Refactor torchscript based exporter logic to move them to a single (private) location for better code management. Original public module and method apis are preserved.
- Updated module paths in `torch/csrc/autograd/python_function.cpp` accordingly
- Removed `check_onnx_broadcast` from `torch/autograd/_functions/utils.py` because it is private&unused
@albanD / @soulitzer could you review changes in `torch/csrc/autograd/python_function.cpp` and
`torch/autograd/_functions/utils.py`? Thanks!
## BC Breaking
- **Deprecated members in `torch.onnx.verification` are removed**
Differential Revision: [D81236421](https://our.internmc.facebook.com/intern/diff/D81236421)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/161323
Approved by: https://github.com/titaiwangms, https://github.com/angelayi
This PR is part of an effort to speed up torch.onnx.export (#121422).
- The `auto debug_names = ` infers a copy, where as `const auto& debug_names` does not.
- However, this ones requires us to be careful, since calls to `setDebugName` changes `debug_names` and invalidates the `exist_name` iterator. So if we simply change `auto` to `const auto&`, then between that line and `find` we have corrupted the iterator by calling `output[i]->setDebugName`. This change aims to be functionally equivalent to the original, which is why we first get the Value pointer, then call `output[i]->setDebugName`, and finally call `setDebugName` on the found value. It is possible functionally it is OK to simply call `output[i]->setDebugName` first and then find and the second `setDebugName`, but this would not be identical to current behavior.
- Resolves (2) in #121422.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123026
Approved by: https://github.com/justinchuby
This PR is part of an effort to speed up torch.onnx.export (#121422).
- The inputs (dynamic inputs and constants) do not change as as nodes are added and it is expensive to re-compute for every node. So, we cache this value so we avoid computing it for every node. Open to entirely other solution as well.
- Resolves (5) in #121422.
(partial fix of #121545)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123028
Approved by: https://github.com/justinchuby
This PR is part of a series of PRs to significantly speed up torch.onnx.export for models with many nodes (e.g. LLM). See #121422 for more analysis.
- As part of torch.onnx.export, a reverse look-up is made in env. This is done for each node, and this look-up costs in proportional to the graph size, which incurs and overall O(N^2) time complexity.
- A pragmatic solution is simply to keep a separate data structure to make this de facto constant time. So, this introduces a set containing all the values of env. Open to other ideas. Ideally `exist_in_env` wouldn't be needed at all, but to preserve current behavior exactly I'm not sure how that can be done.
- Resolves (4) in #121422.
- This code change and the choice of py::set looks a bit more natural on top of #123063, where the env is changed from a std::unordered_map to a py::dict.
Partially fixes#121422
Pull Request resolved: https://github.com/pytorch/pytorch/pull/124909
Approved by: https://github.com/srikris-sridhar, https://github.com/justinchuby
This PR is part of an effort to speed up torch.onnx.export (#121422).
- This copies the shape and type from the node to the nodes that are produced by the export. However, for 1-to-N exports, which are very common, this doesn't make much sense and can give the graph in broken shape or type information. As far as I can tell, a shape inference pass is used to propagate the correct shape and type for all interemediate (and final) nodes.
- If there is a situation where this is necessary (shape inference turned off and only 1-to-1 ops are exported ??), perhaps this can be conditionally skipped. It does incur a quadratic cost. Another option is to set a global default for the metadata and
use that for all nodes that get created. Again, this meta data may not make sense for all ops and seems dangerous to do.
- Resolves (8) in #121422.
(partial fix of #121422)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/123027
Approved by: https://github.com/BowenBao
Fixes#88286, Fixes#97160
Repro:
```python
import torch
import io
from torch.utils.checkpoint import checkpoint
class A(torch.nn.Module):
# A supported module.
def __init__(self):
super(A, self).__init__()
self.l1 = torch.nn.Linear(2, 2)
def forward(self, x):
return self.l1(x)
class B(torch.nn.Module):
# This module is not exportable to ONNX because it
# uses gradient-checkpointing. However, its two sub-module's
# are exportable, so ORTModule should be used to compute them.
def __init__(self):
super(B, self).__init__()
self.l1 = torch.nn.Linear(2, 2)
self.a = A()
def forward(self, x):
def custom():
def custom_forward(x_):
return self.a(x_)
return custom_forward
z = self.l1(checkpoint(custom(), x))
return z
torch.onnx.export(
B(),
(torch.randn(2, 2),),
io.BytesIO(),
autograd_inlining=True
)
```
`torch.onnx.export(autograd_inlining=True)` should repro the user error as this is the original execution path.
