This PR adds support for XPU devices to the distributed MemoryTracker tool, including unit test for XPU.
Specifically, this code adds tracking for a few alloc-related statistics for XPUCachingAllocator. It also adapts the existing memory tracker tool to be device agnostic, by getting the device module and recording the necessary memory stats. (I get the device module instead of using `torch.accelerator` methods, as that API is still in-progress.)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/150703
Approved by: https://github.com/EikanWang, https://github.com/guangyey, https://github.com/gujinghui, https://github.com/d4l3k
Follow up to @ezyang's PR #153020 , but better uses PEP621 to reduce redundant fields and pass through metadata better to uv, setuptools, poetry and other tooling.
* Enables modern tooling like uv sync and better support for tools like poetry.
* Also allows us to set project wide settings that are respected by linters and IDE (in this example we are able centralize the minimum supported python version).
* Currently most of the values are dynamically fetched from setuptools, eventually we can migrate all the statically defined values to pyproject.toml and they will be autopopulated in the setuptool arguments.
* This controls what additional metadata shows up on PyPi . Special URL Names are listed here for rendering on pypi: https://packaging.python.org/en/latest/specifications/well-known-project-urls/#well-known-labels
These also clearly shows us what fields will need to be migrated to pyproject.toml over time from setup.py per #152276. Static fields be fairly easy to migrate, the dynamically built ones like requirements are a bit more challenging.
Without this, `uv sync` complains:
```
error: No `project` table found in: `pytorch/pyproject.toml`
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/153055
Approved by: https://github.com/ezyang
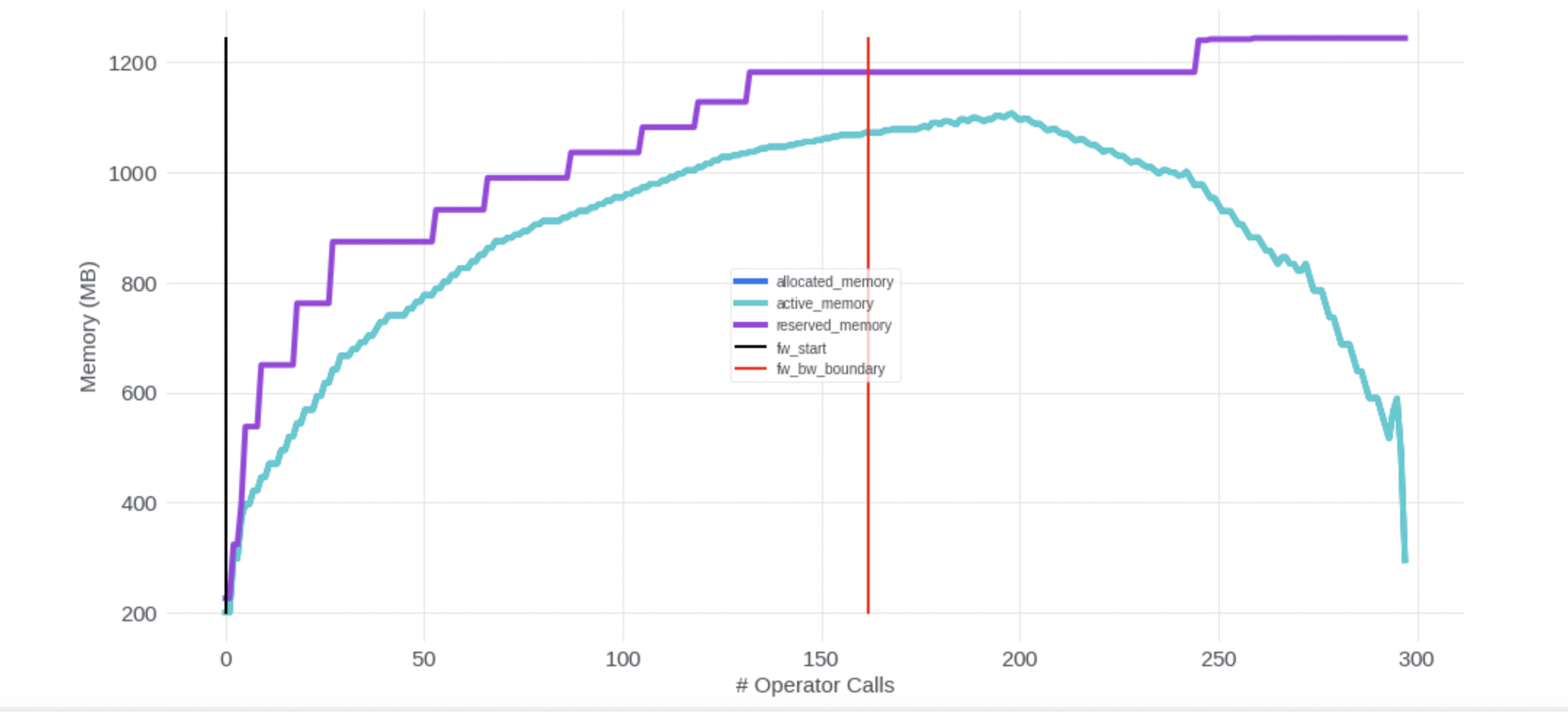
Adding a memory_tracker API to show operator level memory traces for allocated_memory, active_memory and reserved memory stats, it gave the summary about top 20 operators that generate memories as well.
