Also Back out "Revert D39075159: [acc_tensor] Use SymIntArrayRef for overloaded empty.memory_format's signature"
Original commit changeset: dab4a9dba4fa
Original commit changeset: dcaf16c037a9
Original Phabricator Diff: D38984222
Original Phabricator Diff: D39075159
Also update Metal registrations for C++ registration changes.
Also update NNPI registration to account for tightened schema checking
Differential Revision: [D39084762](https://our.internmc.facebook.com/intern/diff/D39084762/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D39084762/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/84173
Approved by: https://github.com/Krovatkin
Fixes https://github.com/pytorch/pytorch/issues/83505
BC-breaking message:
- Previously we only required input and weight to have the same dtype on cpu (when input is non-complex). After this change, the dtype of bias is now also expected to have the same dtype. This change was necessary to improve the error message for certain combinations of inputs. This behavior now also matches that of convolution on cuda.
<details>
<summary>
Old plan
</summary>
Previously convolution (at least for slow_conv2d) did not perform type promotion, i.e. the output of `conv(int, int, float)` is an int, and that leads to the autograd assert.
This PR adds type promotion handling at the `at::native::conv2d` (this is a composite) level. We also need to correct or remove many tests that assume that conv errors when input types are mixed
Pros:
- Doing type promotion at this level avoids the complex path from having any special handling for mixed dtypes, and can potentially speed up mixed dtype inputs to now dispatch to faster kernels which are only capable of handling floats.
Cons:
- Doing type promotion at this level has the risk of introducing extra overhead when we would've dispatched to a kernel capable of handle mixed type anyway. I don't know if any of these exist at all though - it is possible that inputs with any non-float arguments are dispatched to the slow path.
If this approach is OK, we can proceed with the other convolutions as well:
</details>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83686
Approved by: https://github.com/ngimel
Previously, we introduced new SymInt overloads for every function we wanted. This led to a lot of boilerplate, and also a lot of confusion about how the overloads needed to be implemented.
This PR takes a simpler but more risky approach: just take the original function and changes its ints to SymInts.
This is BC-breaking in the following ways:
* The C++ API for registering implementations for aten operators will change from int64_t to SymInt whenever you make this change. Code generated registrations in PyTorch do not change as codegen handles the translation automatically, but manual registrations will need to follow the change. Typically, if you now accept a SymInt where you previously only took int64_t, you have to convert it back manually. This will definitely break XLA, see companion PR https://github.com/pytorch/xla/pull/3914 Note that not all dispatch keys get the automatic translation; all the composite keys and Meta keys are modified to take SymInt directly (because they should handle them directly), and so there are adjustments for this.
This is not BC-breaking in the following ways:
* The user facing C++ API remains compatible. Even if a function changes from int to SymInt, the default C++ binding still takes only ints. (e.g., at::empty(IntArrayRef, ...). To call with SymInts, you must call at::empty_symint instead. This involved adding two more signatures to CppSignatureGroup; in many cases I refactored code to iterate over all signatures in the group instead of hard-coding the two that previously existed.
* This is TorchScript compatible; internally we treat SymInts as ints so there is no change to what happens at runtime in TorchScript. In particular, it's OK to reference an empty schema by its old type (using int types), as long as you're not doing string equality (which you shouldn't be), these parse to the same underyling type.
Structure of the PR:
* The general strategy of this PR is that, even when you write `SymInt` inside `native_functions.yaml`, sometimes, we will treat it *as if* it were an `int`. This idea pervades the codegen changes, where we have a translation from SymInt to c10::SymInt or int64_t, and this is controlled by a symint kwarg which I added and then audited all call sites to decide which I wanted. Here are some of the major places where we pick one or the other:
* The C++ FunctionSchema representation represents `SymInt` as `int`. There are a few places we do need to know that we actually have a SymInt and we consult `real_type()` to get the real type in this case. In particular:
* When we do schema validation of C++ operator registration, we must compare against true schema (as the C++ API will provide `c10::SymInt`, and this will only be accepted if the schema is `SymInt`. This is handled with cloneWithRealTypes before we check for schema differences.
* In `toIValue` argument parsing, we parse against the true schema value. For backwards compatibility reasons, I do still accept ints in many places where Layout/SymInt/etc were expected. (Well, accepting int where SymInt is expected is not BC, it's just the right logic!)
* In particular, because SymInt never shows up as type() in FunctionSchema, this means that we no longer need a dedicated Tag::SymInt. This is good, because SymInts never show up in mobile anyway.
* Changes to functorch/aten are mostly about tracking changes to the C++ API registration convention. Additionally, since SymInt overloads no longer exist, registrations for SymInt implementations are deleted. In many cases, the old implementations did not properly support SymInts; I did not add any new functionality with this PR, but I did try to annotate with TODOs where this is work to do. Finally, because the signature of `native::` API changed from int to SymInt, I need to find alternative APIs for people who were directly calling these functions to call. Typically, I insert a new dispatch call when perf doesn't matter, or use `at::compositeexplicitautograd` namespace to handle other caes.
* The change to `make_boxed_from_unboxed_functor.h` is so that we accept a plain IntList IValue anywhere a SymIntList is expected; these are read-only arguments so covariant typing is OK.
* I change how unboxing logic works slightly. Previously, we interpret the C++ type for Layout/etc directly as IntType JIT type, which works well because the incoming IValue is tagged as an integer. Now, we interpret the C++ type for Layout as its true type, e.g., LayoutType (change to `jit_type.h`), but then we accept an int IValue for it anyway. This makes it symmetric with SymInt, where we interpret the C++ type as SymIntType, and then accept SymInt and int IValues for it.
* I renamed the `empty.names` overload to `empty_names` to make it less confusing (I kept mixing it up with the real empty overload)
* I deleted the `empty.SymInt` overload, which ended up killing a pile of functions. (This was originally a separate PR but the profiler expect test was giving me grief so I folded it in.)