```bash
Traceback (most recent call last):
File "repro88286.py", line 36, in <module>
torch.onnx.export(
File "<@beartype(torch.onnx.utils.export) at 0x7f0f011faee0>", line 385, in export
File "/opt/pytorch/torch/onnx/utils.py", line 511, in export
_export(
File "/opt/pytorch/torch/onnx/utils.py", line 1576, in _export
graph, params_dict, torch_out = _model_to_graph(
File "<@beartype(torch.onnx.utils._model_to_graph) at 0x7f0f01187dc0>", line 11, in _model_to_graph
File "/opt/pytorch/torch/onnx/utils.py", line 1130, in _model_to_graph
graph, params, torch_out, module = _create_jit_graph(model, args)
File "/opt/pytorch/torch/onnx/utils.py", line 1006, in _create_jit_graph
graph, torch_out = _trace_and_get_graph_from_model(model, args)
File "/opt/pytorch/torch/onnx/utils.py", line 910, in _trace_and_get_graph_from_model
trace_graph, torch_out, inputs_states = torch.jit._get_trace_graph(
File "/opt/pytorch/torch/jit/_trace.py", line 1269, in _get_trace_graph
outs = ONNXTracedModule(f, strict, _force_outplace, return_inputs, _return_inputs_states)(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/pytorch/torch/jit/_trace.py", line 128, in forward
graph, out = torch._C._create_graph_by_tracing(
File "/opt/pytorch/torch/jit/_trace.py", line 119, in wrapper
outs.append(self.inner(*trace_inputs))
File "/opt/pytorch/torch/nn/modules/module.py", line 1502, in _wrapped_call_impl
return self._call_impl(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1511, in _call_impl
return forward_call(*args, **kwargs)
File "/opt/pytorch/torch/nn/modules/module.py", line 1492, in _slow_forward
result = self.forward(*input, **kwargs)
File "repro88286.py", line 32, in forward
z = self.l1(checkpoint(custom(), x))
File "/opt/pytorch/torch/utils/checkpoint.py", line 412, in checkpoint
return CheckpointFunction.apply(function, preserve, *args)
File "/opt/pytorch/torch/autograd/function.py", line 506, in apply
return super().apply(*args, **kwargs) # type: ignore[misc]
RuntimeError: _Map_base::at
```
By using `autograd_inlining=False`, the export still fail with a different error because autograd inlining is not enabled:
```bash
Traceback (most recent call last):
File "repro88286.py", line 36, in <module>
torch.onnx.export(
File "<@beartype(torch.onnx.utils.export) at 0x7f6088b32ee0>", line 385, in export
File "/opt/pytorch/torch/onnx/utils.py", line 511, in export
_export(
File "/opt/pytorch/torch/onnx/utils.py", line 1615, in _export
) = graph._export_onnx( # type: ignore[attr-defined]
RuntimeError: ONNX export failed: Couldn't export Python operator CheckpointFunction
```
To allow `CheckpointFunction` into the onnx graph, `operator_export_type=torch.onnx.OperatorExportTypes.ONNX_FALLTHROUGH` flag can be added to `torch.onnx.export`, which would lead to the following ONNX graph:
```bash
Exported graph: graph(%prim::PythonOp_0 : Float(2, 2, strides=[2, 1], requires_grad=0, device=cpu),
%l1.weight : Float(2, 2, strides=[2, 1], requires_grad=1, device=cpu),
%l1.bias : Float(2, strides=[1], requires_grad=1, device=cpu)):
%/PythonOp_output_0 : Float(2, 2, strides=[2, 1], requires_grad=0, device=cpu) = ^CheckpointFunction[inplace=0, module="torch.utils.checkpoint", onnx_name="/PythonOp"](<function B.forward.<locals>.custom.<locals>.custom_forward at 0x7fdf9182f670>, True)(%prim::PythonOp_0), scope: __main__.B:: # /opt/pytorch/torch/autograd/function.py:506:0
%6 : Float(2, 2, strides=[2, 1], requires_grad=1, device=cpu) = onnx::Gemm[alpha=1., beta=1., transB=1, onnx_name="/l1/Gemm"](%/PythonOp_output_0, %l1.weight, %l1.bias), scope: __main__.B::/torch.nn.modules.linear.Linear::l1 # /opt/pytorch/torch/nn/modules/linear.py:114:0
return (%6)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/104067
Approved by: https://github.com/BowenBao, https://github.com/kit1980
`setType` API is not respected in current exporter because the graph-level shape type inference simply overrides every NOT ONNX Op shape we had from node-level shape type inference. To address this issue, this PR (1) makes custom Op with `setType` **reliable** in ConstantValueMap to secure its shape/type information in pass: _C._jit_pass_onnx. (2) If an invalid Op with shape/type in pass: _C._jit_pass_onnx_graph_shape_type_inference(graph-level), we recognize it as reliable.
