Fixes the string_view errors and reland the work. The previous changes in torch/csrc/utils/invalid_arguments.cpp were too aggressive and not tested thoroughly. They are discarded.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/110518
Approved by: https://github.com/ezyang
Fixes#106698
Also added a check for python API, because current error message
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/sehoon/pytorch-latest/torch/nn/modules/adaptive.py", line 128, in __init__
or (min(cutoffs) <= 0) \
ValueError: min() arg is an empty sequence
```
is not very comprehensible.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/106777
Approved by: https://github.com/albanD
This PR replace c10::guts::to_string with std::to_string. The major part of changes is using void* as optimizer state key since string is used only for serialization and using pointers as hashing keys is more efficient than a string.
Some other guts functions in the affected source files are also replaced.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/108480
Approved by: https://github.com/Skylion007
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 4f0b524</samp>
This pull request updates the codebase and the documentation to use C++17 instead of C++14 as the minimum required C++ standard. This affects the `ATen`, `c10`, and `torch` libraries and their dependencies, as well as the CI system and the `conda` package metadata.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100557
Approved by: https://github.com/malfet
Hello!
Recently i was playing with LibTorch libs, but i noticed that currently there is only one LR Scheduler implementation available. I needed 'Reduce on plateau scheduler', so implemented it by myself. Used it a lot of times, and it seem work as it should, so decided to share my implementation here.
If u will decide that this is something worth to merge, or it needs tweaking/tests let me know!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100311
Approved by: https://github.com/albanD
<!--
copilot:summary
-->
### <samp>🤖 Generated by Copilot at 4f0b524</samp>
This pull request updates the codebase and the documentation to use C++17 instead of C++14 as the minimum required C++ standard. This affects the `ATen`, `c10`, and `torch` libraries and their dependencies, as well as the CI system and the `conda` package metadata.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/100557
Approved by: https://github.com/malfet
This diff locks in C++17 as the minimum standard with which PyTorch can be compiled.
This makes it possible to use all C++17 features in PyTorch.
This breaks backward compatibility in the sense that users with older compilers may find their compilers no longer are sufficient for the job.
Summary: #buildmore
Differential Revision: D44356879
Pull Request resolved: https://github.com/pytorch/pytorch/pull/98209
Approved by: https://github.com/ezyang, https://github.com/malfet, https://github.com/PaliC
Number of OSS PR were reverted, because new signed-unsigned comparison warnings, which are treated as errors in some internal builds.
Not sure how those selective rules are applied, but this PR removes `-Wno-sign-compare` from PyTorch codebase.
The only tricky part in this PR, as making sure that non-ASCII character detection works for both signed and unsigned chars here:
6e3d51b08a/torch/csrc/jit/serialization/python_print.cpp (L926)
Exclude several files from sign-compare if flash attention is used, due to the violation in cutlass, to be fixed by https://github.com/NVIDIA/cutlass/pull/869
Do not try to fix sign compare violations in caffe2 codebase
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96723
Approved by: https://github.com/albanD
Fixes#95796
### Implementation
Adds python implementation for `nn.ZeroPad1d` and `nn.ZeroPad3d` in `torch/nn/modules/padding.py`.
Adds cpp implementation for `nn::ZeroPad1d` and `nn::ZeroPad3d` in the following 3 files, refactored with templates similarly to `nn::ConstantPad`'s implementation: <br>
- `torch/crsc/api/include/torch/nn/modules/padding.h`
- `torch/csrc/api/include/torch/nn/options/padding.h`
- `torch/csrc/api/src/nn/modules/padding.cpp`
Also added relevant definitions in `torch/nn/modules/__init__.py`.
### Testing
Adds the following tests:
- cpp tests of similar length and structure as `ConstantPad` and the existing `ZeroPad2d` impl in `test/cpp/api/modules.cpp`
- cpp API parity tests in `torch/testing/_internal/common_nn.py`
- module init tests in `test/test_module_init.py`
Also added relevant definitions in `test/cpp_api_parity/parity-tracker.md`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/96295
Approved by: https://github.com/soulitzer
This PR introduces some modifications:
1. We find out some const function parameters that can be passed by reference and add the reference.
2. We find more opportunists of passing by value and change them accordingly.
3. Some use-after-move errors are fixed.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/95942
Approved by: https://github.com/Skylion007
Not only is this change usually shorter and more readable, it also can yield better performance. size() is not always a constant time operation (such as on LinkedLists), but empty() always is.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/93236
Approved by: https://github.com/malfet
Attempts to fix#92656
BC-breaking! This changes the default of zero_grad in optim and in nn to default set grads to None instead of zero tensors. We are changing the default because there are proven perf wins and existing code has typically not regressed due to this change. (will probably have to flesh out this note more).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92731
Approved by: https://github.com/ngimel
Summary:
A lot of other libraries have their own `xyz::Tensor` data structure. Under some rare cases, when they interop with torch, there will be compilation error such as
```
torch/csrc/api/include/torch/data/samplers/random.h(49): error: "Tensor" is ambiguous
```
Making some of the `Tensor` namespace clear will resolve this.
