_factor`:
D200: One-line docstring should fit on one line with quotes (found 3)
/content/pytorch/torch/cuda/amp/grad_scaler.py:544 in public method `get_growth_factor`:
D401: First line should be in imperative mood (perhaps 'Return', not 'Returns')
/content/pytorch/torch/cuda/amp/grad_scaler.py:550 in public method `set_growth_factor`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/cuda/amp/grad_scaler.py:550 in public method `set_growth_factor`:
D400: First line should end with a period (not ':')
/content/pytorch/torch/cuda/amp/grad_scaler.py:557 in public method `get_backoff_factor`:
D200: One-line docstring should fit on one line with quotes (found 3)
/content/pytorch/torch/cuda/amp/grad_scaler.py:557 in public method `get_backoff_factor`:
D401: First line should be in imperative mood (perhaps 'Return', not 'Returns')
/content/pytorch/torch/cuda/amp/grad_scaler.py:563 in public method `set_backoff_factor`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/cuda/amp/grad_scaler.py:563 in public method `set_backoff_factor`:
D400: First line should end with a period (not ':')
/content/pytorch/torch/cuda/amp/grad_scaler.py:570 in public method `get_growth_interval`:
D200: One-line docstring should fit on one line with quotes (found 3)
/content/pytorch/torch/cuda/amp/grad_scaler.py:570 in public method `get_growth_interval`:
D401: First line should be in imperative mood (perhaps 'Return', not 'Returns')
/content/pytorch/torch/cuda/amp/grad_scaler.py:576 in public method `set_growth_interval`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/cuda/amp/grad_scaler.py:576 in public method `set_growth_interval`:
D400: First line should end with a period (not ':')
/content/pytorch/torch/cuda/amp/grad_scaler.py:592 in public method `is_enabled`:
D200: One-line docstring should fit on one line with quotes (found 3)
/content/pytorch/torch/cuda/amp/grad_scaler.py:592 in public method `is_enabled`:
D401: First line should be in imperative mood (perhaps 'Return', not 'Returns')
/content/pytorch/torch/cuda/amp/grad_scaler.py:598 in public method `state_dict`:
D400: First line should end with a period (not ':')
/content/pytorch/torch/cuda/amp/grad_scaler.py:598 in public method `state_dict`:
D401: First line should be in imperative mood (perhaps 'Return', not 'Returns')
/content/pytorch/torch/cuda/amp/grad_scaler.py:624 in public method `load_state_dict`:
D401: First line should be in imperative mood (perhaps 'Load', not 'Loads')
/content/pytorch/torch/cuda/amp/grad_scaler.py:649 in public method `__getstate__`:
D105: Missing docstring in magic method
/content/pytorch/torch/cuda/amp/grad_scaler.py:665 in public method `__setstate__`:
D105: Missing docstring in magic method
28
```
```
After:
/content/pytorch/torch/cuda/amp/grad_scaler.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/cuda/amp/grad_scaler.py:40 in public class `OptState`:
D101: Missing docstring in public class
/content/pytorch/torch/cuda/amp/grad_scaler.py:117 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/cuda/amp/grad_scaler.py:647 in public method `__getstate__`:
D105: Missing docstring in magic method
/content/pytorch/torch/cuda/amp/grad_scaler.py:663 in public method `__setstate__`:
D105: Missing docstring in magic method
5
```
4) **File: torch/optim/_functional.py**
```
Before:
/content/pytorch/torch/optim/_functional.py:1 at module level:
D400: First line should end with a period (not 'e')
1
```
```
After:
0
```
5) **File: torch/optim/__init__.py**
```
Before:
/content/pytorch/torch/optim/__init__.py:1 at module level:
D205: 1 blank line required between summary line and description (found 0)
1
```
```
After:
0
```
6) **File: torch/optim/lbfgs.py**
```
Before:
/content/pytorch/torch/optim/lbfgs.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/lbfgs.py:185 in public class `LBFGS`:
D205: 1 blank line required between summary line and description (found 0)
/content/pytorch/torch/optim/lbfgs.py:185 in public class `LBFGS`:
D400: First line should end with a period (not 'c')
/content/pytorch/torch/optim/lbfgs.py:215 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/lbfgs.py:285 in public method `step`:
D401: First line should be in imperative mood (perhaps 'Perform', not 'Performs')
5
```
```
After:
/content/pytorch/torch/optim/lbfgs.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/lbfgs.py:217 in public method `__init__`:
D107: Missing docstring in __init__
2
```
7)**File: torch/optim/sparse_adam.py**
```
Before: /content/pytorch/torch/optim/sparse_adam.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/sparse_adam.py:7 in public class `SparseAdam`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/sparse_adam.py:8 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/sparse_adam.py:40 in public method `step`:
D401: First line should be in imperative mood (perhaps 'Perform', not 'Performs')
4
```
```
After:
/content/pytorch/torch/optim/sparse_adam.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/sparse_adam.py:7 in public class `SparseAdam`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/sparse_adam.py:8 in public method `__init__`:
D107: Missing docstring in __init__
3
```
8) **File:torch/optim/adadelta.py**
```
Before:
/content/pytorch/torch/optim/adadelta.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/adadelta.py:11 in public class `Adadelta`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/adadelta.py:12 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/adadelta.py:44 in public method `__setstate__`:
D105: Missing docstring in magic method
/content/pytorch/torch/optim/adadelta.py:82 in public method `step`:
D401: First line should be in imperative mood (perhaps 'Perform', not 'Performs')
/content/pytorch/torch/optim/adadelta.py:193 in public function `adadelta`:
D202: No blank lines allowed after function docstring (found 1)
6
```
```
After:
/content/pytorch/torch/optim/adadelta.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/adadelta.py:11 in public class `Adadelta`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/adadelta.py:12 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/adadelta.py:44 in public method `__setstate__`:
D105: Missing docstring in magic method
4
```
9) **File: torch/optim/adagrad.py**
```
Before:
/content/pytorch/torch/optim/adagrad.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/adagrad.py:11 in public class `Adagrad`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/adagrad.py:12 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/adagrad.py:63 in public method `__setstate__`:
D105: Missing docstring in magic method
/content/pytorch/torch/optim/adagrad.py:78 in public method `share_memory`:
D102: Missing docstring in public method
/content/pytorch/torch/optim/adagrad.py:100 in public method `step`:
D401: First line should be in imperative mood (perhaps 'Perform', not 'Performs')
/content/pytorch/torch/optim/adagrad.py:201 in public function `adagrad`:
D202: No blank lines allowed after function docstring (found 1)
7
```
```
After:
/content/pytorch/torch/optim/adagrad.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/adagrad.py:11 in public class `Adagrad`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/adagrad.py:12 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/adagrad.py:63 in public method `__setstate__`:
D105: Missing docstring in magic method
/content/pytorch/torch/optim/adagrad.py:78 in public method `share_memory`:
D102: Missing docstring in public method
5
```
10) **File: torch/optim/adam.py**
```
Before:
/content/pytorch/torch/optim/adam.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/adam.py:14 in public class `Adam`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/adam.py:15 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/adam.py:65 in public method `__setstate__`:
D105: Missing docstring in magic method
/content/pytorch/torch/optim/adam.py:135 in public method `step`:
D401: First line should be in imperative mood (perhaps 'Perform', not 'Performs')
/content/pytorch/torch/optim/adam.py:281 in public function `adam`:
D202: No blank lines allowed after function docstring (found 1)
/content/pytorch/torch/optim/adam.py:281 in public function `adam`:
D205: 1 blank line required between summary line and description (found 0)
7
```
```
After:
/content/pytorch/torch/optim/adam.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/adam.py:14 in public class `Adam`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/adam.py:15 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/adam.py:65 in public method `__setstate__`:
D105: Missing docstring in magic method
4
```
11) **File: torch/optim/adamax.py**
```
Before:
/content/pytorch/torch/optim/adamax.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/adamax.py:12 in public class `Adamax`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/adamax.py:13 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/adamax.py:47 in public method `__setstate__`:
D105: Missing docstring in magic method
/content/pytorch/torch/optim/adamax.py:91 in public method `step`:
D401: First line should be in imperative mood (perhaps 'Perform', not 'Performs')
/content/pytorch/torch/optim/adamax.py:203 in public function `adamax`:
D202: No blank lines allowed after function docstring (found 1)