1. In #62856, The refactor in onnx.cpp made regression on custom Op, as that was the step we should update custom Op shape/type information into ConstantValueMap for remaining Ops.
2. Add another condition besides IsValidONNXNode for custom Op setType in shape_type_inference.cpp. If all the node output has shape (not all dynamic), we say it's custom set type.
3. ~However, this PR won't solve the [issue](https://github.com/pytorch/pytorch/issues/87738#issuecomment-1292831219) that in the node-level shape type inference, exporter invokes the warning in terms of the unknow custom Op, since we process its symbolic_fn after this warning, but it would have shape/type if setType is used correctly. And that will be left for another issue to solve. #84661~ Add `no_type_warning` in UpdateReliable() and it only warns if non ONNX node with no given type appears.
Fixes#81693Fixes#87738
NOTE: not confident of this not breaking anything. Please share your thoughts if there is a robust test on your mind.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88622
Approved by: https://github.com/BowenBao
Avoid passing raw pointer of 'torch::jit::Graph' to python. Otherwise, it will corrupt the
`internals::registered_instance` of pybind11, caching a holder for python w.r.t the raw
pointer of 'torch::jit::Graph', while not increasing the use count of the existing shared_ptr.
The behavior afterwards is random and probably undefined.
Most of the time it works, if the holder is deallocated timely on python side, and the
cache then cleared from `internals::registered_instance`. Things are back to normal.
Otherwise, it fails with either segfault or a runtime error of message "Unable to cast
from non-held to held instance". One of such scenarios is normally and correctly
returning a shared_ptr of that 'torch::jit::Graph' to python. Pybind finds the holder via
cache. Due to this, the shared_ptr use_count will not increase. If there is no other use
on C++ side, the graph will be freed, while python still has access, via the holder created
previously.
@t-vi had a great analysis and solution to this exact problem at #51833 which I hope
I had seen before debugging this issue... ~~I'm building the PR based on the original
commit. @t-vi please let me know if you'd prefer otherwise.~~ Sending the PR separately
due to CLA issues.
Need to check in CI if adding `enable_shared_from_this` breaks other stuff.
Fixes#51833, and CI issues in #87258, #86182.
cc @malfet, @kit1980 for changes on JIT IR.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/87343
Approved by: https://github.com/justinchuby, https://github.com/AllenTiTaiWang, https://github.com/malfet
## Summary
The change brings the new registry for symbolic functions in ONNX. The `SymbolicRegistry` class in `torch.onnx._internal.registration` replaces the dictionary and various functions defined in `torch.onnx.symbolic_registry`.
The new registry
- Has faster lookup by storing only functions in the opset version they are defined in
- Is easier to manage and interact with due to its class design
- Builds the foundation for the more flexible registration process detailed in #83787
Implementation changes
- **Breaking**: Remove `torch.onnx.symbolic_registry`
- `register_custom_op_symbolic` and `unregister_custom_op_symbolic` in utils maintain their api for compatibility
- Update _onnx_supported_ops.py for doc generation to include quantized ops.