* I deleted the LazyDynamicOpsTest tests. These were failing after these changes, and I couldn't figure out why they used to be passing: they make use of `narrow_copy` which didn't actually support SymInts; they were immediately converted to ints.
* I bashed LTC into working. The patches made here are not the end of the story. The big problem is that SymInt translates into Value, but what if you have a list of SymInt? This cannot be conveniently represented in the IR today, since variadic Values are not supported. To work around this, I translate SymInt[] into plain int[] (this is fine for tests because LTC dynamic shapes never actually worked); but this will need to be fixed for proper LTC SymInt support. The LTC codegen also looked somewhat questionable; I added comments based on my code reading.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83628
Approved by: https://github.com/albanD, https://github.com/bdhirsh
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [X] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [X] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [X] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [X] [Current PR] `torch.nn.qat` → `torch.ao.nn.qat`
- [X] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [X] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- None
Differential Revision: [D36861197](https://our.internmc.facebook.com/intern/diff/D36861197/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36861197/)!
Differential Revision: [D36861197](https://our.internmc.facebook.com/intern/diff/D36861197)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78716
Approved by: https://github.com/jerryzh168
Previously, we introduced new SymInt overloads for every function we wanted. This led to a lot of boilerplate, and also a lot of confusion about how the overloads needed to be implemented.
This PR takes a simpler but more risky approach: just take the original function and changes its ints to SymInts.
This is BC-breaking in the following ways:
* The C++ API for registering implementations for aten operators will change from int64_t to SymInt whenever you make this change. Code generated registrations in PyTorch do not change as codegen handles the translation automatically, but manual registrations will need to follow the change. Typically, if you now accept a SymInt where you previously only took int64_t, you have to convert it back manually. This will definitely break XLA, see companion PR https://github.com/pytorch/xla/pull/3914 Note that not all dispatch keys get the automatic translation; all the composite keys and Meta keys are modified to take SymInt directly (because they should handle them directly), and so there are adjustments for this.
This is not BC-breaking in the following ways:
* The user facing C++ API remains compatible. Even if a function changes from int to SymInt, the default C++ binding still takes only ints. (e.g., at::empty(IntArrayRef, ...). To call with SymInts, you must call at::empty_symint instead. This involved adding two more signatures to CppSignatureGroup; in many cases I refactored code to iterate over all signatures in the group instead of hard-coding the two that previously existed.
* This is TorchScript compatible; internally we treat SymInts as ints so there is no change to what happens at runtime in TorchScript. In particular, it's OK to reference an empty schema by its old type (using int types), as long as you're not doing string equality (which you shouldn't be), these parse to the same underyling type.
Structure of the PR:
* The general strategy of this PR is that, even when you write `SymInt` inside `native_functions.yaml`, sometimes, we will treat it *as if* it were an `int`. This idea pervades the codegen changes, where we have a translation from SymInt to c10::SymInt or int64_t, and this is controlled by a symint kwarg which I added and then audited all call sites to decide which I wanted. Here are some of the major places where we pick one or the other:
* The C++ FunctionSchema representation represents `SymInt` as `int`. There are a few places we do need to know that we actually have a SymInt and we consult `real_type()` to get the real type in this case. In particular:
* When we do schema validation of C++ operator registration, we must compare against true schema (as the C++ API will provide `c10::SymInt`, and this will only be accepted if the schema is `SymInt`. This is handled with cloneWithRealTypes before we check for schema differences.
* In `toIValue` argument parsing, we parse against the true schema value. For backwards compatibility reasons, I do still accept ints in many places where Layout/SymInt/etc were expected. (Well, accepting int where SymInt is expected is not BC, it's just the right logic!)
* In particular, because SymInt never shows up as type() in FunctionSchema, this means that we no longer need a dedicated Tag::SymInt. This is good, because SymInts never show up in mobile anyway.
* Changes to functorch/aten are mostly about tracking changes to the C++ API registration convention. Additionally, since SymInt overloads no longer exist, registrations for SymInt implementations are deleted. In many cases, the old implementations did not properly support SymInts; I did not add any new functionality with this PR, but I did try to annotate with TODOs where this is work to do. Finally, because the signature of `native::` API changed from int to SymInt, I need to find alternative APIs for people who were directly calling these functions to call. Typically, I insert a new dispatch call when perf doesn't matter, or use `at::compositeexplicitautograd` namespace to handle other caes.
* The change to `make_boxed_from_unboxed_functor.h` is so that we accept a plain IntList IValue anywhere a SymIntList is expected; these are read-only arguments so covariant typing is OK.
* I change how unboxing logic works slightly. Previously, we interpret the C++ type for Layout/etc directly as IntType JIT type, which works well because the incoming IValue is tagged as an integer. Now, we interpret the C++ type for Layout as its true type, e.g., LayoutType (change to `jit_type.h`), but then we accept an int IValue for it anyway. This makes it symmetric with SymInt, where we interpret the C++ type as SymIntType, and then accept SymInt and int IValues for it.
* I renamed the `empty.names` overload to `empty_names` to make it less confusing (I kept mixing it up with the real empty overload)
* I deleted the `empty.SymInt` overload, which ended up killing a pile of functions. (This was originally a separate PR but the profiler expect test was giving me grief so I folded it in.)
* I deleted the LazyDynamicOpsTest tests. These were failing after these changes, and I couldn't figure out why they used to be passing: they make use of `narrow_copy` which didn't actually support SymInts; they were immediately converted to ints.
* I bashed LTC into working. The patches made here are not the end of the story. The big problem is that SymInt translates into Value, but what if you have a list of SymInt? This cannot be conveniently represented in the IR today, since variadic Values are not supported. To work around this, I translate SymInt[] into plain int[] (this is fine for tests because LTC dynamic shapes never actually worked); but this will need to be fixed for proper LTC SymInt support. The LTC codegen also looked somewhat questionable; I added comments based on my code reading.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/83628
Approved by: https://github.com/albanD, https://github.com/bdhirsh
Context: In order to avoid the cluttering of the `torch.nn` namespace
the quantized modules namespace is moved to `torch.ao.nn`.