6
```
```
After:
/content/pytorch/torch/optim/adamax.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/adamax.py:12 in public class `Adamax`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/adamax.py:13 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/adamax.py:47 in public method `__setstate__`:
D105: Missing docstring in magic method
4
```
12) **File: torch/optim/adamw.py**
```
Before:
/content/pytorch/torch/optim/adamw.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/adamw.py:12 in public class `AdamW`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/adamw.py:13 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/adamw.py:73 in public method `__setstate__`:
D105: Missing docstring in magic method
/content/pytorch/torch/optim/adamw.py:153 in public method `step`:
D401: First line should be in imperative mood (perhaps 'Perform', not 'Performs')
/content/pytorch/torch/optim/adamw.py:304 in public function `adamw`:
D202: No blank lines allowed after function docstring (found 1)
6
```
```
After:
/content/pytorch/torch/optim/adamw.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/adamw.py:12 in public class `AdamW`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/adamw.py:13 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/adamw.py:73 in public method `__setstate__`:
D105: Missing docstring in magic method
4
```
13) **File: torch/optim/asgd.py**
```
Before:
/content/pytorch/torch/optim/asgd.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/asgd.py:17 in public class `ASGD`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/asgd.py:18 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/asgd.py:52 in public method `__setstate__`:
D105: Missing docstring in magic method
/content/pytorch/torch/optim/asgd.py:107 in public method `step`:
D401: First line should be in imperative mood (perhaps 'Perform', not 'Performs')
/content/pytorch/torch/optim/asgd.py:195 in public function `asgd`:
D202: No blank lines allowed after function docstring (found 1)
6
```
```
After:
/content/pytorch/torch/optim/asgd.py:1 at module level:
D100: Missing docstring in public module
/content/pytorch/torch/optim/asgd.py:17 in public class `ASGD`:
D101: Missing docstring in public class
/content/pytorch/torch/optim/asgd.py:18 in public method `__init__`:
D107: Missing docstring in __init__
/content/pytorch/torch/optim/asgd.py:52 in public method `__setstate__`:
D105: Missing docstring in magic method
4
```
Resolved docstring errors as listed. I initially changed in the main branch of forked repo which caused changes to appear in my PR to other issue. I have fixed that and hope this PR won't have any conflicts.
Kindly review @svekars @jbschlosser.
In case of any other issues please let me know. Thanks!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/112964
Approved by: https://github.com/kit1980
Adam part of: https://github.com/pytorch/pytorch/issues/110506
TODO:
- If this approach is validated as a good one, it an also be applied to all other optimizers which convert `complex` via list comprehensions
### Results:
`NUM_PARAMS=200, foreach=True`
- main: dynamo: 43s, inductor: 31s, total: 74s
- this PR: dynamo: 3.5s, inductor: 30s, total: 34s (dynamo speedup: 12.3x, overall speedup: 34s, 2.1x)
`NUM_PARAMS=1000, foreach=True, has_complex shortcut`:
```
<class 'torch.optim.adam.Adam'> {'lr': 0.01, 'foreach': True} torch.float32 TorchDynamo compilation metrics:
Function Runtimes (s)
------------------------------------ -------------------------------
_compile.<locals>.compile_inner 0.0329, 50.0806, 0.0041
OutputGraph.call_user_compiler 44.9924
```
`NUM_PARAMS=1000, foreach=True`:
```
<class 'torch.optim.adam.Adam'> {'lr': 0.01, 'foreach': True} torch.float32 TorchDynamo compilation metrics:
Function Runtimes (s)
------------------------------------ -------------------------------
_compile.<locals>.compile_inner 0.0389, 58.6069, 0.0043
OutputGraph.call_user_compiler 44.1425
```
### Discussion
- `has_complex` shortcut provides additional 2x dynamo speedup. It is not necessary to achieve a significant overall speedup.
CC: @janeyx99 @mlazos
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110607
Approved by: https://github.com/janeyx99, https://github.com/lezcano
Starts addressing #106802
This PR also conveniently does some BE:
- Fixes a bug in adamw where we use amsgrad instead of per group amsgrad
- Brings the impls of adamw and adam closer to correctness and to each other
I couldn't fully remove the .pyi's because mypy was going to complain about the entire files which scared me and shouldn't go in this PR anyway.