- Update code to register python ops in `torch/csrc/jit/passes/onnx.cpp`
## Profiling results
-0.1 seconds in execution time. -34% time spent in `_run_symbolic_function`. Tested on the alexnet example in public doc.
### After
```
└─ 1.641 export <@beartype(torch.onnx.utils.export) at 0x7f19be17f790>:1
└─ 1.641 export torch/onnx/utils.py:185
└─ 1.640 _export torch/onnx/utils.py:1331
├─ 0.889 _model_to_graph torch/onnx/utils.py:1005
│ ├─ 0.478 _optimize_graph torch/onnx/utils.py:535
│ │ ├─ 0.214 PyCapsule._jit_pass_onnx_graph_shape_type_inference <built-in>:0
│ │ │ [2 frames hidden] <built-in>
│ │ ├─ 0.190 _run_symbolic_function torch/onnx/utils.py:1670
│ │ │ └─ 0.145 Constant torch/onnx/symbolic_opset9.py:5782
│ │ │ └─ 0.139 _graph_op torch/onnx/_patch_torch.py:18
│ │ │ └─ 0.134 PyCapsule._jit_pass_onnx_node_shape_type_inference <built-in>:0
│ │ │ [2 frames hidden] <built-in>
│ │ └─ 0.033 [self]
```
### Before
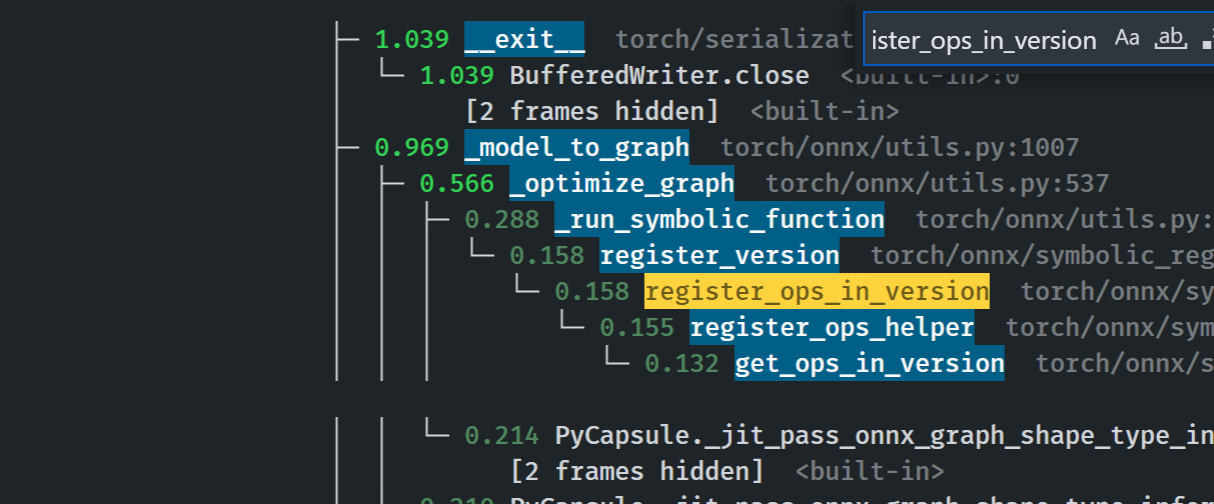
### Start up time
The startup process takes 0.03 seconds. Calls to `inspect` will be eliminated when we switch to using decorators for registration in #84448

Pull Request resolved: https://github.com/pytorch/pytorch/pull/84382
Approved by: https://github.com/AllenTiTaiWang, https://github.com/BowenBao
Add flag (inline_autograd) to enable inline export of model consisting of autograd functions. Currently, this flag should only be used in TrainingMode.EVAL and not for training.