The list of the `nn.quantized` files that are being migrated:
- [X] `torch.nn.quantized` → `torch.ao.nn.quantized`
- [X] `torch.nn.quantized.functional` → `torch.ao.nn.quantized.functional`
- [X] `torch.nn.quantized.modules` → `torch.ao.nn.quantized.modules`
- [X] `torch.nn.quantized.dynamic` → `torch.ao.nn.quantized.dynamic`
- [X] `torch.nn.quantized._reference` → `torch.ao.nn.quantized._reference`
- [X] `torch.nn.quantizable` → `torch.ao.nn.quantizable`
- [X] [Current PR] `torch.nn.qat` → `torch.ao.nn.qat`
- [X] `torch.nn.qat.modules` → `torch.ao.nn.qat.modules`
- [X] `torch.nn.qat.dynamic` → `torch.ao.nn.qat.dynamic`
- [ ] `torch.nn.intrinsic` → `torch.ao.nn.intrinsic`
- [ ] `torch.nn.intrinsic.modules` → `torch.ao.nn.intrinsic.modules`
- [ ] `torch.nn.intrinsic.qat` → `torch.ao.nn.intrinsic.qat`
- [ ] `torch.nn.intrinsic.quantized` → `torch.ao.nn.intrinsic.quantized`
- [ ] `torch.nn.intrinsic.quantized.modules` → `torch.ao.nn.intrinsic.quantized.modules`
- [ ] `torch.nn.intrinsic.quantized.dynamic` → `torch.ao.nn.intrinsic.quantized.dynamic`
Majority of the files are just moved to the new location.
However, specific files need to be double checked:
- None
Differential Revision: [D36861197](https://our.internmc.facebook.com/intern/diff/D36861197/)
**NOTE FOR REVIEWERS**: This PR has internal Facebook specific changes or comments, please review them on [Phabricator](https://our.internmc.facebook.com/intern/diff/D36861197/)!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78716
Approved by: https://github.com/jerryzh168
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81947
Transformer fastpath multiplexes two arguments, src_mask [seq_len x seq_len] and src_key_padding_mask [batch_size x seq_len], and later deduces the type based on mask shape.
In the event that batch_size == seq_len, any src_mask is wrongly interpreted as a src_key padding_mask. This is fixed by requiring a mask_type identifier be supplied whenever batch_size == seq_len.
Additionally, added support for src_mask in masked_softmax CPU path.
Test Plan: existing unit tests + new unit tests (batch_size == seq_len)
Differential Revision: D37932240
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81947
Approved by: https://github.com/zrphercule
To fix https://github.com/pytorch/pytorch/issues/82060
When `input` is not explicitly converted to channels last while `conv` has, the output should also be in channels last. The root cause is that when input has IC of 1, `compute_columns2d` from `\aten\src\ATen\native\ConvolutionMM2d.cpp` would consider it as channels first:
We do have logic to make sure both input and weight have the same memory format even if they are given differently, like:
```
auto input = self.contiguous(memory_format);
auto weight = weight_.contiguous(memory_format);
```
But for a N1HW input, `.contiguous(MemoryFormat::ChannelsLast)` would not change its stride , and its `suggest_memory_format()` still returns `MemoryFormat::Contiguous`. That's how it went wrong.
Also updated the corresponding test cases, without this patch, the new test case would fail on forward path and runtime error on backward path.
attach old fail log on forward path:
```
FAIL: test_conv_thnn_nhwc_cpu_float32 (__main__.TestNNDeviceTypeCPU)
----------------------------------------------------------------------
Traceback (most recent call last):
File "/home/mingfeim/anaconda3/envs/pytorch-test-cpu/lib/python3.7/site-packages/torch/testing/_internal/common_device_type.py", line 377, in instantiated_test
result = test(self, **param_kwargs)
File "/home/mingfeim/anaconda3/envs/pytorch-test-cpu/lib/python3.7/site-packages/torch/testing/_internal/common_device_type.py", line 974, in only_fn
return fn(slf, *args, **kwargs)
File "test/test_nn.py", line 19487, in test_conv_thnn_nhwc
input_format=torch.contiguous_format, weight_format=torch.channels_last)
File "test/test_nn.py", line 19469, in helper
self.assertEqual(out, ref_out, exact_dtype=False)
File "/home/mingfeim/anaconda3/envs/pytorch-test-cpu/lib/python3.7/site-packages/torch/testing/_internal/common_utils.py", line 2376, in assertEqual
msg=(lambda generated_msg: f"{generated_msg} : {msg}") if isinstance(msg, str) and self.longMessage else msg,
File "/home/mingfeim/anaconda3/envs/pytorch-test-cpu/lib/python3.7/site-packages/torch/testing/_comparison.py", line 1093, in assert_equal
raise error_metas[0].to_error(msg)
AssertionError: Tensor-likes are not close!
Mismatched elements: 988 / 1024 (96.5%)
Greatest absolute difference: 42.0 at index (1, 2, 6, 6) (up to 1e-05 allowed)
Greatest relative difference: inf at index (0, 0, 2, 1) (up to 1.3e-06 allowed)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/82392
Approved by: https://github.com/jbschlosser
Context: For a while slow gradcheck CI was skipping nearly all tests and this hid the fact that it should've been failing and timing out (10+h runtime for TestGradients). The CI configuration has since been fixed to correct this, revealing the test failures. This PR reenables slow gradcheck CI and makes it pass again.
This PR:
- makes slow and failing tests run in fast gradcheck mode only
- reduce the input size for slow gradcheck only for unary/binary ufuncs (alternatively, skip the test entirely)
- skip entire test files on slow gradcheck runner if they don't use gradcheck (test_ops, test_meta, test_decomp, test_ops_jit)
- reduces the input size for some ops
Follow ups:
1. Investigate slow mode failures https://github.com/pytorch/pytorch/issues/80411
2. See if we can re-enable slow gradcheck tests for some of the slow tests by reducing the sizes of their inputs
The following are failing in slow mode, they are now running in fast mode only.