Test plan:
- Add tests to ensure that lr could be passed as a Tensor
- Did some profiling of the below code (runs 1k iterations of step for Adam)
```
import torch
from torch.testing._internal.common_utils import TestCase
param = torch.rand(2, 3, dtype=torch.float, device='cuda:0', requires_grad=True)
param.grad = torch.rand_like(param)
lr = torch.tensor(.001, device='cuda:0')
opt = torch.optim.Adam([param], lr=lr, fused=True)
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
]
) as p:
for _ in range(1000):
opt.step()
print(p.key_averages().table(sort_by="cpu_time_total"))
```
Before my change:
<img width="1381" alt="image" src="https://github.com/pytorch/pytorch/assets/31798555/cfc5175a-0f41-4829-941f-342554f3b152">
After my change (notice there are no d2h syncs and the CPU time is lower!):

Next steps long term:
- have all capturable foreach + forloop impls in Adam(W) handle tensor LR
- have all capturable impls handle tensor LR
- have all impls handle tensor LR
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106916
Approved by: https://github.com/albanD
There are extra graph compilations on XLA when beta{1,2} ** step get too small. This PR addresses this issue by making the `capturable` interface enabled for XLA, as well as switching to `torch.float_power` which preserves the same behaviour as the non-capturable flow on XLA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/102858
Approved by: https://github.com/janeyx99, https://github.com/albanD
The goal is to fix the problem from https://github.com/pytorch/pytorch/pull/102858
The full error this used to raise was :
```
2023-06-27T15:12:15.0663239Z File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/optim/adamw.py", line 409, in _single_tensor_adamw
2023-06-27T15:12:15.0663699Z bias_correction1 = 1 - beta1 ** step
2023-06-27T15:12:15.0664200Z File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_tensor.py", line 40, in wrapped
2023-06-27T15:12:15.0664547Z return f(*args, **kwargs)
2023-06-27T15:12:15.0665031Z File "/opt/conda/envs/py_3.10/lib/python3.10/site-packages/torch/_tensor.py", line 882, in __rpow__
2023-06-27T15:12:15.0665483Z return torch.tensor(other, dtype=dtype, device=self.device) ** self
2023-06-27T15:12:15.0665899Z RuntimeError: CUDA error: operation not permitted when stream is capturing
2023-06-27T15:12:15.0666401Z CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
```
This pow issue was fixed in https://github.com/pytorch/pytorch/pull/104264 and so this problem should be solvable now.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104254
Approved by: https://github.com/janeyx99, https://github.com/aws-murandoo
Starts addressing https://github.com/pytorch/pytorch/issues/97712 by
- Minimizing intermediates usage for foreach Adam
- Document the extra memory usage
- Add comments within the code for clarity now that we reuse intermediates
- Add tests
- Did some refactoring
Next steps involve doing this for all other foreach implementations. Note that even after this change, foreach mem usage will be higher than forloop due to the fact that we have a minimum budget of 1 intermediate (to not muddle the input values) and the intermediate will be larger. For capturable, the memory usage is higher due to moving more tensors to CUDA.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104780
Approved by: https://github.com/albanD
This is a reland of https://github.com/pytorch/pytorch/pull/100007 with a build fix for Windows debug builds.
`at::native::ParamsHash` only works on structs with standard layout, but `std::string` isn't one in Visual C++ debug builds, which one can easily verified by running something like:
```cpp
#define _DEBUG
#include <type_traits>
#include <string>
static_assert(std::is_standard_layout_v<std::string>, "Oh noes");
```
If above conditon is not met, instead of printing a static_assert output, VC++ raises a very cryptic compilation errors, see https://github.com/pytorch/pytorch/pull/100007#discussion_r1227116292 for more detail.
Also, using `std::hash` for string should result in a faster hash function.