An example:
If a model containing ``autograd.Function`` is as follows
```
class AutogradFunc(torch.autograd.Function):
@staticmethod
def forward(ctx, i):
result = i.exp()
result = result.log()
ctx.save_for_backward(result)
return result
```
Then the model is exported as
```
graph(%0 : Float):
%1 : Float = ^AutogradFunc(%0)
return (%1)
```
If inline_autograd is set to True, this will be exported as
```
graph(%0 : Float):
%1 : Float = onnx::Exp(%0)
%2 : Float = onnx::Log(%1)
return (%2)
```
If one of the ops within the autograd module is not supported, that particular node is exported as is mirroring ONNX_FALLTHROUGH mode
Fixes: #61813
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74765
Approved by: https://github.com/BowenBao, https://github.com/malfet
Reduce circular dependencies
- Lift constants and flags from `symbolic_helper` to `_constants` and `_globals`
- Standardized constant naming to make it consistant
- Make `utils` strictly dependent on `symbolic_helper`, removing inline imports from symbolic_helper
- Move side effects from `utils` to `_patch_torch`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77142
Approved by: https://github.com/garymm, https://github.com/BowenBao
Summary:
Add ONNX exporter logging facility. Supporting both C++/Python logging api. Logging can be turned on/off. Logging output stream can be either set to `stdout` or `stderr`.
A few other changes:
* When exception is raised in passes, the current IR graph being processed will be logged.
* When exception is raised from `_jit_pass_onnx` (the pass that converts nodes from namespace `ATen` to `ONNX`), both ATen IR graph and ONNX IR graph under construction will be logged.
* Exception message for ConstantFolding is truncated to avoid being too verbose.
* Update the final printed IR graph with node name in ONNX ModelProto as node attribute. Torch IR Node does not have name. Adding this to printed IR graph helps debugging.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71342
Reviewed By: msaroufim
Differential Revision: D34433473
Pulled By: malfet
fbshipit-source-id: 4b137dfd6a33eb681a5f2612f19aadf5dfe3d84a
(cherry picked from commit 67a8ebed5192c266f604bdcca931df6fe589699f)
Summary:
To release constants computed and stored by `ConstantValueMap::SetValue(...)` during ONNX exporting, `ConstantValueMap::Clear()` needs to be called explicitly. Otherwise, it's a memory leak.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68210
Reviewed By: jansel
Differential Revision: D32465670
Pulled By: msaroufim
fbshipit-source-id: 521e474071b94c5d2cd4f353ee062cee78be1bd4
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67275
Specifically targets the symbolic functions that directly returns input as output. The old logic will override the value name with output value name. But since the input is unmodified and unchanged, it is more logically to keep its original input name. Especially for cases where inputs are directly from model parameters.
Test Plan: Imported from OSS
Reviewed By: msaroufim
Differential Revision: D31962517
Pulled By: malfet
fbshipit-source-id: 9cb4a2bb55aa08dd1ce8fdec24e7cfb11d7ea97c
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66140
* Add new argument to export api to enable users specifying `nn.Module` classes that they wish to be exported as local function in ONNX model.
* Refactor `torch/csrc/jit/serialization/export.cpp`, and remove redundant `EncoderBase` class.
* ~~Contains changes from #63268~~
* Depends on #63716 to update onnx submodule.
Test Plan: Imported from OSS
Reviewed By: jansel
Differential Revision: D31424098
fbshipit-source-id: c949d0b01c206c30b4182c2dd1a5b90e32b7a0d3
Co-authored-by: BowenBao <bowbao@microsoft.com>
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45255
Mostly straightforward. Only downside in this PR is the lack of more scalable way to check for all newly-created nodes in `callPySymbolicFunction`. The other options were:
* Create a scope within the node's scope and loop through all nodes that correspond to the scope. The code would still need to loop through all nodes.
* Add extra state to the graph (no good reason to do so).
* Add extra state to the ONNX exporter, since python calls go back to `g.op(...)` (no good reason to do so, also not very pythonic).
cc BowenBao neginraoof
Pull Request resolved: https://github.com/pytorch/pytorch/pull/45256
Reviewed By: malfet, houseroad
Differential Revision: D31744281
Pulled By: msaroufim
fbshipit-source-id: 1b63f6e7f02ed61b3a9b7ac3d0be0a3a203c8ff6
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65345
FooType::get() can return a const reference. Inconveniently, converting shared_ptr<FooType> to shared_ptr<Type> requires a copy & refcount bump, so to properly take advantage of this in unshapedType() we need to take a const Type& in isSubtypeOf(), which is good practice anyway -- don't require a shared_ptr if you don't need to take ownership.
ghstack-source-id: 140044165
Test Plan:
CI
perf says c10::unshapedType time decreased from 2.8% to 2.2% during static runtime startup, though I expect this to be generally beneficial.