```
test_fn_fwgrad_bwgrad___rmod___cuda_float64
test_fn_fwgrad_bwgrad_linalg_householder_product_cuda_complex128
test_fn_fwgrad_bwgrad__masked_prod_cuda_complex128
test_fn_fwgrad_bwgrad__masked_prod_cuda_float64
test_fn_fwgrad_bwgrad_linalg_matrix_power_cuda_complex128
test_fn_fwgrad_bwgrad_cat_cuda_complex128
test_fn_fwgrad_bwgrad_linalg_lu_factor_ex_cuda_float64
test_fn_fwgrad_bwgrad_copysign_cuda_float64
test_fn_fwgrad_bwgrad_cholesky_inverse_cuda_complex128
test_fn_fwgrad_bwgrad_float_power_cuda_complex128
test_fn_fwgrad_bwgrad_fmod_cuda_float64
test_fn_fwgrad_bwgrad_float_power_cuda_float64
test_fn_fwgrad_bwgrad_linalg_lu_cuda_float64
test_fn_fwgrad_bwgrad_remainder_cuda_float64
test_fn_fwgrad_bwgrad_repeat_cuda_complex128
test_fn_fwgrad_bwgrad_prod_cuda_complex128
test_fn_fwgrad_bwgrad_slice_scatter_cuda_float64
test_fn_fwgrad_bwgrad_tile_cuda_complex128
test_fn_fwgrad_bwgrad_pow_cuda_float64
test_fn_fwgrad_bwgrad_pow_cuda_complex128
test_fn_fwgrad_bwgrad_fft_*
test_fn_fwgrad_bwgrad_zero__cuda_complex128
test_fn_gradgrad_linalg_lu_factor_cuda_float64
test_fn_grad_div_trunc_rounding_cuda_float64
test_fn_grad_div_floor_rounding_cuda_float64
```
Marks the OpInfos for the following ops that run slowly in slow gradcheck as `fast_gradcheck` only (the left column represents runtime in seconds):
```
0 918.722 test_fn_fwgrad_bwgrad_nn_functional_conv_transpose3d_cuda_float64
1 795.042 test_fn_fwgrad_bwgrad_nn_functional_unfold_cuda_complex128
2 583.63 test_fn_fwgrad_bwgrad_nn_functional_max_pool3d_cuda_float64
3 516.946 test_fn_fwgrad_bwgrad_svd_cuda_complex128
4 503.179 test_fn_fwgrad_bwgrad_linalg_svd_cuda_complex128
5 460.985 test_fn_fwgrad_bwgrad_linalg_lu_cuda_complex128
6 401.04 test_fn_fwgrad_bwgrad_linalg_lstsq_grad_oriented_cuda_complex128
7 353.671 test_fn_fwgrad_bwgrad_nn_functional_max_pool2d_cuda_float64
8 321.903 test_fn_fwgrad_bwgrad_nn_functional_gaussian_nll_loss_cuda_float64
9 307.951 test_fn_fwgrad_bwgrad_stft_cuda_complex128
10 266.104 test_fn_fwgrad_bwgrad_svd_lowrank_cuda_float64
11 221.032 test_fn_fwgrad_bwgrad_istft_cuda_complex128
12 183.741 test_fn_fwgrad_bwgrad_lu_unpack_cuda_complex128
13 132.019 test_fn_fwgrad_bwgrad_nn_functional_unfold_cuda_float64
14 125.343 test_fn_fwgrad_bwgrad_nn_functional_pad_constant_cuda_complex128
15 124.2 test_fn_fwgrad_bwgrad_kron_cuda_complex128
16 123.721 test_fn_fwgrad_bwgrad_pca_lowrank_cuda_float64
17 121.074 test_fn_fwgrad_bwgrad_nn_functional_max_unpool3d_cuda_float64
18 119.387 test_fn_fwgrad_bwgrad_rot90_cuda_complex128
19 112.889 test_fn_fwgrad_bwgrad__masked_normalize_cuda_complex128
20 107.541 test_fn_fwgrad_bwgrad_dist_cuda_complex128
21 106.727 test_fn_fwgrad_bwgrad_diff_cuda_complex128
22 104.588 test_fn_fwgrad_bwgrad__masked_cumprod_cuda_complex128
23 100.135 test_fn_fwgrad_bwgrad_nn_functional_feature_alpha_dropout_with_train_cuda_float64
24 88.359 test_fn_fwgrad_bwgrad_mH_cuda_complex128
25 86.214 test_fn_fwgrad_bwgrad_nn_functional_max_unpool2d_cuda_float64
26 83.037 test_fn_fwgrad_bwgrad_nn_functional_bilinear_cuda_float64
27 79.987 test_fn_fwgrad_bwgrad__masked_cumsum_cuda_complex128
28 77.822 test_fn_fwgrad_bwgrad_diag_embed_cuda_complex128
29 76.256 test_fn_fwgrad_bwgrad_mT_cuda_complex128
30 74.039 test_fn_fwgrad_bwgrad_linalg_lu_solve_cuda_complex128
```
```
0 334.142 test_fn_fwgrad_bwgrad_unfold_cuda_complex128
1 312.791 test_fn_fwgrad_bwgrad_linalg_lu_factor_cuda_complex128
2 121.963 test_fn_fwgrad_bwgrad_nn_functional_max_unpool3d_cuda_float64
3 108.085 test_fn_fwgrad_bwgrad_diff_cuda_complex128
4 89.418 test_fn_fwgrad_bwgrad_nn_functional_max_unpool2d_cuda_float64
5 72.231 test_fn_fwgrad_bwgrad___rdiv___cuda_complex128
6 69.433 test_fn_fwgrad_bwgrad___getitem___cuda_complex128
7 68.582 test_fn_fwgrad_bwgrad_ldexp_cuda_complex128
8 68.572 test_fn_fwgrad_bwgrad_linalg_pinv_cuda_complex128
9 67.585 test_fn_fwgrad_bwgrad_nn_functional_glu_cuda_float64
10 66.567 test_fn_fwgrad_bwgrad_lu_cuda_float64
```
```
0 630.13 test_fn_gradgrad_nn_functional_conv2d_cuda_complex128
1 81.086 test_fn_gradgrad_linalg_solve_triangular_cuda_complex128
2 71.332 test_fn_gradgrad_norm_cuda_complex128
3 64.308 test_fn_gradgrad__masked_std_cuda_complex128
4 59.519 test_fn_gradgrad_div_no_rounding_mode_cuda_complex128
5 58.836 test_fn_gradgrad_nn_functional_adaptive_avg_pool3
```
Reduces the sizes of the inputs for:
- diff
- diag_embed
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80514
Approved by: https://github.com/albanD
`torch.nn.grad` has its own implementations of gradients for conv1d, conv2d, and conv3d. This PR simplifies them by calling into the unified `aten::convolution_backward` backend instead.
