Summary:
Switching pytorch android to use fbjni from prefab dependencies
Bumping version of fbjni to 0.2.2
soloader version to 0.10.1
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55066
Reviewed By: dreiss
Differential Revision: D27469727
Pulled By: IvanKobzarev
fbshipit-source-id: 2ab22879e81c9f2acf56807c6a133b0ca20bb40a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53567
Updating gradle to version 6.8.3
Proper zip was uploaded to aws.
Successful CI check: https://github.com/pytorch/pytorch/pull/53619
Test Plan: Imported from OSS
Reviewed By: dreiss
Differential Revision: D26928885
Pulled By: IvanKobzarev
fbshipit-source-id: b1081052967d9080cd6934fd48c4dbe933630e49
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51419
## Summary
1. Add an option `BUILD_LITE_INTERPRETER` in `caffe2/CMakeLists.txt` and set `OFF` as default.
2. Update 'build_android.sh' with an argument to swtich `BUILD_LITE_INTERPRETER`, 'OFF' as default.
3. Add a mini demo app `lite_interpreter_demo` linked with `libtorch` library, which can be used for quick test.
## Test Plan
Built lite interpreter version of libtorch and test with Image Segmentation demo app ([android version](https://github.com/pytorch/android-demo-app/tree/master/ImageSegmentation)/[ios version](https://github.com/pytorch/ios-demo-app/tree/master/ImageSegmentation))
### Android
1. **Prepare model**: Prepare the lite interpreter version of model by run the script below to generate the scripted model `deeplabv3_scripted.pt` and `deeplabv3_scripted.ptl`
```
import torch
model = torch.hub.load('pytorch/vision:v0.7.0', 'deeplabv3_resnet50', pretrained=True)
model.eval()
scripted_module = torch.jit.script(model)
# Export full jit version model (not compatible lite interpreter), leave it here for comparison
scripted_module.save("deeplabv3_scripted.pt")
# Export lite interpreter version model (compatible with lite interpreter)
scripted_module._save_for_lite_interpreter("deeplabv3_scripted.ptl")
```
2. **Build libtorch lite for android**: Build libtorch for android for all 4 android abis (armeabi-v7a, arm64-v8a, x86, x86_64) `BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh`. This pr is tested on Pixel 4 emulator with x86, so use cmd `BUILD_LITE_INTERPRETER=1 ./scripts/build_pytorch_android.sh x86` to specify abi to save built time. After the build finish, it will show the library path:
```
...
BUILD SUCCESSFUL in 55s
134 actionable tasks: 22 executed, 112 up-to-date
+ find /Users/chenlai/pytorch/android -type f -name '*aar'
+ xargs ls -lah
-rw-r--r-- 1 chenlai staff 13M Feb 11 11:48 /Users/chenlai/pytorch/android/pytorch_android/build/outputs/aar/pytorch_android-release.aar
-rw-r--r-- 1 chenlai staff 36K Feb 9 16:45 /Users/chenlai/pytorch/android/pytorch_android_torchvision/build/outputs/aar/pytorch_android_torchvision-release.aar
```
3. **Use the PyTorch Android libraries built from source in the ImageSegmentation app**: Create a folder 'libs' in the path, the path from repository root will be `ImageSegmentation/app/libs`. Copy `pytorch_android-release` to the path `ImageSegmentation/app/libs/pytorch_android-release.aar`. Copy 'pytorch_android_torchvision` (downloaded from [here](https://oss.sonatype.org/#nexus-search;quick~torchvision_android)) to the path `ImageSegmentation/app/libs/pytorch_android_torchvision.aar` Update the `dependencies` part of `ImageSegmentation/app/build.gradle` to
```
dependencies {
implementation 'androidx.appcompat:appcompat:1.2.0'
implementation 'androidx.constraintlayout:constraintlayout:2.0.2'
testImplementation 'junit:junit:4.12'
androidTestImplementation 'androidx.test.ext:junit:1.1.2'
androidTestImplementation 'androidx.test.espresso:espresso-core:3.3.0'
implementation(name:'pytorch_android-release', ext:'aar')
implementation(name:'pytorch_android_torchvision', ext:'aar')
implementation 'com.android.support:appcompat-v7:28.0.0'
implementation 'com.facebook.fbjni:fbjni-java-only:0.0.3'
}
```
Update `allprojects` part in `ImageSegmentation/build.gradle` to
```
allprojects {
repositories {
google()
jcenter()
flatDir {
dirs 'libs'
}
}
}
```
4. **Update model loader api**: Update `ImageSegmentation/app/src/main/java/org/pytorch/imagesegmentation/MainActivity.java` by
4.1 Add new import: `import org.pytorch.LiteModuleLoader;`
4.2 Replace the way to load pytorch lite model
```
// mModule = Module.load(MainActivity.assetFilePath(getApplicationContext(), "deeplabv3_scripted.pt"));
mModule = LiteModuleLoader.load(MainActivity.assetFilePath(getApplicationContext(), "deeplabv3_scripted.ptl"));
```
5. **Test app**: Build and run the ImageSegmentation app in Android Studio,

### iOS
1. **Prepare model**: Same as Android.
2. **Build libtorch lite for ios** `BUILD_PYTORCH_MOBILE=1 IOS_PLATFORM=SIMULATOR BUILD_LITE_INTERPRETER=1 ./scripts/build_ios.sh`
3. **Remove Cocoapods from the project**: run `pod deintegrate`
4. **Link ImageSegmentation demo app with the custom built library**:
Open your project in XCode, go to your project Target’s **Build Phases - Link Binaries With Libraries**, click the **+** sign and add all the library files located in `build_ios/install/lib`. Navigate to the project **Build Settings**, set the value **Header Search Paths** to `build_ios/install/include` and **Library Search Paths** to `build_ios/install/lib`.
In the build settings, search for **other linker flags**. Add a custom linker flag below
```
-all_load
```
Finally, disable bitcode for your target by selecting the Build Settings, searching for Enable Bitcode, and set the value to No.
**
5. Update library and api**
5.1 Update `TorchModule.mm``
To use the custom built libraries the project, replace `#import <LibTorch/LibTorch.h>` (in `TorchModule.mm`) which is needed when using LibTorch via Cocoapods with the code below:
```
//#import <LibTorch/LibTorch.h>
#include "ATen/ATen.h"
#include "caffe2/core/timer.h"
#include "caffe2/utils/string_utils.h"
#include "torch/csrc/autograd/grad_mode.h"
#include "torch/script.h"
#include <torch/csrc/jit/mobile/function.h>
#include <torch/csrc/jit/mobile/import.h>
#include <torch/csrc/jit/mobile/interpreter.h>
#include <torch/csrc/jit/mobile/module.h>
#include <torch/csrc/jit/mobile/observer.h>
```
5.2 Update `ViewController.swift`
```
// if let filePath = Bundle.main.path(forResource:
// "deeplabv3_scripted", ofType: "pt"),
// let module = TorchModule(fileAtPath: filePath) {
// return module
// } else {
// fatalError("Can't find the model file!")