(cherry picked from commit 74b7a6c75e)
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 5914771</samp>
This pull request introduces a new function `_group_tensors_by_device_and_dtype` that can group tensors by their device and dtype, and updates the `foreach` utilities and several optimizers to use this function. The goal is to improve the performance, readability, and compatibility of the code that handles tensors with different properties. The pull request also adds a test case and type annotations for the new function, and some error checks for the `fused` argument in Adam and AdamW.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/103912
Approved by: https://github.com/janeyx99
Fixes#95781.
The cause seems to be that the current implementation doesn't correctly pass `found_inf` when `grad_scale` is `None`. Therefore parameters can get mistakenly updated by gradients whose some elements are invalid, i.e. nan or inf.
Related #94060
I forgot about this wrong handling after #94344
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95847
Approved by: https://github.com/janeyx99
Big OOP correction continued. Also added a test this time to verify the defaulting was as expected.
The key here is realizing that the grouping for foreach already assumes that the non-param tensorlists follow suit in dtype and device, so it is too narrow to check that _all_ tensors were on CUDA. The main leeway this allowed was state_steps, which are sometimes cpu tensors. Since foreach _can_ handle cpu tensors, this should not introduce breakage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95820
Approved by: https://github.com/albanD
Rolling back the default change for Adam and rectifying the docs to reflect that AdamW never defaulted to fused.
Since our fused implementations are relatively newer, let's give them a longer bake-in time before flipping the switch for every user.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95241
Approved by: https://github.com/ngimel
This allows it so that ONLY when the users don't set anything for foreach or fused do we switch the default and cascades adam so that we default to fused, then foreach, then single-tensor.
To clarify:
* if the user puts True in foreach _only_, it will run the foreach implementation.
* if the user puts True in fused _only_, it will run the fused implementation.
* if the user puts True in foreach AND for fused, it will run the fused implementation.
And:
* if the user puts False in foreach _only_, it will run the single tensor implementation.
* if the user puts False in fused _only_, it will still run the single tensor implementation.
* if the user puts False in foreach AND for fused, it will run the single tensor implementation.
I also didn't trust myself that much with the helper function, so I ran some local asserts on _default_to_fused_or_foreach. The only point left to really test is the type(p) -- torch.Tensor but I think the distributed tests will catch that in CI.
```
cuda_only_fp_list = [
torch.rand((1, 2), device="cuda", dtype=torch.float32),
torch.rand((1, 2), device="cuda", dtype=torch.float64),
torch.rand((1, 2), device="cuda", dtype=torch.float16),
torch.rand((1, 2), device="cuda", dtype=torch.bfloat16),
]
cuda_only_int_list = [
torch.randint(1024, (1, 2), device="cuda", dtype=torch.int64),
]
cpu_list = [
torch.rand((1, 2), device="cpu", dtype=torch.float32),
torch.rand((1, 2), device="cpu", dtype=torch.float64),
torch.rand((1, 2), device="cpu", dtype=torch.float16),
]
none_list = [None]
# differentiable should always make it return false for both
assert _default_to_fused_or_foreach([cuda_only_fp_list], True, True) == (False, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list], True, False) == (False, False)
# cpu lists should always make it return false for both
assert _default_to_fused_or_foreach([cuda_only_fp_list, cpu_list], False, True) == (False, False)
assert _default_to_fused_or_foreach([cpu_list], False, True) == (False, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list, cpu_list], False, False) == (False, False)
assert _default_to_fused_or_foreach([cpu_list], False, False) == (False, False)