The existing implementation of conv2d_weight is incorrect for some inputs (see issue #51430). This PR fixes the issue.
This PR expands coverage in test_nn to include conv1d_weight, conv2d_weight, and conv3d_weight, which were previously untested. It also expands the cases for conv2d to cover issue #51430.
Fixes#51430
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81839
Approved by: https://github.com/albanD
Summary: We dont have a small fast path passing test for mha before, this diff added one for better testing
Test Plan: buck build mode/dev-nosan -c fbcode.platform=platform009 -c fbcode.enable_gpu_sections=true caffe2/test:nn && buck-out/dev/gen/caffe2/test/nn\#binary.par -r test_multihead_attn_fast_path_small_test
Differential Revision: D37834319
Pull Request resolved: https://github.com/pytorch/pytorch/pull/81432
Approved by: https://github.com/erichan1
Fixes#69413
After applying parametrization to any `nn.Module` we lose the ability to create a deepcopy of it e.g. it makes it impossible to wrap a module by an `AveragedModel`.
Specifically, the problem is that the `deepcopy` tries to invoke `__getstate__` if object hasn't implemented its own `__deepcopy__` magic method. But we don't allow serialization of the parametrized modules: `__getstate__` raises an error.
My solution is just to create a default `__deepcopy__` method when it doesn't exist yet.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/80811
Approved by: https://github.com/pearu, https://github.com/albanD
`test_conv_transposed_large` expects bitwise perfect results in fp16 on CUDA, but this behavior isn't guaranteed by cuDNN (e.g., in the case of FFT algos).
This PR just changes the tolerance on the test to account for these cases.
CC @ptrblck @ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78147
Approved by: https://github.com/ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/78298
Also back out "improve LayerNorm bfloat16 performance on CPU".
These layer norm changes seem fine, but they are causing `LayerNorm` to not use AVX2 instructions, which is causing performance on internal models to degrade. More investigation is needed to find the true root cause, but we should unland to mitigate the issue ASAP.
I left `mixed_data_type.h` around since there are some other files depending on it.
Differential Revision: [D36675352](https://our.internmc.facebook.com/intern/diff/D36675352/)
Approved by: https://github.com/tenpercent
Fixes#68172. Generally, this corrects multiple flaky convolution unit test behavior seen on ROCm.
The MIOpen integration has been forcing benchmark=True when calling `torch._C._set_cudnn_benchmark(False)`, typically called by `torch.backends.cudnn.set_flags(enabled=True, benchmark=False)`. We now add support for MIOpen immediate mode to avoid benchmarking during MIOpen solution selection.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77438
Approved by: https://github.com/ngimel, https://github.com/malfet
Double-header bug fix:
- As reported by jansel, dtypes are still showing up as integers
when the schema is an optional dtype. This is simple enough to
fix and I added a test for it. But while I was at it...
- I noticed that the THPMemoryFormat_new idiom with "unused" name
doesn't actually work, the repr of the returned memory format
object is wrong and this shows up when we try to log the args/kwargs.
So I fixed memory format to do it properly along with everything
else.
Fixes https://github.com/pytorch/pytorch/issues/77135
Signed-off-by: Edward Z. Yang <ezyangfb.com>
Pull Request resolved: https://github.com/pytorch/pytorch/pull/77543
Approved by: https://github.com/albanD, https://github.com/jansel
Summary: For user to convert nested tensor more easily. Some impl detail might change on user's need.
Test Plan: buck test mode/dev caffe2/test:nn -- test_nested_tensor_from_mask
Differential Revision: D36191182
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76942
Approved by: https://github.com/jbschlosser
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/76333
The current PyTorch multi-head attention and transformer
implementations are slow. This should speed them up for inference.
ghstack-source-id: 154737857
(Note: this ignores all push blocking failures!)
Test Plan: CI
Reviewed By: cpuhrsch
Differential Revision: D35239925
fbshipit-source-id: 5a7eb8ff79bc6afb4b7d45075ddb2a24a6e2df28
**Previous behavior**: compute inner product, then normalize.
**This patch**: first normalize, then compute inner product. This should be more numerically stable because it avoids losing precision in inner product for inputs with large norms.
By design ensures that cosine similarity is within `[-1.0, +1.0]`, so it should fix [#29442](https://github.com/pytorch/pytorch/issues/29442).
P.S. I had to change tests because this implementation handles division by 0 differently.
This PR computes cosine similarity as follows: <x/max(eps, ||x||), y/max(eps, ||y||)>.
Let f(x,y) = <x,y>/(||x|| * ||y||), then
df/dx = y/(||x|| * ||y||) - (||y||/||x|| * <x,y> * x)/(||x|| * ||y||)^2.
The changed test checks division by zero in backward when x=0 and y != 0.
For this case the non-zero part of the gradient is just y / (||x|| * ||y||).
The previous test evaluates y/(||x|| * ||y||) to y / eps, and this PR to 1/eps * y/||y||.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31378
Approved by: https://github.com/ezyang, https://github.com/albanD
Summary:
In this PR, we try to optimize PReLU op in CPU path, and enable BFloat16 support based on the optimized PReLU.