// }
if let filePath = Bundle.main.path(forResource:
"deeplabv3_scripted", ofType: "ptl"),
let module = TorchModule(fileAtPath: filePath) {
return module
} else {
fatalError("Can't find the model file!")
}
```
### Unit test
Add `test/cpp/lite_interpreter`, with one unit test `test_cores.cpp` and a light model `sequence.ptl` to test `_load_for_mobile()`, `bc.find_method()` and `bc.forward()` functions.
### Size:
**With the change:**
Android:
x86: `pytorch_android-release.aar` (**13.8 MB**)
IOS:
`pytorch/build_ios/install/lib` (lib: **66 MB**):
```
(base) chenlai@chenlai-mp lib % ls -lh
total 135016
-rw-r--r-- 1 chenlai staff 3.3M Feb 15 20:45 libXNNPACK.a
-rw-r--r-- 1 chenlai staff 965K Feb 15 20:45 libc10.a
-rw-r--r-- 1 chenlai staff 4.6K Feb 15 20:45 libclog.a
-rw-r--r-- 1 chenlai staff 42K Feb 15 20:45 libcpuinfo.a
-rw-r--r-- 1 chenlai staff 39K Feb 15 20:45 libcpuinfo_internals.a
-rw-r--r-- 1 chenlai staff 1.5M Feb 15 20:45 libeigen_blas.a
-rw-r--r-- 1 chenlai staff 148K Feb 15 20:45 libfmt.a
-rw-r--r-- 1 chenlai staff 44K Feb 15 20:45 libpthreadpool.a
-rw-r--r-- 1 chenlai staff 166K Feb 15 20:45 libpytorch_qnnpack.a
-rw-r--r-- 1 chenlai staff 384B Feb 15 21:19 libtorch.a
-rw-r--r-- 1 chenlai staff **60M** Feb 15 20:47 libtorch_cpu.a
```
`pytorch/build_ios/install`:
```
(base) chenlai@chenlai-mp install % du -sh *
14M include
66M lib
2.8M share
```
**Master (baseline):**
Android:
x86: `pytorch_android-release.aar` (**16.2 MB**)
IOS:
`pytorch/build_ios/install/lib` (lib: **84 MB**):
```
(base) chenlai@chenlai-mp lib % ls -lh
total 172032
-rw-r--r-- 1 chenlai staff 3.3M Feb 17 22:18 libXNNPACK.a
-rw-r--r-- 1 chenlai staff 969K Feb 17 22:18 libc10.a
-rw-r--r-- 1 chenlai staff 4.6K Feb 17 22:18 libclog.a
-rw-r--r-- 1 chenlai staff 42K Feb 17 22:18 libcpuinfo.a
-rw-r--r-- 1 chenlai staff 1.5M Feb 17 22:18 libeigen_blas.a
-rw-r--r-- 1 chenlai staff 44K Feb 17 22:18 libpthreadpool.a
-rw-r--r-- 1 chenlai staff 166K Feb 17 22:18 libpytorch_qnnpack.a
-rw-r--r-- 1 chenlai staff 384B Feb 17 22:19 libtorch.a
-rw-r--r-- 1 chenlai staff 78M Feb 17 22:19 libtorch_cpu.a
```
`pytorch/build_ios/install`:
```
(base) chenlai@chenlai-mp install % du -sh *
14M include
84M lib
2.8M share
```
Test Plan: Imported from OSS
Reviewed By: iseeyuan
Differential Revision: D26518778
Pulled By: cccclai
fbshipit-source-id: 4503ffa1f150ecc309ed39fb0549e8bd046a3f9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48620
In preparation for storing bare function pointer (8 bytes)
instead of std::function (32 bytes).
ghstack-source-id: 118568242
Test Plan: CI
Reviewed By: ezyang
Differential Revision: D25132183
fbshipit-source-id: 3790cfb5d98479a46cf665b14eb0041a872c13da
Summary:
### Java, CPP
Introducing additional parameter `device` to LiteModuleLoader to specify device on which the `forward` will work.
On the java side this is enum that contains CPU and VULKAN, passing as jint to jni side and storing it as a member field on the same level as module.
On pytorch_jni_lite.cpp - for all input tensors converting them to vulkan.
On pytorch_jni_common.cpp (also goes to OSS) - if result Tensor is not cpu - call cpu. (Not Cpu at the moment is only Vulkan).
### BUCK
Introducing `pytorch_jni_lite_with_vulkan` target, that depends on `pytorch_jni_lite_with_vulkan` and adds `aten_vulkan`
In that case `pytorch_jni_lite_with_vulkan` can be used along with `pytorch_jni_lite_with_vulkan`.
Test Plan:
After the following diff with aidemo segmentation:
```
buck install -r aidemos-android
```
{F296224521}
Reviewed By: dreiss
Differential Revision: D23198335
fbshipit-source-id: 95328924e398901d76718c4d828f96e112dfa1b0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/44202
In preparation for changing mobile run_method() to be variadic, this diff:
* Implements get_method() for mobile Module, which is similar to find_method but expects the method to exist.
* Replaces calls to the current nonvariadic implementation of run_method() by calling get_method() and then invoking the operator() overload on Method objects.
ghstack-source-id: 111848222
Test Plan: CI, and all the unit tests which currently contain run_method that are being changed.
Reviewed By: iseeyuan
Differential Revision: D23436351
fbshipit-source-id: 4655ed7182d8b6f111645d69798465879b67a577
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40785
The main goal of this change is to support creating Tensors specifying blob in NHWC (ChannelsLast) format.
ChannelsLast is supported only for 4-dim tensors, this is enforced on LibTorch side, I have not added asserts on java side in case that this limitation will be changed in future and not to have double asserts.
Additional changes in `aten/src/ATen/templates/Functions.h`:
`from_blob` creates `at::empty({0}, options)` tensor first and sets it Storage with sizes and strides afterwards.
But as ChannelsLast is only for 4-dim tensors - it fails on that creation, as dim==1.
I've added `zero_sizes()` function that returns `{0, 0, 0, 0}` for ChannelsLast and ChannelsLast3d.
Test Plan: Imported from OSS
Reviewed By: dreiss
Differential Revision: D22396244
Pulled By: IvanKobzarev
fbshipit-source-id: 02582d748a554e0f859aefe71cd2c1e321fb8979
Summary:
These were added accidentally (probably by an IDE) during a refactor.
These files have always been Open Source.