# has fused triggers correctly
assert _default_to_fused_or_foreach([cuda_only_fp_list], False, True) == (True, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list], False, False) == (False, True)
# ints always goes to foreach
assert _default_to_fused_or_foreach([cuda_only_fp_list, cuda_only_int_list], False, True) == (False, True)
assert _default_to_fused_or_foreach([cuda_only_fp_list, cuda_only_int_list], False, False) == (False, True)
# Nones don't error
assert _default_to_fused_or_foreach([cuda_only_fp_list, none_list], False, True) == (True, False)
assert _default_to_fused_or_foreach([cuda_only_fp_list, cuda_only_int_list, none_list], False, True) == (False, True)
assert _default_to_fused_or_foreach([none_list], False, True) == (True, False)
assert _default_to_fused_or_foreach([none_list], False, False) == (False, True)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93184
Approved by: https://github.com/albanD
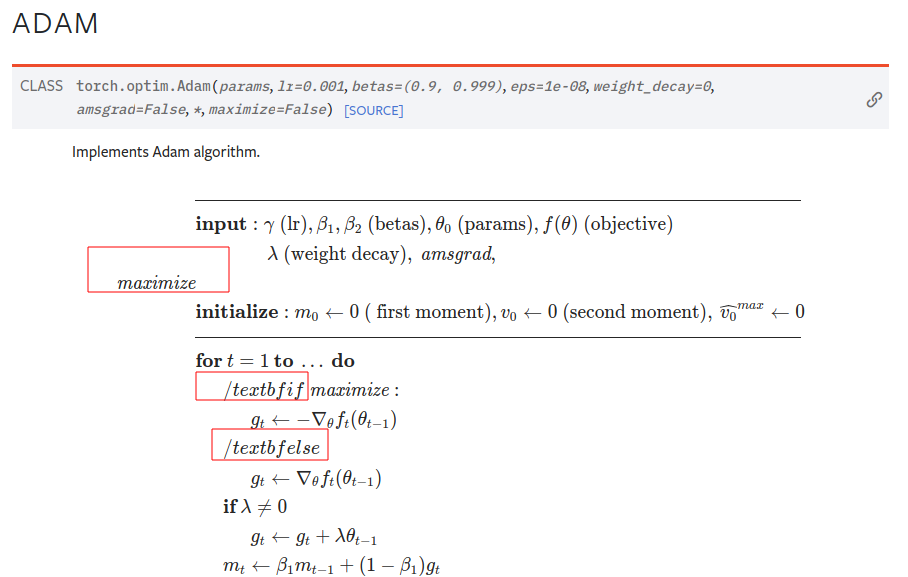
@mlazos: skips `item()` calls if compiling with dynamo, by defining a helper function `_get_value` which either returns the result of `.item()` or the scalar cpu tensor if compiling with dynamo. This was done because removing `item()` calls significantly regresses eager perf. Additionally, `_dispatch_sqrt` calls the appropriate sqrt function (math.sqrt, or torch.sqrt).
Fixes https://github.com/pytorch/torchdynamo/issues/1083
This PR will no longer be needed once symint support is default.
This PR closes all remaining graph breaks in the optimizers (!!)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88173
Approved by: https://github.com/albanD
### Description
Across PyTorch's docstrings, both `callable` and `Callable` for variable types. The Callable should be capitalized as we are referring to the `Callable` type, and not the Python `callable()` function.
### Testing
There shouldn't be any testing required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82487
Approved by: https://github.com/albanD
Generator comprehensions with any/all are less verbose and potentially help to save memory/CPU : https://eklitzke.org/generator-comprehensions-and-using-any-and-all-in-python
To make JIT work with this change, I added code to convert GeneratorExp to ListComp. So the whole PR is basically NoOp for JIT, but potentially memory and speed improvement for eager mode.
Also I removed a test from test/jit/test_parametrization.py. The test was bad and had a TODO to actually implement and just tested that UnsupportedNodeError is thrown, and with GeneratorExp support a different error would be thrown.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78142
Approved by: https://github.com/malfet, https://github.com/albanD
This is causing issues if the user has the step on cuda for a good reason.
These assert prevents code that used to run just fine to fail.
Note that this is a pretty bad thing to do for performance though so it is ok to try and push users away from doing it.
For the 1.12.1 milestone: this is not asking for a dot release to fix this (as this is bad practice anyways). But it would be a great thing to add if we do one: it is very low risk and will prevent breakage for users.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80222
Approved by: https://github.com/jbschlosser, https://github.com/ngimel
Near term fix for https://github.com/pytorch/pytorch/issues/76368.
Q. Why does the user need to request `capturable=True` in the optimizer constructor? Why can't capture safety be completely automatic?
A. We need to set up capture-safe (device-side) state variables before capture. If we don't, and step() internally detects capture is underway, it's too late: the best we could do is create a device state variable and copy the current CPU value into it, which is not something we want baked into the graph.
Q. Ok, why not just do the capture-safe approach with device-side state variables all the time?
A. It incurs several more kernel launches per parameter, which could really add up and regress cpu overhead for ungraphed step()s. If the optimizer won't be captured, we should allow step() to stick with its current cpu-side state handling.