The implementation mainly uses torchDispatchMode and module hooks to get traces and add markers.
Will add following up PRs:
1. allow tracing more than 1 iteration
2. dump json data for visualization
3. add unit test for DDP training
4. add unit test for FSDP training
5. add unit test for activation checkpointing + DDP/FSDP training
6. add traces for activation memories and top operators that generate activation memories
7. print summaries for more breakdowns like model size, optimizer states, etc
8. add traces for temporary memories or memories consumed by cuda streams or nccl library if possible
9. connect the tool with OOM memory debugging
10. add dynamic programming (dp) algorithm to find best activation checkpointing locations based on the operator level activation memory traces
11. add same traces & dp algorithm for module level memory stats, as FSDP wrapping depends on module level memories, for some model users/not model authors, if they have to apply activation checkpointing on module level, they need module level memory traces as well
======================================================
Current test result for the memory_tracker_example.py on notebook:
Top 20 ops that generates memory are:
bn1.forward.cudnn_batch_norm.default_0: 98.0009765625MB
maxpool.forward.max_pool2d_with_indices.default_0: 74.5MB
layer1.0.conv1.backward.max_pool2d_with_indices_backward.default_0: 49.0MB
layer1.0.bn1.forward.cudnn_batch_norm.default_1: 24.5009765625MB
layer1.0.bn2.forward.cudnn_batch_norm.default_2: 24.5009765625MB
layer1.1.bn1.forward.cudnn_batch_norm.default_3: 24.5009765625MB
layer1.1.bn2.forward.cudnn_batch_norm.default_4: 24.5009765625MB
layer1.2.bn1.forward.cudnn_batch_norm.default_5: 24.5009765625MB
layer1.2.bn2.forward.cudnn_batch_norm.default_6: 24.5009765625MB
layer1.0.conv1.forward.convolution.default_1: 24.5MB
layer1.0.conv2.forward.convolution.default_2: 24.5MB
layer1.1.conv1.forward.convolution.default_3: 24.5MB
layer1.1.conv2.forward.convolution.default_4: 24.5MB
layer1.2.conv1.forward.convolution.default_5: 24.5MB
layer1.2.conv2.forward.convolution.default_6: 24.5MB
maxpool.backward.threshold_backward.default_32: 23.5MB
layer2.0.downsample.backward.convolution_backward.default_26: 12.2802734375MB
layer2.0.bn1.forward.cudnn_batch_norm.default_7: 12.2509765625MB
layer2.0.bn2.forward.cudnn_batch_norm.default_8: 12.2509765625MB
layer2.0.downsample.1.forward.cudnn_batch_norm.default_9: 12.2509765625MB
<img width="1079" alt="Screen Shot 2022-11-10 at 10 03 06 AM" src="https://user-images.githubusercontent.com/48731194/201172577-ddfb769c-fb0f-4962-80df-92456b77903e.png">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88825
Approved by: https://github.com/awgu
{kind=link}