Test Plan: CI
Reviewed By: xcheng16
Differential Revision: D23250761
fbshipit-source-id: 4974430c0e28dd3269424d38edb36f4f71508157
Summary:
1. Modularize some bzl files to break circular buck load
2. Use query-based on instrumentation_tests
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: kwanmacher
Differential Revision: D22188728
fbshipit-source-id: affbabd333c51c8b1549af6602c6bb79fabb7236
Summary:
This re-applies D21232894 (b9d3869df3) and D22162524, plus updates jni_deps in a few places
to avoid breaking host JNI tests.
Test Plan: `buck test @//fbandroid/mode/server //fbandroid/instrumentation_tests/com/facebook/caffe2:host-test`
Reviewed By: xcheng16
Differential Revision: D22199952
fbshipit-source-id: df13eef39c01738637ae8cf7f581d6ccc88d37d5
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/40442
Problem:
Nightly builds do not include libtorch headers as local build.
The reason is that on docker images path is different than local path when building with `scripts/build_pytorch_android.sh`
Solution:
Introducing gradle property to be able to specify it and add its specification to gradle build job and snapshots publishing job which run on the same docker image.
Test:
ci-all jobs check https://github.com/pytorch/pytorch/pull/40443
checking that gradle build will result with headers inside aar
Test Plan: Imported from OSS
Differential Revision: D22190955
Pulled By: IvanKobzarev
fbshipit-source-id: 9379458d8ab024ee991ca205a573c21d649e5f8a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37243
*** Why ***
As it stands, we have two thread pool solutions concurrently in use in PyTorch mobile: (1) the open source pthreadpool library under third_party, and (2) Caffe2's implementation of pthreadpool under caffe2/utils/threadpool. Since the primary use-case of the latter has been to act as a drop-in replacement for the third party version so as to enable integration and usage from within NNPACK and QNNPACK, Caffe2's implementation is intentionally written to the exact same interface as the third party version.
The original argument in favor of C2's implementation has been improved performance as a result of using spin locks, as opposed to relinquishing the thread's time slot and putting it to sleep - a less expensive operation up to a point. That seems to have given C2's implementation the upper hand in performance, hence justifying the added maintenance complexity, until the third party version improved in parallel surpassing the efficiency of C2's implementation as I have verified in benchmarks. With that advantage gone, there is no reason to continue using C2's implementation in PyTorch mobile either from the perspective of performance or code hygiene. As a matter of fact, there is considerable performance benefit to be had as a result of using the third party version as it currently stands.
This is a tricky change though, mainly because in order to avoid potential performance regressions, of which I have witnessed none but just in abundance of caution, we have decided to continue using the internal C2's implementation whenever building for Caffe2. Again, this is mainly to avoid potential performance regressions in production C2 use cases even if doing so results in reduced performance as far as I can tell.
So to summarize, today, and as it currently stands, we are using C2's implementation for (1) NNPACK, (2) PyTorch QNNPACK, and (3) ATen parallel_for on mobile builds, while using the third party version of pthreadpool for XNNPACK as XNNPACK does not provide any build options to link against an external implementation unlike NNPACK and QNNPACK do.
The goal of this PR then, is to unify all usage on mobile to the third party implementation both for improved performance and better code hygiene. This applies to PyTorch's use of NNPACK, QNNPACK, XNNPACK, and mobile's implementation of ATen parallel_for, all getting routed to the
exact same third party implementation in this PR.
Considering that NNPACK, QNNPACK, and XNNPACK are not mobile specific, these benefits carry over to non-mobile builds of PyTorch (but not Caffe2) as well. The implementation of ATen parallel_for on non-mobile builds remains unchanged.
*** How ***
This is where things get tricky.
A good deal of the build system complexity in this PR arises from our desire to maintain C2's implementation intact for C2's use.
pthreadpool is a C library with no concept of namespaces, which means two copies of the library cannot exist in the same binary or symbol collision will occur violating ODR. This means that somehow, and based on some condition, we must decide on the choice of a pthreadpool implementation. In practice, this has become more complicated as a result of all the possible combinations that USE_NNPACK, USE_QNNPACK, USE_PYTORCH_QNNPACK, USE_XNNPACK, USE_SYSTEM_XNNPACK, USE_SYSTEM_PTHREADPOOL and other variables can result in. Having said that, I have done my best in this PR to surgically cut through this complexity in a way that minimizes the side effects, considering the significance of the performance we are leaving on the table, yet, as a result of this combinatorial explosion explained above I cannot guarantee that every single combination will work as expected on the first try. I am heavily relying on CI to find any issues as local testing can only go that far.
Having said that, this PR provides a simple non mobile-specific C++ thread pool implementation on top of pthreadpool, namely caffe2::PThreadPool that automatically routes to C2's implementation or the third party version depending on the build configuration. This simplifies the logic at the cost of pushing the complexity to the build scripts. From there on, this thread pool is used in aten parallel_for, and NNPACK and family, again, routing all usage of threading to C2 or third party pthreadpool depending on the build configuration.
When it is all said or done, the layering will look like this:
a) aten::parallel_for, uses
b) caffe2::PThreadPool, which uses
c) pthreadpool C API, which delegates to
c-1) third_party implementation of pthreadpool if that's what the build has requested, and the rabbit hole ends here.
c-2) C2's implementation of pthreadpool if that's what the build has requested, which itself delegates to
c-2-1) caffe2::ThreadPool, and the rabbit hole ends here.
NNPACK, and (PyTorch) QNNPACK directly hook into (c). They never go through (b).
Differential Revision: D21232894
Test Plan: Imported from OSS
Reviewed By: dreiss
Pulled By: AshkanAliabadi
fbshipit-source-id: 8b3de86247fbc3a327e811983e082f9d40081354
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39588
Before this diff we used c++_static linking.
Users will dynamically link to libpytorch_jni.so and have at least one more their own shared library that probably uses stl library.
We must have not more than one stl per app. ( https://developer.android.com/ndk/guides/cpp-support#one_stl_per_app )
To have only one stl per app changing ANDROID_STL way to c++_shared, that will add libc++_shared.so to packaging.
Test Plan: Imported from OSS
Differential Revision: D22118031
Pulled By: IvanKobzarev
fbshipit-source-id: ea1e5085ae207a2f42d1fa9f6ab8ed0a21768e96
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39507
Adding gradle task that will be run after `assemble` to add `headers` folder to the aar.
Headers are choosed for the first specified abi, they should be the same for all abis.
Adding headers works through temporary unpacking into gradle `$buildDir`, copying headers to it, zipping aar with headers.