Test Plan: CI
Differential Revision: D42538675
Pull Request resolved: https://github.com/pytorch/pytorch/pull/92266
Approved by: https://github.com/Skylion007, https://github.com/malfet
Apply clang-tidy check modernize-use-emplace. This is slightly more efficient by using an inplace constructor and is the recommended style in parts of the codebase covered by clang-tidy. This just manually applies the check to rest of the codebase. Pinging @ezyang as this is related to my other PRs he reviewed like #89000
Pull Request resolved: https://github.com/pytorch/pytorch/pull/91077
Approved by: https://github.com/ezyang
Summary: This diff merges both previous implementations of constructors for nested tensors, the one from lists of tensors and the one with arbitrary python lists, adn implements it in pytorch core so no extensions are needed to construct NT.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/88213
Approved by: https://github.com/cpuhrsch
Summary:
This header is being included from both aten/native and torch/csrc, but
some of our build configurations don't allow direct dependencies from
torch/csrc to atent/native, so put the header in aten where it's always
accessible.
Resolves https://github.com/pytorch/pytorch/issues/81198
Test Plan:
CI.
```
./scripts/build_android.sh
env ANDROID_ABI="x86_64" ANDROID_NDK=".../ndk-bundle" CMAKE_CXX_COMPILER_LAUNCHER=ccache CMAKE_C_COMPILER_LAUNCHER=ccache USE_VULKAN=0 ./scripts/build_android.sh
echo '#include <torch/torch.h>' > test.cpp
g++ -E -I $PWD/build_android/install/include/ -I $PWD/build_android/install/include/torch/csrc/api/include test.cpp >/dev/null
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82379
Approved by: https://github.com/ezyang, https://github.com/malfet
We define specializations for pybind11 defined templates
(in particular, PYBIND11_DECLARE_HOLDER_TYPE) and consequently
it is important that these specializations *always* be #include'd
when making use of pybind11 templates whose behavior depends on
these specializations, otherwise we can cause an ODR violation.
The easiest way to ensure that all the specializations are always
loaded is to designate a header (in this case, torch/csrc/util/pybind.h)
that ensures the specializations are defined, and then add a lint
to ensure this header is included whenever pybind11 headers are
included.
The existing grep linter didn't have enough knobs to do this
conveniently, so I added some features. I'm open to suggestions
for how to structure the features better. The main changes:
- Added an --allowlist-pattern flag, which turns off the grep lint
if some other line exists. This is used to stop the grep
lint from complaining about pybind11 includes if the util
include already exists.
- Added --match-first-only flag, which lets grep only match against
the first matching line. This is because, even if there are multiple
includes that are problematic, I only need to fix one of them.
We don't /really/ need this, but when I was running lintrunner -a
to fixup the preexisting codebase it was annoying without this,
as the lintrunner overall driver fails if there are multiple edits
on the same file.
I excluded any files that didn't otherwise have a dependency on
torch/ATen, this was mostly caffe2 and the valgrind wrapper compat
bindings.
Note the grep replacement is kind of crappy, but clang-tidy lint
cleaned it up in most cases.
See also https://github.com/pybind/pybind11/issues/4099
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82552
Approved by: https://github.com/albanD
unflatten now has a free function version in torch.flatten in addition to
the method in torch.Tensor.flatten.
Updated docs to reflect this and polished them a little.
For consistency, changed the signature of the int version of unflatten in
native_functions.yaml.
Some override tests were failing because unflatten has unusual
characteristics in terms of the .int and .Dimname versions having
different number of arguments so this required some changes
to test/test_override.py
Removed support for using mix of integer and string arguments
when specifying dimensions in unflatten.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81399
Approved by: https://github.com/Lezcano, https://github.com/ngimel
This PR heavily simplifies the code of `linalg.solve`. At the same time,
this implementation saves quite a few copies of the input data in some
cases (e.g. A is contiguous)
We also implement it in such a way that the derivative goes from
computing two LU decompositions and two LU solves to no LU
decompositions and one LU solves. It also avoids a number of unnecessary
copies the derivative was unnecessarily performing (at least the copy of
two matrices).