The original implementation uses parallel_for to accelerate operation speed, but vectorization is not used. It can be optimized by using TensorIterator, both including parallelization and vectorization.
The difference between PReLU and other activation function ops, is that PReLU supports a learnable parameter `weight`. When called without arguments, nn.PReLU() uses a single parameter `weight` across all input channels. If called with nn.PReLU(nChannels), a separate `weight` is used for each input channel. So we cannot simply use TensorIterator because `weight` is different for each input channel.
In order to use TensorIterator, `weight` should be broadcasted to `input` shape. And with vectorization and parallel_for, this implementation is much faster than the original one. Another advantage is, don't need to separate `share weights` and `multiple weights` in implementation.
We test the performance between the PReLU implementation of public Pytorch and the optimized PReLU in this PR, including fp32/bf16, forward/backward, share weights/multiple weights configurations. bf16 in public Pytorch directly reuses `Vectorized<scalar_t>` for `BFloat16`.
Share weights:
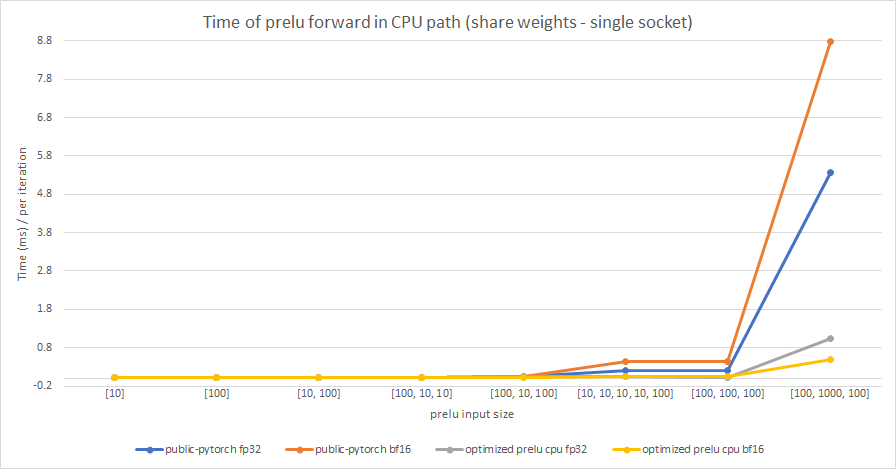
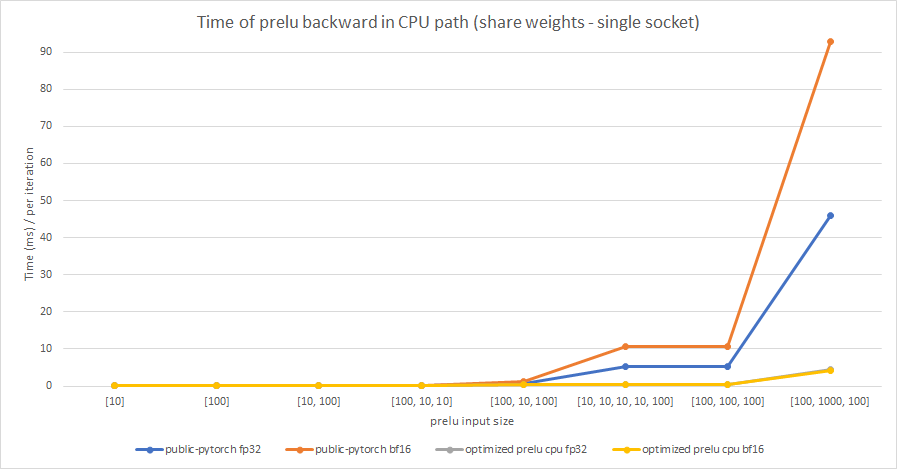
Multiple weights:
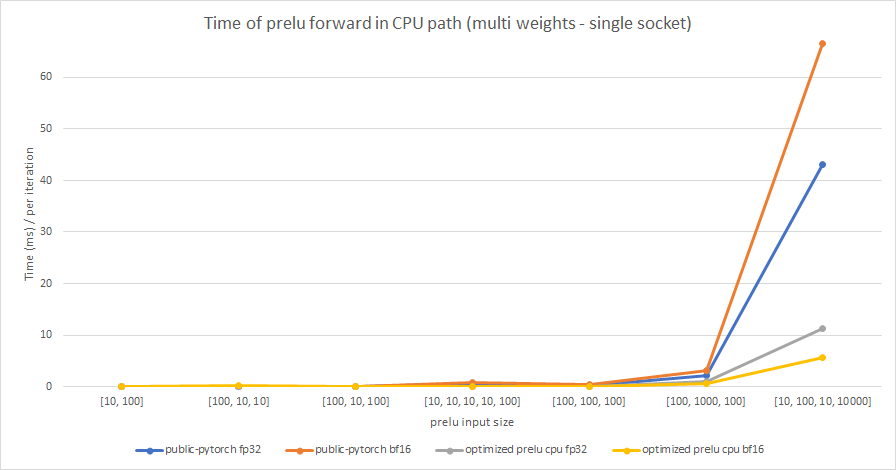
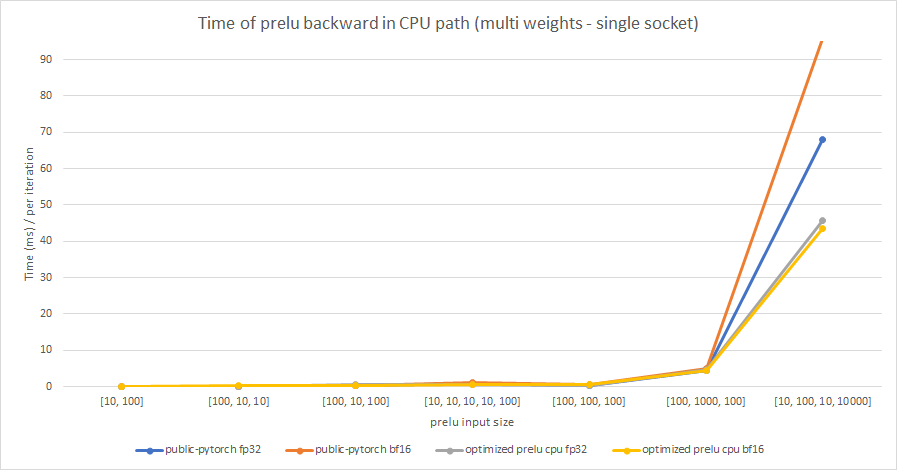
cc albanD mruberry jbschlosser walterddr
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63634
Reviewed By: yinghai
Differential Revision: D34031616
Pulled By: frank-wei
fbshipit-source-id: 04e2a0f9e92c658fba7ff56b1010eacb7e8ab44c
(cherry picked from commit ed262b15487557720bb0d498f9f2e8fcdba772d9)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/75421
As part of FSDP work, we will be relying on `_register_load_state_dict_pre_hook` to manage some specific logic related to loading state dicts.
