Doing some tests with all Optimizer and LRScheduler classes in optim package, I noticed a couple of mistakes in type annotations, so created a pull request to fix them.
- In Optimizer class, incorrectly named parameter `default` instead of `defaults` in pyi file
- In SGD class, type for `maximize` and `differentiable` not available in either py or pyi files
I don't know if there is a plan to move all types from pyi to py files, so wasn't too sure where to fix what.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/90216
Approved by: https://github.com/janeyx99
This is a new version of #15648 based on the latest master branch.
Unlike the previous PR where I fixed a lot of the doctests in addition to integrating xdoctest, I'm going to reduce the scope here. I'm simply going to integrate xdoctest, and then I'm going to mark all of the failing tests as "SKIP". This will let xdoctest run on the dashboards, provide some value, and still let the dashboards pass. I'll leave fixing the doctests themselves to another PR.
In my initial commit, I do the bare minimum to get something running with failing dashboards. The few tests that I marked as skip are causing segfaults. Running xdoctest results in 293 failed, 201 passed tests. The next commits will be to disable those tests. (unfortunately I don't have a tool that will insert the `#xdoctest: +SKIP` directive over every failing test, so I'm going to do this mostly manually.)
Fixes https://github.com/pytorch/pytorch/issues/71105
@ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82797
Approved by: https://github.com/ezyang
### Description
Across PyTorch's docstrings, both `callable` and `Callable` for variable types. The Callable should be capitalized as we are referring to the `Callable` type, and not the Python `callable()` function.
### Testing
There shouldn't be any testing required.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82487
Approved by: https://github.com/albanD
Adds the `differentiable` argument, a method for updating parameters in an existing optimizer, and a template for testing the differentiability of multiple optimizers.
This is all based in discussions with @albanD & @jbschlosser
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80938
Approved by: https://github.com/albanD
Generator comprehensions with any/all are less verbose and potentially help to save memory/CPU : https://eklitzke.org/generator-comprehensions-and-using-any-and-all-in-python
To make JIT work with this change, I added code to convert GeneratorExp to ListComp. So the whole PR is basically NoOp for JIT, but potentially memory and speed improvement for eager mode.
Also I removed a test from test/jit/test_parametrization.py. The test was bad and had a TODO to actually implement and just tested that UnsupportedNodeError is thrown, and with GeneratorExp support a different error would be thrown.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78142
Approved by: https://github.com/malfet, https://github.com/albanD
Summary:
After 'maximize' flag was introduced in https://github.com/pytorch/pytorch/issues/46480 some jobs fail because they resume training from the checkpoints.
After we load old checkpoints we will get an error during optimizer.step() call during backward pass in [torch/optim/sgd.py", line 129] because there is no key 'maximize' in the parameter groups of the SGD.
To circumvent this I add a default value `group.setdefault('maximize', False)` when the optimizer state is restored.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68733
Reviewed By: albanD
Differential Revision: D32480963
Pulled By: asanakoy
fbshipit-source-id: 4e367fe955000a6cb95090541c143a7a1de640c2
Summary:
Fixes https://github.com/pytorch/pytorch/issues/46480 -- for SGD.
## Notes:
- I have modified the existing tests to take a new `constructor_accepts_maximize` flag. When this is set to true, the ` _test_basic_cases_template` function will test both maximizing and minimizing the sample function.
- This was the clearest way I could think of testing the changes -- I would appreciate feedback on this strategy.
## Work to be done:
[] I need to update the docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67847
Reviewed By: H-Huang
Differential Revision: D32252631
Pulled By: albanD
fbshipit-source-id: 27915a3cc2d18b7e4d17bfc2d666fe7d2cfdf9a4
Summary:
It has been discussed before that adding description of Optimization algorithms to PyTorch Core documentation may result in a nice Optimization research tutorial. In the following tracking issue we mentioned about all the necessary algorithms and links to the originally published paper https://github.com/pytorch/pytorch/issues/63236.
In this PR we are adding description of Stochastic Gradient Descent to the documentation.
<img width="466" alt="SGDalgo" src="https://user-images.githubusercontent.com/73658284/132585881-b351a6d4-ece0-4825-b9c0-126d7303ed53.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63805
Reviewed By: albanD
Differential Revision: D30818947
Pulled By: iramazanli
fbshipit-source-id: 3812028e322c8a64f4343552b0c8c4582ea382f3
Summary:
Context: https://github.com/pytorch/pytorch/pull/53299#discussion_r587882857
These are the only hand-written parts of this diff:
- the addition to `.github/workflows/lint.yml`
- the file endings changed in these four files (to appease FB-internal land-blocking lints):
- `GLOSSARY.md`
- `aten/src/ATen/core/op_registration/README.md`
- `scripts/README.md`
- `torch/csrc/jit/codegen/fuser/README.md`
The rest was generated by running this command (on macOS):
```
git grep -I -l ' $' -- . ':(exclude)**/contrib/**' ':(exclude)third_party' | xargs gsed -i 's/ *$//'
```
I looked over the auto-generated changes and didn't see anything that looked problematic.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53406
Test Plan:
This run (after adding the lint but before removing existing trailing spaces) failed:
- https://github.com/pytorch/pytorch/runs/2043032377
This run (on the tip of this PR) succeeded:
- https://github.com/pytorch/pytorch/runs/2043296348
Reviewed By: walterddr, seemethere
Differential Revision: D26856620
Pulled By: samestep
fbshipit-source-id: 3f0de7f7c2e4b0f1c089eac9b5085a58dd7e0d97
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/51316
Make optim functional API be private until we release with beta
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D26213469
fbshipit-source-id: b0fd001a8362ec1c152250bcd57c7205ed893107
Summary:
The momentum buffer is initialized to the value of
d_p, but the current code takes the long way to do this:
1. Create a buffer of zeros
2. Multiply the buffer by the momentum coefficient
3. Add d_p to the buffer
All of these can be collapsed into a single step:
1. Create a clone of d_p
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18114
Differential Revision: D14509122
Pulled By: ezyang
fbshipit-source-id: 4a79b896201d5ff20770b7ae790c244ba744edb8
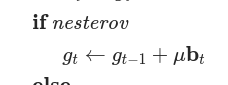{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
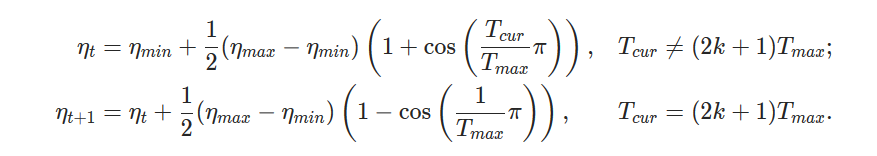{kind=link}
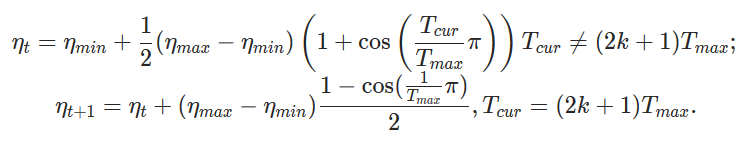{kind=link}
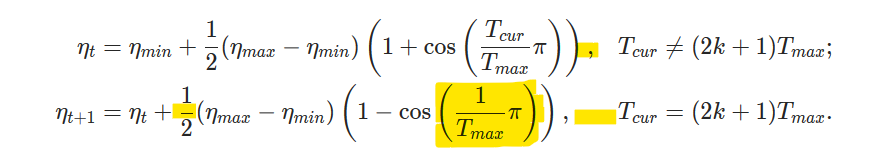{kind=link}