On top of this, we add a `left` kw-only arg that allows the user to
solve `XA = B` rather concisely.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74046
Approved by: https://github.com/nikitaved, https://github.com/IvanYashchuk, https://github.com/mruberry
```Python
chebyshev_polynomial_v(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the third kind $V_{n}(\text{input})$.
```Python
chebyshev_polynomial_w(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the fourth kind $W_{n}(\text{input})$.
```Python
legendre_polynomial_p(input, n, *, out=None) -> Tensor
```
Legendre polynomial $P_{n}(\text{input})$.
```Python
shifted_chebyshev_polynomial_t(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the first kind $T_{n}^{\ast}(\text{input})$.
```Python
shifted_chebyshev_polynomial_u(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the second kind $U_{n}^{\ast}(\text{input})$.
```Python
shifted_chebyshev_polynomial_v(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the third kind $V_{n}^{\ast}(\text{input})$.
```Python
shifted_chebyshev_polynomial_w(input, n, *, out=None) -> Tensor
```
Shifted Chebyshev polynomial of the fourth kind $W_{n}^{\ast}(\text{input})$.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78304
Approved by: https://github.com/mruberry
Adds:
```Python
bessel_j0(input, *, out=None) -> Tensor
```
Bessel function of the first kind of order $0$, $J_{0}(\text{input})$.
```Python
bessel_j1(input, *, out=None) -> Tensor
```
Bessel function of the first kind of order $1$, $J_{1}(\text{input})$.
```Python
bessel_j0(input, *, out=None) -> Tensor
```
Bessel function of the second kind of order $0$, $Y_{0}(\text{input})$.
```Python
bessel_j1(input, *, out=None) -> Tensor
```
Bessel function of the second kind of order $1$, $Y_{1}(\text{input})$.
```Python
modified_bessel_i0(input, *, out=None) -> Tensor
```
Modified Bessel function of the first kind of order $0$, $I_{0}(\text{input})$.
```Python
modified_bessel_i1(input, *, out=None) -> Tensor
```
Modified Bessel function of the first kind of order $1$, $I_{1}(\text{input})$.
```Python
modified_bessel_k0(input, *, out=None) -> Tensor
```
Modified Bessel function of the second kind of order $0$, $K_{0}(\text{input})$.
```Python
modified_bessel_k1(input, *, out=None) -> Tensor
```
Modified Bessel function of the second kind of order $1$, $K_{1}(\text{input})$.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78451
Approved by: https://github.com/mruberry
Adds:
```Python
chebyshev_polynomial_t(input, n, *, out=None) -> Tensor
```
Chebyshev polynomial of the first kind $T_{n}(\text{input})$.
If $n = 0$, $1$ is returned. If $n = 1$, $\text{input}$ is returned. If $n < 6$ or $|\text{input}| > 1$ the recursion:
$$T_{n + 1}(\text{input}) = 2 \times \text{input} \times T_{n}(\text{input}) - T_{n - 1}(\text{input})$$
is evaluated. Otherwise, the explicit trigonometric formula:
$$T_{n}(\text{input}) = \text{cos}(n \times \text{arccos}(x))$$
is evaluated.
## Derivatives
Recommended $k$-derivative formula with respect to $\text{input}$:
$$2^{-1 + k} \times n \times \Gamma(k) \times C_{-k + n}^{k}(\text{input})$$
where $C$ is the Gegenbauer polynomial.
Recommended $k$-derivative formula with respect to $\text{n}$:
$$\text{arccos}(\text{input})^{k} \times \text{cos}(\frac{k \times \pi}{2} + n \times \text{arccos}(\text{input})).$$
## Example
```Python
x = torch.linspace(-1, 1, 256)
matplotlib.pyplot.plot(x, torch.special.chebyshev_polynomial_t(x, 10))
```
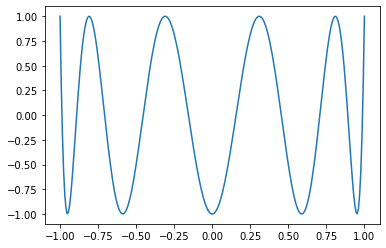
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78196
Approved by: https://github.com/mruberry
`nn.Transformer` is not possible to be used to implement BERT, while `nn.TransformerEncoder` does. So this PR moves the sentence 'Users can build the BERT model with corresponding parameters.' from `nn.Transformer` to `nn.TransformerEncoder`.