This PR adds a test to ensure that _register_load_state_dict_pre_hook can be
used to register hooks on modules that will be used in a nested way, and then
calling load_state_dict on the overall module still calls those hooks
appropriately.
Differential Revision: [D35434726](https://our.internmc.facebook.com/intern/diff/D35434726/)
Approved by: https://github.com/albanD
Summary: The primary issue for enabling sparsity to work with QAT
convert (unlike normal quantization convert) is that when the
parametrized module undergoes the QAT convert, the parametrizations need
to be maintained. If the parametrizations don't
get transfered during the convert, the sparsifier would lose its
connection to the model. In practice this was handled using the
transfer_parametrizations_and_params function to move the weight and
bias and any associated paramerizations to the new module. This PR also adds
tests for transfer_parametrizations_and_params and type_before_parametrizations
to test_nn.py and also added comments to the test code for
composability.
Test Plan: python test/test_ao_sparsity.py TestComposability
python test/test_nn.py TestNN
Reviewers:
Subscribers:
Tasks:
Tags:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74848
Approved by: https://github.com/vkuzo, https://github.com/Lezcano
Summary:
Add BFloat16 support for logsigmoid, hardsigmoid, hardshrink, softshrink, hardswish and softplus on CPU, and optimize the performance of softshrink.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63134
Reviewed By: yinghai
Differential Revision: D34897992
Pulled By: frank-wei
fbshipit-source-id: 4c778f5271d6fa54dd78158258941def8d9252f5
(cherry picked from commit decda0e3debf56cc5c4d7faea41b1165a7cabe12)
For a GroupNorm module, if num_channels is not divisible by num_groups, we need to report an error when defining a module other than at the running step.
example:
```
import torch
m = torch.nn.GroupNorm(5, 6)
x = torch.randn(1, 6, 4, 4)
y = m(x)
```
before:
```
Traceback (most recent call last):
File "group_norm_test.py", line 8, in <module>
y = m(x)
File "/home/xiaobinz/miniconda3/envs/pytorch_mater/lib/python3.7/site-packages/torch/nn/modules/module.py", line 1111, in _call_impl
return forward_call(*input, **kwargs)
File "/home/xiaobinz/miniconda3/envs/pytorch_mater/lib/python3.7/site-packages/torch/nn/modules/normalization.py", line 271, in forward
input, self.num_groups, self.weight, self.bias, self.eps)
File "/home/xiaobinz/miniconda3/envs/pytorch_mater/lib/python3.7/site-packages/torch/nn/functional.py", line 2500, in group_norm
return torch.group_norm(input, num_groups, weight, bias, eps, torch.backends.cudnn.enabled)
RuntimeError: Expected number of channels in input to be divisible by num_groups, but got input of shape [1, 6, 4, 4] and num_groups=5
```
after:
```
Traceback (most recent call last):
File "group_norm_test.py", line 6, in <module>
m = torch.nn.GroupNorm(5, 6)
File "/home/xiaobinz/miniconda3/envs/pytorch_test/lib/python3.7/site-packages/torch/nn/modules/normalization.py", line 251, in __init__
raise ValueError('num_channels must be divisible by num_groups')
```
This PR also update the doc of num_groups.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/74293
Approved by: https://github.com/jbschlosser
Fixes#71415
I have implemented the changes that replicate what @to-mi did in this [PR](https://github.com/pytorch/pytorch/pull/65986#issue-1012959443) for the 3D case :
> Fixes#64977
>
> Avoids creating a tensor for and calculating `input` gradient if it's not needed in the backward pass of `grid_sample` (2d case, native CPU & CUDA kernels). Especially the tensor creation seemed time consuming (see #64977).
>
> Brief description of the changes:
>
> * I have tried to go with rather minimal changes. It would probably be possible to make a more elegant version with a bit larger refactoring (or possibly with better understanding of PyTorch internals and C++ functionalities).
>
> * Changed the `native_functions.yaml` and `derivatives.yaml` so that the gradient input mask is passed to the functions.
>
> * Changed the CPU kernels:
> (1) added `bool input_requires_grad` template parameter to the `backward` function,
> (2) added if branches based on it to remove `input` gradient computations if it's not requested,
> (3) feed in `TensorAccessor<scalar_t, 3>* gInp_slice_ptr` instead of `TensorAccessor<scalar_t, 3>& gInp_slice` so that I can pass a `nullptr` in case gradient for `input` is not requested. (A bit inelegant perhaps, but allows to keep one signature for `backward` function and not require breaking it to smaller pieces. Perhaps there's a more elegant way to achieve this?)
>
> * Changed CUDA kernel:
> (1) added ~`bool input_requires_grad` template parameter~ `const bool input_requires_grad` argument to the `backward` function,
> (2) added if branches based on it to remove `input` gradient computations if it's not requested,
> (3) feed in `TensorInfo<scalar_t, index_t>()` instead of `getTensorInfo<scalar_t, index_t>(grad_input)` in case gradient for `input` is not requested.