Test Plan: Imported from OSS
Differential Revision: D22118009
Pulled By: IvanKobzarev
fbshipit-source-id: 52e5b1e779eb42d977c67dba79e278f1922b8483
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/39188
Extracting Vulkan_LIBS and Vulkan_INCLUDES setup from `cmake/Dependencies.cmake` to `cmake/VulkanDependencies.cmake` and reuse it in android/pytorch_android/CMakeLists.txt
Adding control to build with Vulkan setting env variable `USE_VULKAN` for `scripts/build_android.sh` `scripts/build_pytorch_android.sh`
We do not use Vulkan backend in pytorch_android, but with this build option we can track android aar change with `USE_VULKAN` added.
Currently it is 88Kb.
Test Plan: Imported from OSS
Differential Revision: D21770892
Pulled By: IvanKobzarev
fbshipit-source-id: a39433505fdcf43d3b524e0fe08062d5ebe0d872
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/37548
Moving RecordFunction from torch::autograd::profiler into at namespace
Test Plan:
CI
Imported from OSS
Differential Revision: D21315852
fbshipit-source-id: 4a4dbabf116c162f9aef0da8606590ec3f3847aa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34710
Extending RecordFunction API to support new recording scopes (such as TorchScript functions), as well as giving more flexibility to set sampling rate.
Test Plan: unit test (test_misc.cpp/testRecordFunction)
Reviewed By: gdankel, dzhulgakov
Differential Revision: D20158523
fbshipit-source-id: a9e0819d21cc06f4952d92d43246587c36137582
Summary:
Ignore mixed upper-case/lower-case style for now
Fix space between function and its arguments violation
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35574
Test Plan: CI
Differential Revision: D20712969
Pulled By: malfet
fbshipit-source-id: 0012d430aed916b4518599a0b535e82d15721f78
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32313
`torch::autograd::profiler::pushCallback()`, `torch::jit::setPrintHandler` should be called only once, not before every loading
`JITCallGuard guard;` not needed before loading module and has no effect
Test Plan: Imported from OSS
Differential Revision: D20559676
Pulled By: IvanKobzarev
fbshipit-source-id: 70cce5d2dda20a00b378639725294cb3c440bad2
Summary:
There are three guards related to mobile build:
* AutoGradMode
* AutoNonVariableTypeMode
* GraphOptimizerEnabledGuard
Today we need set some of these guards before calling libtorch APIs because we customized mobile build to only support inference (for both OSS and most FB use cases) to optimize binary size.
Several changes were made since 1.3 release so there are already inconsistent uses of these guards in the codebase. I did a sweep of all mobile related model loading & forward() call sites, trying to unify the use of these guards:
Full JIT: still set all three guards. More specifically:
* OSS: Fixed a bug of not setting the guard at model load time correctly in Android JNI.
* FB: Not covered by this diff (as we are using mobile interpreter for most internal builds).
Lite JIT (mobile interpreter): only needs AutoNonVariableTypeMode guard. AutoGradMode doesn't seem to be relevant (so removed from a few places) and GraphOptimizerEnabledGuard definitely not relevant (only full JIT has graph optimizer). More specifically:
* OSS: At this point we are not committed to support Lite-JIT. For Android it shares the same code with FB JNI callsites.
* FB:
** JNI callsites: Use the unified LiteJITCallGuard.
** For iOS/C++: manually set AutoNonVariableTypeMode for _load_for_mobile() & forward() callsites.
Ideally we should avoid having to set AutoNonVariableTypeMode for mobile interpreter. It's currently needed for dynamic dispatch + inference-only mobile build (where variable kernels are not registered) - without the guard it will try to run `variable_fallback_kernel` and crash (PR #34038). The proper fix will take some time so using this workaround to unblock selective BUCK build which depends on dynamic dispatch.
PS. The current status (of having to set AutoNonVariableTypeMode) should not block running FL model + mobile interpreter - if all necessary variable kernels are registered then it can call _load_for_mobile()/forward() against the FL model without setting the AutoNonVariableTypeMode guard. It's still inconvenient for JAVA callsites as it's set unconditionally inside JNI methods.
Test Plan: - CI
Reviewed By: xta0
Differential Revision: D20498017
fbshipit-source-id: ba6740f66839a61790873df46e8e66e4e141c728
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34515
Once upon a time we thought this was necessary. In reality it is not, so
removing it.
For backcompat, our public interface (defined in `api/`) still has
typedefs to the old `script::` names.
There was only one collision: `Pass` as a `Stmt` and `Pass` as a graph
transform. I renamed one of them.
Test Plan: Imported from OSS
Differential Revision: D20353503
Pulled By: suo
fbshipit-source-id: 48bb911ce75120a8c9e0c6fb65262ef775dfba93
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/34556
According to
https://github.com/pytorch/pytorch/pull/34012#discussion_r388581548,
this `at::globalContext().setQEngine(at::QEngine::QNNPACK);` call isn't
really necessary for mobile.
In Context.cpp it selects the last available QEngine if the engine isn't
set explicitly. For OSS mobile prebuild it should only include QNNPACK
engine so the default behavior should already be desired behavior.
It makes difference only when USE_FBGEMM is set - but it should be off
for both OSS mobile build and internal mobile build.
Test Plan: Imported from OSS
Differential Revision: D20374522
Pulled By: ljk53
fbshipit-source-id: d4e437a03c6d4f939edccb5c84f02609633a0698
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33722
In order to improve CPU performance on floating-point models on mobile, this PR introduces a new CPU backend for mobile that implements the most common mobile operators with NHWC memory layout support through integration with XNNPACK.
XNNPACK itself, and this codepath, are currently only included in the build, but the actual integration is gated with USE_XNNPACK preprocessor guards. This preprocessor symbol is intentionally not passed on to the compiler, so as to enable this rollout in multiple stages in follow up PRs. This changeset will build XNNPACK as part of the build if the identically named USE_XNNPACK CMAKE variable, defaulted to ON, is enabled, but will not actually expose or enable this code path in any other way.
Furthermore, it is worth pointing out that in order to efficiently map models to these operators, some front-end method of exposing this backend to the user is needed. The less efficient implementation would be to hook these operators into their corresponding native implementations, granted that a series of XNNPACK-specific conditions are met, much like how NNPACK is integrated with PyTorch today for instance.
Having said that, while the above implementation is still expected to outperform NNPACK based on the benchmarks I ran, the above integration would be leave a considerable gap between the performance achieved and the maximum performance potential XNNPACK enables, as it does not provide a way to compute and factor out one-time operations out of the inner most forward() loop.
The more optimal solution, and one we will decide on soon, would involve either providing a JIT pass that maps nn operators onto these newly introduced operators, while allowing one-time calculations to be factored out, much like quantized mobile models. Alternatively, new eager-mode modules can also be introduced that would directly call into these implementations either through c10 or some other mechanism, also allowing for decoupling of op creation from op execution.