Reviewed By: hlu1
Differential Revision: D31027361
fbshipit-source-id: 676feb81db9f74ad7b8651d8774f4ecb4cfa6ab8
Summary:
* Minor: spelling, grammar.
* Add calls to `GRAPH_DUMP()` where they were missing.
* Add or expand a few comments.
* Move a few comments to seemingly more appropriate spots.
* In canonicalize_graph_fuser_ops.cpp inline `runnableInputs()` since it
was only called in one place and had a misleading comment and
confusing name.
* In `PeepholeOptimizeImpl::optimizeBlock()`, set `changed = true;` when
removing `aten::is_complex`. Pretty sure its absence was a bug.
* Delete unused `_jit_pass_remove_inplace_ops` and and its
implementation `RemoveInplaceOps()`.
* In `preprocessCaffe2Ops()`, remove redundant check for nested optional
types. It was already checked in `checkONNXCompatibility()`.
* In `EncoderBase::AddAttribute`, log the unexpected attribute kind.
I don't remember the repro case now but I did hit this error at some
point and this additional logging made it easier to understand.
* In `fuseConvBatchNorm()` in eval_peephole.cpp, consistently use
camelCase instead of snake_case for local variables.
* Add curly braces around the bodies of if and loops.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60390
Reviewed By: Krovatkin
Differential Revision: D29523283
Pulled By: SplitInfinity
fbshipit-source-id: 4e16c5648616f53da07d68dab7fdf252e06a0752
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53307
This PR did symbolic shape inference, in the onnx pass _jit_pass_onnx_graph_shape_type_inference.
It creates a singleton ConstantValueMap.
It leverages constant folding technique and did a per-op based handling for ConstantValueMap.
As a byproduct, it enables fold_if pass for dynamic axes cases, typically for faster-rcnn etc.
The core change is in `torch/csrc/jit/passes/onnx/shape_type_inference.cpp` and `torch/csrc/jit/passes/onnx/constant_map.cpp`.
We usually need copy tensor to store in the ConstantValueMap, otherwise the underlying value may change. I see this issue in (1) from_blob (2) get value from Constant node.
Test Plan: Imported from OSS
Reviewed By: pbelevich, malfet
Differential Revision: D26922414
Pulled By: SplitInfinity
fbshipit-source-id: 7654dc13d1de8d9496ad4be89f1454260d7bdeb0
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/53304
With the introduction of ONNX shape inference, shape and type are inferred on the fly as operators get converted from ATen to ONNX when running symbolic function. This resolves the shape/type requirement for the symbolic functions. The pre-onnx passes however, can not be supported by shape inference, since at that stage the operators in the graph are still ATen operators.
This PR is to update the design of ONNX pass, to enable a mechanism of capturing subgraphs of ATen operators of certain patterns, and convert them later, when shape/type information of upstream operators are available.
The new design will require pre-onnx passes that need shape/type to be written in two parts, encapsulation and conversion.
The encapsulation part will find the nodes of patterns, like how pre-onnx passes were written previously. But instead of converting the nodes, it will encapsulate them into a sub-block of a new placeholder node. This part is called before onnx pass, so it runs before calling symbolic functions.
The conversion part will be called inside the onnx pass. In onnx pass, run_symbolic_func will be called for each node in topological order. When it reaches the placeholder node, the conversion part will be invoked. It will convert the nodes inside the sub-block based on pattern. By that time, it will have shape/type of upstream operators available. After the conversion is complete, the placeholder node will be removed, and nodes inside its sub-block converted. Run_symbolic_func will be called for these nodes, and they will be converted from ATen operator to ONNX operator.
This PR includes several other fixes, listed below.