Fixes#68053
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78337
Approved by: https://github.com/jbschlosser
Euler beta function:
```Python
torch.special.beta(input, other, *, out=None) → Tensor
```
`reentrant_gamma` and `reentrant_ln_gamma` implementations (using Stirling’s approximation) are provided. I started working on this before I realized we were missing a gamma implementation (despite providing incomplete gamma implementations). Uses the coefficients computed by Steve Moshier to replicate SciPy’s implementation. Likewise, it mimics SciPy’s behavior (instead of the behavior in Cephes).
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78031
Approved by: https://github.com/mruberry
This PR modifies `lu_unpack` by:
- Using less memory when unpacking `L` and `U`
- Fuse the subtraction by `-1` with `unpack_pivots_stub`
- Define tensors of the correct types to avoid copies
- Port `lu_unpack` to be a strucutred kernel so that its `_out` version
does not incur on extra copies
Then we implement `linalg.lu` as a structured kernel, as we want to
compute its derivative manually. We do so because composing the
derivatives of `torch.lu_factor` and `torch.lu_unpack` would be less efficient.
This new function and `lu_unpack` comes with all the things it can come:
forward and backward ad, decent docs, correctness tests, OpInfo, complex support,
support for metatensors and support for vmap and vmap over the gradients.
I really hope we don't continue adding more features.
This PR also avoids saving some of the tensors that were previously
saved unnecessarily for the backward in `lu_factor_ex_backward` and
`lu_backward` and does some other general improvements here and there
to the forward and backward AD formulae of other related functions.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67833
Approved by: https://github.com/IvanYashchuk, https://github.com/nikitaved, https://github.com/mruberry
This functionality does not seem to be used
and there are some requests to update dependency.
Add `third_party` to torch_cpu include directories if compiling with
Caffe2 support, as `caffe2/quantization/server/conv_dnnlowp_op.cc` depends on `third_party/fbgemm/src/RefImplementations.h`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75394
Approved by: https://github.com/janeyx99, https://github.com/seemethere
This PR adds a function for computing the LDL decomposition and a function that can solve systems of linear equations using this decomposition. The result of `torch.linalg.ldl_factor_ex` is in a compact form and it's required to use it only through `torch.linalg.ldl_solve`. In the future, we could provide `ldl_unpack` function that transforms the compact representation into explicit matrices.
Fixes https://github.com/pytorch/pytorch/issues/54847.
cc @jianyuh @nikitaved @pearu @mruberry @walterddr @IvanYashchuk @xwang233 @Lezcano
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69828
Approved by: https://github.com/Lezcano, https://github.com/mruberry, https://github.com/albanD
Closes#44459
This migrates the python implementation of `_pad_circular` to ATen and
removes the old C++ implementation that had diverged from python.
Note that `pad` can't actually use this until the
forward-compatibility period is over.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73410
Approved by: https://github.com/ezyang
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/73378
1) ran check_for_c10_loops.py to automatically update all files (*.h, *.hpp, *.cpp) under fbcode/caffe2/torch (this is the path in the check_for_c10_loops.py, slightly different from the task description where the path mentioned was fbcode/caffe2. since current commit already contains 27 files, will use a separate commit for additional files).
2) manually reviewed each change, and reverted a few files:
(a) select_keys.cpp, bucketize_calibration.cpp, index_mmh and TCPStore.cpp: iterator modified in loop
(b) qlinear_4bit_ops.cpp and id_list_feature_merge_conversion.cpp: condition containing multiple expressions.
Test Plan:
Doing the following (still in progress, will address issues as they appear):
buck build ...
buck test ...
Reviewed By: r-barnes
Differential Revision: D34435473
fbshipit-source-id: b8d3c94768b02cf71ecb24bb58d29ee952f672c2
(cherry picked from commit fa9b0864f3761a501868fe0373204b12fdfc2b32)
Summary:
With this change, the optimizer is almost twice as fast as before. As the result of the first call is never used, it looks like a copy paste error and therefore can be removed. In addition, this duplicate call is not present in the Python implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72773
Reviewed By: samdow
Differential Revision: D34214312
Pulled By: albanD
fbshipit-source-id: 4f4de08633c7236f3ccce8a2a74e56500003281b
(cherry picked from commit 4a63f812ab)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68693
Generation of python bindings for native functions is split over 8
different files. One for each namespace, with the torch namespace
split into 3 shards, and methods in their own file as well. This
change ensures that editing any single (non-method) operator only
causes one of these files to be rebuilt.