This PR does not include any of the front end changes mentioned above. Neither does it include the mobile threadpool unification present in the original https://github.com/pytorch/pytorch/issues/30644. Furthermore, this codepath seems to be faster than NNPACK in a good number of use cases, which can potentially allow us to remove NNPACK from aten to make the codebase a little simpler, granted that there is widespread support for such a move.
Regardless, these changes will be introduced gradually and in a more controlled way in subsequent PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32509
Test Plan:
Build: CI
Functionality: Not exposed
Reviewed By: dreiss
Differential Revision: D20069796
Pulled By: AshkanAliabadi
fbshipit-source-id: d46c1c91d4bea91979ea5bd46971ced5417d309c
Summary:
In order to improve CPU performance on floating-point models on mobile, this PR introduces a new CPU backend for mobile that implements the most common mobile operators with NHWC memory layout support through integration with XNNPACK.
XNNPACK itself, and this codepath, are currently only included in the build, but the actual integration is gated with USE_XNNPACK preprocessor guards. This preprocessor symbol is intentionally not passed on to the compiler, so as to enable this rollout in multiple stages in follow up PRs. This changeset will build XNNPACK as part of the build if the identically named USE_XNNPACK CMAKE variable, defaulted to ON, is enabled, but will not actually expose or enable this code path in any other way.
Furthermore, it is worth pointing out that in order to efficiently map models to these operators, some front-end method of exposing this backend to the user is needed. The less efficient implementation would be to hook these operators into their corresponding **native** implementations, granted that a series of XNNPACK-specific conditions are met, much like how NNPACK is integrated with PyTorch today for instance.
Having said that, while the above implementation is still expected to outperform NNPACK based on the benchmarks I ran, the above integration would be leave a considerable gap between the performance achieved and the maximum performance potential XNNPACK enables, as it does not provide a way to compute and factor out one-time operations out of the inner most forward() loop.
The more optimal solution, and one we will decide on soon, would involve either providing a JIT pass that maps nn operators onto these newly introduced operators, while allowing one-time calculations to be factored out, much like quantized mobile models. Alternatively, new eager-mode modules can also be introduced that would directly call into these implementations either through c10 or some other mechanism, also allowing for decoupling of op creation from op execution.
This PR does not include any of the front end changes mentioned above. Neither does it include the mobile threadpool unification present in the original https://github.com/pytorch/pytorch/issues/30644. Furthermore, this codepath seems to be faster than NNPACK in a good number of use cases, which can potentially allow us to remove NNPACK from aten to make the codebase a little simpler, granted that there is widespread support for such a move.
Regardless, these changes will be introduced gradually and in a more controlled way in subsequent PRs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32509
Reviewed By: dreiss
Differential Revision: D19521853
Pulled By: AshkanAliabadi
fbshipit-source-id: 99a1fab31d0ece64961df074003bb852c36acaaa
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32567
As a first change to support proguard.
even if these methods could be not called from java, on jni level we register them and this registration will fail if methods are stripped.
Adding DoNotStrip to all native methods that are registered in OSS.
After integration of consumerProguardFiles in fbjni that prevents stripping by proguard DoNotStrip it will fix errors with proguard on.
Test Plan: Imported from OSS
Differential Revision: D19624684
Pulled By: IvanKobzarev
fbshipit-source-id: cd7d9153e9f8faf31c99583cede4adbf06bab507
Summary:
Without this, dlopen won't look in the proper directory for dependencies
(like libtorch and fbjni).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32247
Test Plan:
Build libpytorch_jni.dylib on Mac, replaced the one from the libtorch
nightly, and was able to run the Java demo.
Differential Revision: D19501498
Pulled By: dreiss
fbshipit-source-id: 13ffdff9622aa610f905d039f951ee9a3fdc6b23
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31456
External request https://discuss.pytorch.org/t/jit-android-debugging-the-model/63950
By default torchscript print function goes to stdout. For android it is not seen in logcat by default.
This change propagates it to logcat.
Test Plan: Imported from OSS
Differential Revision: D19171405
Pulled By: IvanKobzarev
fbshipit-source-id: f9c88fa11d90bb386df9ed722ec9345fc6b25a34
Summary: I think this was wrong before?
Test Plan: Not sure.
Reviewed By: IvanKobzarev
Differential Revision: D19221358
fbshipit-source-id: 27e675cac15dde29e026305f4b4e6cc774e15767
Summary:
These were returning incorrect data before. Now we make a contiguous copy
before converting to Java. Exposing raw data to the user might be faster in
some cases, but it's not clear that it's worth the complexity and code size.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221361
fbshipit-source-id: 22ecdad252c8fd968f833a2be5897c5ae483700c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31584
These were returning incorrect data before.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221360
fbshipit-source-id: b3f01de086857027f8e952a1c739f60814a57acd
Summary: These are valid tensors.
Test Plan: New unit test.
Reviewed By: IvanKobzarev
Differential Revision: D19221362
fbshipit-source-id: fa9af2fc539eb7381627b3d473241a89859ef2ba
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30501
**Motivation**:
In current state output of libtorch Module forward,runMethod is mem copied to java ByteBuffer, which is allocated, at least in some versions of android, on java heap. That could lead to intensive garbage collection.
**Change**:
Output java tensor becomes owner of output at::Tensor and holds it (as `pytorch_jni::TensorHybrid::tensor_` field) alive until java part is not destroyed by GC. For that org.pytorch.Tensor becomes 'Hybrid' class in fbjni naming and starts holding member field `HybridData mHybridData;`
If construction of it starts from java side - java constructors of subclasses (we need all the fields initialized, due to this `mHybridData` is not declared final, but works as final) call `this.mHybridData = super.initHybrid();` to initialize cpp part (`at::Tensor tensor_`).
If construction starts from cpp side - cpp side is initialiaed using provided at::Tensor with `makeCxxInstance(std::move(tensor))` and is passed to java method `org.pytorch.Tensor#nativeNewTensor` as parameter `HybridData hybridData`, which holds native pointer to cpp side.
In that case `initHybrid()` method is not called, but parallel set of ctors of subclasses are used, which stores `hybridData` in `mHybridData`.
Renaming:
`JTensor` -> `TensorHybrid`
Removed method:
`JTensor::newAtTensorFromJTensor(JTensor)` becomes trivial `TensorHybrid->cthis()->tensor()`
Test Plan: Imported from OSS
Differential Revision: D18893320
Pulled By: IvanKobzarev
fbshipit-source-id: df94775d2a010a1ad945b339101c89e2b79e0f83
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30175
fbjni was opensourced and java part is published as 'com.facebook.fbjni:fbjni-java-only:0.0.3'
switching to it.
We still need submodule fbjni inside the repo (which is already pointing to https://github.com/facebookincubator/fbjni) for so linking.