* ~~replace helper.cpp with onnx_utils.cpp for holding utility functions.~~
* fix EraseNumberTypes on Bool type, the code was outdated that back then Bool type doesn't exist.
* ~~enable onnx shape inference in export with parameter/initializer data.~~
* other code clean ups.
* fix insertion of identity nodes for loop opset 13 sequence output.
~~PR depends on #51603~~
Test Plan: Imported from OSS
Reviewed By: SplitInfinity
Differential Revision: D26922417
Pulled By: malfet
fbshipit-source-id: 14ed06158d539e2451c2e5e63ba1b32fb0f75095
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/50229
`fastmod -m 'cast(<((at|c10)::)?\w+Type>\(\)\s*)->' 'castRaw${1}->'` Presuming it builds, this is a safe change: the
result of `cast()` wasn't being saved anywhere, so we didn't need
it, so we can use a raw pointer instead of a new `shared_ptr`.
ghstack-source-id: 120769170
Test Plan: CI
Reviewed By: SplitInfinity
Differential Revision: D25837494
fbshipit-source-id: 46319100dc0dfc78f6d2b45148207f83481f2ada
Summary:
* Support sequence type (de)serialization, enables onnx shape inference on sequence nodes.
* Fix shape inference with block input/output: e.g. Loop and If nodes.
* Fix bugs in symbolic discovered by coverage of onnx shape inference.
* Improve debuggability: added more jit logs. For simplicity, the default log level, when jit log is enabled, will not dump ir graphs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/43929
Reviewed By: albanD
Differential Revision: D23674604
Pulled By: bzinodev
fbshipit-source-id: ab6aacb16d0e3b9a4708845bce27c6d65e567ba7
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/36345
During compilation, we spend a huge amount of time in alias analyis.
This PR does a few things to speed it up.
1. Separate the analysis into two phases: one where we build up the
necessary data structures, and the other where we service aliasing
queries. This allows us to defer building indices/maintaining index
consistency until after the "buildup" phase is done.
2. Properly memoize/dynamic program the memory locations lookups.
3. Done naively, setting wildcards invalidates the above memoization,
trigger costly recomputation. So I added a cache-aware `setWildcards`.
Sadly that means you need alias analysis to reach into the guts of
memorydag, but the speedup is worth it.
Sadly, these changes are kind of coupled for correctness reasons, so
they're all here at once.
I used this model (thanks IlyaOvodov) as a provisional benchmark. You
can get it here:
https://www.dropbox.com/s/jlyygn6yygj1jkx/yolov3.zip. Unzip at run
`python test_timing.py`.
Baseline: (752.076s) right before 6bc8ffe824
After optimizing before inlining: (699.593s)
After deferring cache construction: (426.180s)
After cache-aware `setWildcards`: (193.678s)
So a nice 75% speedup to overall compilation. There's a lot more to do
in other places of the compilation pipeline though.
Followup to this PR specifically: Everything that fans out from the
`analyze` call is the "buildup" phase of AliasDB construction. This
should be factored into a separate analysis pass to statically
distinguish the two phases (right now we just null out stuff to
accomplish the same thing dynamically).
Test Plan: Imported from OSS
Differential Revision: D20952727
Pulled By: suo
fbshipit-source-id: 099f797222d7e71e5c04991584adc2c7eab5a70f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/35115
This commit runs the newly added tools/clang_format.py on the JIT
codebase and includes all of the formatting changes thus produced.
Testing:
Ran the script, CI.
Test Plan: Imported from OSS
Reviewed By: eellison
Differential Revision: D20568523
Pulled By: SplitInfinity
fbshipit-source-id: e09bdb982ccf090eecfb7c7b461b8d0681eef82b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31841
Add Tuple Constants to JIT. The constraint here is that all elements of a tuple must themself be insertable as a a constant. Previously tuples were special cased in constant propagation, but now that there are more passes that are inserted constants, such as freezing, we should just have tuples be representable as constants.
Test Plan: Imported from OSS
Differential Revision: D19439514
Pulled By: eellison
fbshipit-source-id: 3810ba08ee349fa5598f4b53ea64525996637b1a
{kind=link}
{kind=link}