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32596270
Pulled By: albanD
fbshipit-source-id: 0570ec69e7476b8f1bc21138ba18fe8f95ebbe3f
(cherry picked from commit ba0fc71a3a)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70326
See D24145988 for context: it allows loops such as for(int i=0;i<10;i++) to be expressed as for(const auto i : c10::irange(10)). This is nice because it auto-types the loops and adds const-safety to the iteration variable.
Test Plan: buck run //caffe2/torch/fb/sparsenn:test
Reviewed By: r-barnes
Differential Revision: D33243400
fbshipit-source-id: b1f1b4163f4bf662031baea9e5268459b40c69a3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: gchanan
Differential Revision: D32834069
Pulled By: mruberry
fbshipit-source-id: 51ef12535fa91d292f419acf83b800b86ee9c7eb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69421
I've hit a lot of build issues in D32671972, and I've come to realize that a lot of it boils down to header hygene. `function.h` includes `profiler.h` *solely* to transitively include `record_function.h` which winds up leaking the profiler symbols. Moreover several files are relying on transitive includes to get access to `getTime`. As long as I have to touch all the places that use `getTime`, I may as well also move them to the new namespace.
Test Plan: Unit tests and CI.
Reviewed By: aaronenyeshi, albanD
Differential Revision: D32865907
fbshipit-source-id: f87d6fd5afb784dca2146436e72c69e34623020e
Summary:
Follow up to https://github.com/pytorch/pytorch/issues/68095
This also changes the files from the ATen folder to include c10's `Export.h` instead since they can't ever be exporting `TORCH_PYTHON_API`.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69585
Reviewed By: mrshenli
Differential Revision: D32958594
Pulled By: albanD
fbshipit-source-id: 1ec7ef63764573fa2b486928955e3a1172150061
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66933
This PR exposes `torch.lu` as `torch.linalg.lu_factor` and
`torch.linalg.lu_factor_ex`.
This PR also adds support for matrices with zero elements both in
the size of the matrix and the batch. Note that this function simply
returns empty tensors of the correct size in this case.
We add a test and an OpInfo for the new function.
This PR also adds documentation for this new function in line of
the documentation in the rest of `torch.linalg`.
Fixes https://github.com/pytorch/pytorch/issues/56590
Fixes https://github.com/pytorch/pytorch/issues/64014
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D32521980
Pulled By: mruberry
fbshipit-source-id: 26a49ebd87f8a41472f8cd4e9de4ddfb7f5581fb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63568
This PR adds the first solver with structure to `linalg`. This solver
has an API compatible with that of `linalg.solve` preparing these for a
possible future merge of the APIs. The new API:
- Just returns the solution, rather than the solution and a copy of `A`
- Removes the confusing `transpose` argument and replaces it by a
correct handling of conj and strides within the call
- Adds a `left=True` kwarg. This can be achieved via transposes of the
inputs and the result, but it's exposed for convenience.
This PR also implements a dataflow that minimises the number of copies
needed before calling LAPACK / MAGMA / cuBLAS and takes advantage of the
conjugate and neg bits.
This algorithm is implemented for `solve_triangular` (which, for this, is
the most complex of all the solvers due to the `upper` parameters).
Once more solvers are added, we will factor out this calling algorithm,
so that all of them can take advantage of it.
Given the complexity of this algorithm, we implement some thorough
testing. We also added tests for all the backends, which was not done
before.
We also add forward AD support for `linalg.solve_triangular` and improve the
docs of `linalg.solve_triangular`. We also fix a few issues with those of
`torch.triangular_solve`.
Resolves https://github.com/pytorch/pytorch/issues/54258
Resolves https://github.com/pytorch/pytorch/issues/56327
Resolves https://github.com/pytorch/pytorch/issues/45734
cc jianyuh nikitaved pearu mruberry walterddr IvanYashchuk xwang233 Lezcano
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D32588230
Pulled By: mruberry
fbshipit-source-id: 69e484849deb9ad7bb992cc97905df29c8915910
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68672
This PR adds `python_module: sparse` to `native_function.yaml`.
These functions would appear in `torch._C._sparse` namespace instead of
just `torch`.
Test Plan: Imported from OSS
Reviewed By: mruberry
Differential Revision: D32517813
fbshipit-source-id: 7c3d6df57a24d7c7354d0fefe1b628dc89be9431
{kind=link}
{kind=link}