**Packaging changes**:
before that `libfbjni.so` came from pytorch_android_fbjni dependency, as we also linked fbjni in `pytorch_android/CMakeLists.txt` - it was built in pytorch_android, but excluded for publishing. As we had 2 libfbjni.so there was a hack to exclude it for publishing and resolve duplication locally.
```
if (rootProject.isPublishing()) {
exclude '**/libfbjni.so'
} else {
pickFirst '**/libfbjni.so'
}
```
After this change fbjni.so will be packaged inside pytorch_android.aar artefact and we do not need this gradle logic.
I will update README in separate PR after landing previous PR to readme(https://github.com/pytorch/pytorch/pull/30128) to avoid conflicts
Test Plan: Imported from OSS
Differential Revision: D18982235
Pulled By: IvanKobzarev
fbshipit-source-id: 5097df2557858e623fa480625819a24a7e8ad840
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30315
The new structure is that libtorch_cpu contains the bulk of our
code, and libtorch depends on libtorch_cpu and libtorch_cuda.
This is a reland of https://github.com/pytorch/pytorch/pull/29731 but
I've extracted all of the prep work into separate PRs which can be
landed before this one.
Some things of note:
* torch/csrc/cuda/nccl.cpp was added to the wrong list of SRCS, now fixed (this didn't matter before because previously they were all in the same library)
* The dummy file for libtorch was brought back from the dead; it was previously deleted in #20774
In an initial version of the patch, I forgot to make torch_cuda explicitly depend on torch_cpu. This lead to some very odd errors, most notably "bin/blob_test: hidden symbol `_ZNK6google8protobuf5Arena17OnArenaAllocationEPKSt9type_infom' in lib/libprotobuf.a(arena.cc.o) is referenced by DSO"
* A number of places in Android/iOS builds have to add torch_cuda explicitly as a library, as they do not have transitive dependency calculation working correctly
* I had to torch_cpu/torch_cuda caffe2_interface_library so that they get whole-archived linked into torch when you statically link. And I had to do this in an *exported* fashion because torch needs to depend on torch_cpu_library. In the end I exported everything and removed the redefinition in the Caffe2Config.cmake. However, I am not too sure why the old code did it in this way in the first place; however, it doesn't seem to have broken anything to switch it this way.
* There's some uses of `__HIP_PLATFORM_HCC__` still in `torch_cpu` code, so I had to apply it to that library too (UGH). This manifests as a failer when trying to run the CUDA fuser. This doesn't really matter substantively right now because we still in-place HIPify, but it would be good to fix eventually. This was a bit difficult to debug because of an unrelated HIP bug, see https://github.com/ROCm-Developer-Tools/HIP/issues/1706Fixes#27215 (as our libraries are smaller), and executes on
part of the plan in #29235.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18790941
Pulled By: ezyang
fbshipit-source-id: 01296f6089d3de5e8365251b490c51e694f2d6c7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30428
Reported issue https://discuss.pytorch.org/t/incomprehensible-behaviour/61710
Steps to reproduce:
```
class WrapRPN(nn.Module):
def __init__(self):
super().__init__()
def forward(self, features):
# type: (Dict[str, Tensor]) -> int
return 0
```
```
#include <torch/script.h>
int main() {
torch::jit::script::Module module = torch::jit::load("dict_str_tensor.pt");
torch::Tensor tensor = torch::rand({2, 3});
at::IValue ivalue{tensor};
c10::impl::GenericDict dict{c10::StringType::get(),ivalue.type()};
dict.insert("key", ivalue);
module.forward({dict});
}
```
ValueType of `c10::impl::GenericDict` is from the first specified element as `ivalue.type()`
It fails on type check in` function_schema_inl.h` !value.type()->isSubtypeOf(argument.type())
as `DictType::isSubtypeOf` requires equal KeyType and ValueType, while `TensorType`s are different.
Fix:
Use c10::unshapedType for creating Generic List/Dict
Test Plan: Imported from OSS
Differential Revision: D18717189
Pulled By: IvanKobzarev
fbshipit-source-id: 1e352a9c776a7f7e69fd5b9ece558f1d1849ea57
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30472
Add DoNotStrip to nativeNewTensor method.
ghstack-source-id: 94596624
Test Plan:
Triggered build on diff for automation_fbandroid_fallback_release.
buck install -r fb4a
Tested BI cloaking using pytext lite interpreter.
Obverse that logs are sent to scuba table:
{F223408345}
Reviewed By: linbinyu
Differential Revision: D18709087
fbshipit-source-id: 74fa7a0665640c294811a50913a60ef8d6b9b672
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30390
Fix the crashes for c++ not able to find java class through Jni
ghstack-source-id: 94499644
Test Plan: buck install -r fb4a
Reviewed By: ljk53
Differential Revision: D18667992
fbshipit-source-id: aa1b19c6dae39d46440f4a3e691054f7f8b1d42e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30285
PR #30144 introduced custom build script to tailor build to specific
models. It requires a list of all potentially used ops at build time.
Some JIT optimization passes can transform the IR by replacing
operators, e.g. decompose pass can replace aten::addmm with aten::mm if
coefficients are 1s.
Disabling optimization pass can ensure that the list of ops we dump from
the model is the list of ops that are needed.
Test Plan: - rerun the test on PR #30144 to verify the raw list without aten::mm works.
Differential Revision: D18652777
Pulled By: ljk53
fbshipit-source-id: 084751cb9a9ee16d8df7e743e9e5782ffd8bc4e3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30206
- --whole-archive isn't needed because we link libtorch as a dynamic
dependency, rather than static.
- --gc-sections isn't necessary because most (all?) of the code in our
JNI library is used (and we're not staticly linking libtorch).
Removing this one is useful because it's not supported by lld.
Test Plan:
Built on Linux. Library size was unchanged.
Upcoming diff enables Mac JNI build.
Differential Revision: D18653500
Pulled By: dreiss
fbshipit-source-id: 49ce46fb86a775186f803ada50445b4b2acb54a8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29731
The new structure is that libtorch_cpu contains the bulk of our
code, and libtorch depends on libtorch_cpu and libtorch_cuda.
Some subtleties about the patch:
- There were a few functions that crossed CPU-CUDA boundary without API macros. I just added them, easy enough. An inverse situation was aten/src/THC/THCTensorRandom.cu where we weren't supposed to put API macros directly in a cpp file.
- DispatchStub wasn't getting all of its symbols related to static members on DispatchStub exported properly. I tried a few fixes but in the end I just moved everyone off using DispatchStub to dispatch CUDA/HIP (so they just use normal dispatch for those cases.) Additionally, there were some mistakes where people incorrectly were failing to actually import the declaration of the dispatch stub, so added includes for those cases.