Q. But cuda RNG is a stateful thing that maintains its state on the cpu outside of capture and replay, and we capture it automatically. Why can't we do the same thing here?
A. The graph object can handle RNG generator increments because its capture_begin, capture_end, and replay() methods can see and access generator object. But the graph object has no explicit knowledge of or access to optimizer steps in its capture scope. We could let the user tell the graph object what optimizers will be stepped in its scope, ie something like
```python
graph.will_use_optimizer(opt)
graph.capture_begin()
...
```
but that seems clunkier than an optimizer constructor arg.
I'm open to other ideas, but right now I think constructor arg is necessary and the least bad approach.
Long term, https://github.com/pytorch/pytorch/issues/71274 is a better fix.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77862
Approved by: https://github.com/ezyang
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71333
Updated
- Adagrad
- Adamax
- Adam
- AdamW
- RAdam
make multi_tensor functionals take `state_steps: List[Tensor]` instead of taking `states: List[Dict]`
make `state_steps: List[int]s -> state_steps:List[Tensor]` where each is a Singleton tensor so step can be updated within the functional
(NAdam and ASGD) were updated in separate diffs to fold their handling of state into the functionals
Test Plan: Imported from OSS
Reviewed By: anjali411
Differential Revision: D33767872
Pulled By: mikaylagawarecki
fbshipit-source-id: 9baa7cafb6375eab839917df9287c65a437891f2
(cherry picked from commit 831c02b3d0)
Summary:
Solves the next most important use case in https://github.com/pytorch/pytorch/issues/68052.
I have kept the style as close to that in SGD as seemed reasonable, given the slight differences in their internal implementations.
All feedback welcome!
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68164
Reviewed By: VitalyFedyunin
Differential Revision: D32994129
Pulled By: albanD
fbshipit-source-id: 65c57c3f3dbbd3e3e5338d51def54482503e8850
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/52944
This fix the bug introduced during refactoring optimizers https://github.com/pytorch/pytorch/pull/50411. When all parameters have no grads, we should still allows `beta` like hyper params to be defined.
Reviewed By: ngimel
Differential Revision: D26699827
fbshipit-source-id: 8a7074127704c7a4a1fbc17d48a81e23a649f280
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51316
Make optim functional API be private until we release with beta
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D26213469
fbshipit-source-id: b0fd001a8362ec1c152250bcd57c7205ed893107
Summary:
Adam and AdamW are missing parameter validation for weight_decay. Other optimisers have this check present.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33126
Differential Revision: D19860366
Pulled By: vincentqb
fbshipit-source-id: 286d7dc90e2f4ccf6540638286d2fe17939648fc
Summary:
Apply weight decay for Adam in-place instead of via copy.
Synced offline with soumith , who mentioned that it should be OK. This is also consistent with other optimizers, e.g. eee01731a5/torch/optim/sgd.py (L93)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/12107
Reviewed By: soumith
Differential Revision: D10071787
Pulled By: jma127
fbshipit-source-id: 5fd7939c79039693b225c44c4c80450923b8d673
Summary:
Minor addition to the docstring of `torch.nn.optim.Adam`, adding the default argument description for the `amsgrad` argument to the docstring for concistency.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/9971
Differential Revision: D9040820
Pulled By: soumith
fbshipit-source-id: 168744a6bb0d1422331beffd7e694b9d6f61900c
Here's the command I used to invoke autopep8 (in parallel!):
git ls-files | grep '\.py$' | xargs -n1 -P`nproc` autopep8 -i
Several rules are ignored in setup.cfg. The goal is to let autopep8
handle everything which it can handle safely, and to disable any rules
which are tricky or controversial to address. We may want to come back
and re-enable some of these rules later, but I'm trying to make this
patch as safe as possible.
Also configures flake8 to match pep8's behavior.
Also configures TravisCI to check the whole project for lint.
{kind=link}
{kind=link}
{kind=link}
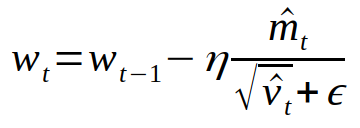{kind=link}
{kind=link}