- torch/csrc/cuda/nccl.cpp was added to the wrong list of SRCS, now fixed (this didn't matter before because previously they were all in the same library)
- The dummy file for libtorch was brought back from the dead; it was previously deleted in #20774
- In an initial version of the patch, I forgot to make torch_cuda explicitly depend on torch_cpu. This lead to some very odd errors, most notably "bin/blob_test: hidden symbol `_ZNK6google8protobuf5Arena17OnArenaAllocationEPKSt9type_infom' in lib/l
ibprotobuf.a(arena.cc.o) is referenced by DSO"
- A number of places in Android/iOS builds have to add torch_cuda explicitly as a library, as they do not have transitive dependency calculation working correctly. This situation also happens with custom C++ extensions.
- There's a ROCm compiler bug where extern "C" on functions is not respected. There's a little workaround to handle this.
- Because I was too lazy to check if HIPify was converting TORCH_CUDA_API into TORCH_HIP_API, I just made it so HIP build also triggers the TORCH_CUDA_API macro. Eventually, we should translate and keep the nature of TORCH_CUDA_API constant in all cases.
Fixes#27215 (as our libraries are smaller), and executes on
part of the plan in #29235.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Test Plan: Imported from OSS
Differential Revision: D18632773
Pulled By: ezyang
fbshipit-source-id: ea717c81e0d7554ede1dc404108603455a81da82
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30180
Just applying `clang-format -i` to not mix it with other changes
Test Plan: Imported from OSS
Differential Revision: D18627473
Pulled By: IvanKobzarev
fbshipit-source-id: ed341e356fea31b8515de29d5ea2ede07e8b66a2
Summary:
- Add a "BUILD_JNI" option that enables building PyTorch JNI bindings and
fbjni. This is off by default because it adds a dependency on jni.h.
- Update to the latest fbjni so we can inhibit building its tests,
because they depend on gtest.
- Set JAVA_HOME and BUILD_JNI in Linux binary build configurations if we
can find jni.h in Docker.
Test Plan:
- Built on dev server.
- Verified that libpytorch_jni links after libtorch when both are built
in a parallel build.
Differential Revision: D18536828
fbshipit-source-id: 19cb3be8298d3619352d02bb9446ab802c27ec66
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29861
Follow https://github.com/pytorch/pytorch/issues/6570 to run ./run_host_tests.sh for Mac Build, we saw error below:
```error: cannot initialize a parameter of type 'const facebook::jni::JPrimitiveArray<_jlongArray *>::T *' (aka 'const long *') with an rvalue of type
'std::__1::vector<long long, std::__1::allocator<long long> >::value_type *' (aka 'long long *')
jTensorShape->setRegion(0, tensorShapeVec.size(), tensorShapeVec.data());```
ghstack-source-id: 93961091
Test Plan: Run ./run_host_tests.sh and verify build succeed.
Reviewed By: dreiss
Differential Revision: D18519087
fbshipit-source-id: 869be12c82e6e0f64c878911dc12459defebf40b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29617
As for internal build, we will use mobile interpreter instead of full jit, so we will need to separate the existing pytorch_jni.cpp into pytorch_jni_jit.cpp and pytorch_jni_common.cpp. pytorch_jni_common.cpp will be used both from pytorch_jni_jit.cpp(open_source) and future pytorch_jni_lite.cpp(internal).
ghstack-source-id: 93691214
Test Plan: buck build xplat/caffe2/android:pytorch
Reviewed By: dreiss
Differential Revision: D18387579
fbshipit-source-id: 26ab845c58a0959bc0fdf1a2b9a99f6ad6f2fc9c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/29412
Originally, this was going to be Android-only, so the name wasn't too
important. But now that we're planning to distribute it with libtorch,
we should give it a more distinctive name.
Test Plan:
Ran tests according to
https://github.com/pytorch/pytorch/issues/6570#issuecomment-548537834
Reviewed By: IvanKobzarev
Differential Revision: D18405207
fbshipit-source-id: 0e6651cb34fb576438f24b8a9369e10adf9fecf9
Summary:
Reason:
To have one-step build for test android application based on the current code state that is ready for profiling with simpleperf, systrace etc. to profile performance inside the application.
## Parameters to control debug symbols stripping
Introducing /CMakeLists parameter `ANDROID_DEBUG_SYMBOLS` to be able not to strip symbols for pytorch (not add linker flag `-s`)
which is checked in `scripts/build_android.sh`
On gradle side stripping happens by default, and to prevent it we have to specify
```
android {
packagingOptions {
doNotStrip "**/*.so"
}
}
```
which is now controlled by new gradle property `nativeLibsDoNotStrip `
## Test_App
`android/test_app` - android app with one MainActivity that does inference in cycle
`android/build_test_app.sh` - script to build libtorch with debug symbols for specified android abis and adds `NDK_DEBUG=1` and `-PnativeLibsDoNotStrip=true` to keep all debug symbols for profiling.
Script assembles all debug flavors:
```
└─ $ find . -type f -name *apk
./test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
./test_app/app/build/outputs/apk/resnet/debug/test_app-resnet-debug.apk
```
## Different build configurations
Module for inference can be set in `android/test_app/app/build.gradle` as a BuildConfig parameters:
```
productFlavors {
mobilenetQuant {
dimension "model"
applicationIdSuffix ".mobilenetQuant"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_MOBILENET_QUANT'))
addManifestPlaceholders([APP_NAME: "PyMobileNetQuant"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-mobilenet\"")
}
resnet {
dimension "model"
applicationIdSuffix ".resnet"
buildConfigField ("String", "MODULE_ASSET_NAME", buildConfigProps('MODULE_ASSET_NAME_RESNET18'))
addManifestPlaceholders([APP_NAME: "PyResnet"])
buildConfigField ("String", "LOGCAT_TAG", "\"pytorch-resnet\"")
}
```
In that case we can setup several apps on the same device for comparison, to separate packages `applicationIdSuffix`: 'org.pytorch.testapp.mobilenetQuant' and different application names and logcat tags as `manifestPlaceholder` and another BuildConfig parameter:
```
─ $ adb shell pm list packages | grep pytorch
package:org.pytorch.testapp.mobilenetQuant
package:org.pytorch.testapp.resnet
```
In future we can add another BuildConfig params e.g. single/multi threads and other configuration for profiling.
At the moment 2 flavors - for resnet18 and for mobilenetQuantized
which can be installed on connected device:
```
cd android
```
```
gradle test_app:installMobilenetQuantDebug
```
```
gradle test_app:installResnetDebug
```
## Testing:
```
cd android
sh build_test_app.sh
adb install -r test_app/app/build/outputs/apk/mobilenetQuant/debug/test_app-mobilenetQuant-debug.apk
```
```
cd $ANDROID_NDK
python simpleperf/run_simpleperf_on_device.py record --app org.pytorch.testapp.mobilenetQuant -g --duration 10 -o /data/local/tmp/perf.data
adb pull /data/local/tmp/perf.data
python simpleperf/report_html.py
```
Simpleperf report has all symbols:
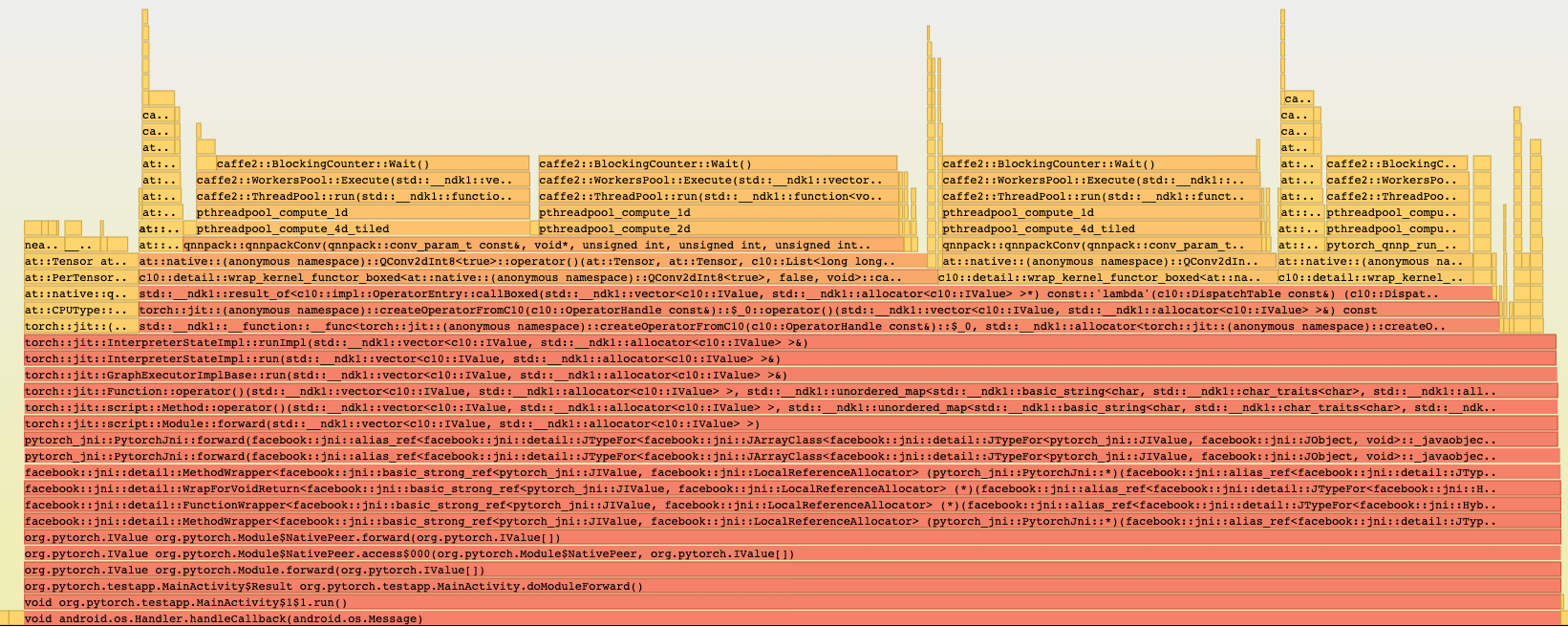
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28406
Differential Revision: D18386622
Pulled By: IvanKobzarev
fbshipit-source-id: 3a751192bbc4bc3c6d7f126b0b55086b4d586e7a
Summary:
The central fbjni repository is now public, so point to it and
take the latest version, which includes support for host builds
and some condensed syntax.
Test Plan: CI
Differential Revision: D18217840
fbshipit-source-id: 454e3e081f7e3155704fed692506251c4018b2a1
Summary:
The Java and Python code were updated, but the test currently fails
because the model was not regenerated.
Test Plan: Ran test.
Reviewed By: xcheng16
Differential Revision: D18217841
fbshipit-source-id: 002eb2d3ed0eaa14b3d7b087b621a6970acf1378
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27664
When ANDROID_ABI is not set, find libtorch headers and libraries from
the LIBTORCH_HOME build variable (which must be set by hand), place
output under a "host" directory, and use dynamic linking instead of
static.
This doesn't actually work without some local changes to fbjni, but I
want to get the changes landed to avoid unnecessary merge conflicts.
Test Plan: Imported from OSS
Differential Revision: D18210315
Pulled By: dreiss
fbshipit-source-id: 685a62de3c2a0a52bec7fd6fb95113058456bac8
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27663
CMake sets CMAKE_BINARY_DIR and creates it automatically. Using this
allows us to use the -B command-line flag to CMake to specify an
alternate output directory.
Test Plan: Imported from OSS
Differential Revision: D18210316
Pulled By: dreiss
fbshipit-source-id: ba2f6bd4b881ddd00de73fe9c33d82645ad5495d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/27662
This adds a new gradle subproject at pytorch_android/host and tweaks
the top-level build.gradle to only run some Android bits on the other
projects.
Referencing Java sources from inside the host directory feels a bit
hacky, but getting host and Android Gradle builds to coexist in the same
directory hit several roadblocks. We can try a bigger refactor to
separate the Android-specific and non-Android-specific parts of the
code, but that seems overkill at this point for 4 Java files.
This doesn't actually run without some local changes to fbjni, but I
want to get the files landed to avoid unnecessary merge conflicts.
Test Plan: Imported from OSS
Differential Revision: D18210317
Pulled By: dreiss
fbshipit-source-id: dafb54dde06a5a9a48fc7b7065d9359c5c480795
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/28399
This is also to address issue #26764
Turns out it's incorrect to wrap the entire forward() call with
NonVariableTypeMode guard as some JIT passes has is_variable() check and
can be triggered within forward() call, e.g.:
jit/passes/constant_propagation.cpp
Since now we are toggling NonVariableTypeMode per method/op call, we can
remove the guard around forward() now.
Test Plan: - With stacked PRs, verified it can load and run previously failed models.
Differential Revision: D18055850
Pulled By: ljk53
fbshipit-source-id: 3074d0ed3c6e05dbfceef6959874e5916aea316c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26767
Now that we have tagged ivalues, we can accurately recover the type with
`ivalue.type()`. This reomoves the other half-implemented pathways that
were created because we didn't have tags.
Test Plan: Imported from OSS
Differential Revision: D17561191
Pulled By: zdevito
fbshipit-source-id: 26aaa134099e75659a230d8a5a34a86dc39a3c5c
{kind=link}
{kind=link}
{kind=link}