>
> * Modified tests in `test/test_nn.py` so that they run also cases with no `input` gradient needed.
>
> * Have not touched the CPU fallback kernel.
Note: the changes number (3) are N/A in this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71759
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72941
Simple test for MHA, use cos similarity as metric since scaling generate mismatch. Cuda is validated, CPU fix a following (We can land this with onlyCuda flag, and remove it once CPU is also done)
Test Plan:
For cuda:
buck build mode/opt -c fbcode.enable_gpu_sections=true caffe2/test:nn && buck-out/gen/caffe2/test/nn\#binary.par -r test_native_multihead_attention_cuda_float32 2>&1 | pastry
Reviewed By: swolchok
Differential Revision: D33906921
fbshipit-source-id: ad447401eb7002f22ed533d620a6b544524b3f58
(cherry picked from commit 45b778da27)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72944
Doesn't make sense to develop it in core right now.
ghstack-source-id: 149456040
Test Plan:
CI
run MHA benchmark in benchmark_transformers.py to make sure it doesn't crash
Reviewed By: zrphercule
Differential Revision: D34283104
fbshipit-source-id: 4f0c7a6bc066f938ceac891320d4cf4c3f8a9cd6
(cherry picked from commit b9df65e97c)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72671
The existing kernel did not handle cases where D % 4 != 0 or dim_per_head % 4 != 0. Now we have a non-vectorized kernel for these cases.
ghstack-source-id: 149201477
Test Plan: Updated test_nn to cover these cases.
Reviewed By: zrphercule, ngimel
Differential Revision: D34119371
fbshipit-source-id: 4e9b4d9b636224ef2c433593f6f236df040de782
(cherry picked from commit f5393878e4)
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72464
We had some trouble getting this component (and this test!) right, so let's test it.
ghstack-source-id: 149201478
Test Plan: new test passes
Reviewed By: zrphercule
Differential Revision: D33992477
fbshipit-source-id: cc377eed5d4a4412b42bdabf360601c6e52947cf
(cherry picked from commit 9832867b12)
Summary:
https://github.com/pytorch/pytorch/issues/71521 attempted to fix an issue where the `test_conv_large` test was producing `NaN` values after the backward pass, yielding a bogus comparison between the result and the expected result. While tweaking the initialization of the conv layer seemed to fix this behavior, it was actually just masking the real issue, which was that `grad_weight` is not guaranteed to be initialized in `raw_cudnn_convolution_backward_weight_out` when the backward operation is split.
Specifically, the `grad_weight` tensor is expected to be directly written to by a `cudnn` kernel (which does occur in most cases) so it does not need to be initialized, but splitting introduces an intermediate `grad_weight_` tensor that holds the intermediate gradients and then accumulates into `grad_weight` without initializing it first. This PR tweaks this behavior so that now accumulation is done with a zero'd tensor, and also adds the change of doing the accumulation in an accumulation dtype. The hacky workaround masking the issue is also reverted, with the safeguard against comparing `NaN` values (using the reference tensor for scale computation) kept in place.
CC ngimel ptrblck
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72157
Reviewed By: malfet
Differential Revision: D34147547
Pulled By: ngimel
fbshipit-source-id: 056c19f727eeef96347db557528272e24eae4223
(cherry picked from commit 24c7f77a81)
Summary:
The only difference with plain list/dict now is that nn.Parameters are
handled specially and registered as parameters properly.
test_nn and parametrization works locally.
Will see in CI if DP is fixed as well.
Tentative fix for https://github.com/pytorch/pytorch/issues/36035
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70499
Reviewed By: jbschlosser, alexeib
Differential Revision: D34005332
Pulled By: albanD
fbshipit-source-id: 7e76b0873d0fec345cb537e2a6ecba0258e662b9
(cherry picked from commit dc1e6f8d86)
Summary:
Fixes https://github.com/pytorch/pytorch/issues/71720
This PR removes the old warnings for `recompute_scale_factor` and `align_corners`.
Looking at this, I realize that the tests I modified don't really catch whether or not a warning is created for `recompute_scale_factor`. If desired, I can add a couple lines into the tests there to pass a floating point in the `scale_factors` kwarg, along with `recompute_scale_factor=None`.
Let me know how this looks, thanks so much!
Pull Request resolved: https://github.com/pytorch/pytorch/pull/72093
Reviewed By: mruberry
Differential Revision: D33917615
Pulled By: albanD
fbshipit-source-id: e822f0a15b813ecf312cdc6ed0b693e7f1d1ca89
(cherry picked from commit c14852b85c)
Summary:
Pull Request resolved: https://github.com/pytorch/torchrec/pull/39
Pull Request resolved: https://github.com/facebookresearch/torchrec/pull/6
This makes it so that shared parameters get their own entry in `named_parameters`.
More broadly, this makes it so that
```
params_and_buffers = {**mod.named_named_parameters(remove_duplicate=False), **mod.named_buffers(remove_duplicate=False)}
_stateless.functional_call(mod, params_and_buffers, args, kwargs)
```
is identical to calling the original module's forwards pass.
cc pietern mrshenli pritamdamania87 zhaojuanmao satgera rohan-varma gqchen aazzolini osalpekar jiayisuse SciPioneer H-Huang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71542
Reviewed By: jbschlosser, albanD
Differential Revision: D33716716
Pulled By: Chillee
fbshipit-source-id: ff1ed9980bd1a3f7ebaf695ee5e401202b543213
(cherry picked from commit d6e3ad3cd0)
Summary:
Hi,
The PR fixes https://github.com/pytorch/pytorch/issues/71096. It aims to scan all the test files and replace ` ALL_TENSORTYPES` and `ALL_TENSORTYPES2` with `get_all_fp_dtypes`.
I'm looking forward to your viewpoints!
Thanks!
cc: janeyx99 kshitij12345
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71153
Reviewed By: jbschlosser, mruberry
Differential Revision: D33533346
Pulled By: anjali411
fbshipit-source-id: 75e79ca2756c1ddaf0e7e0289257fca183a570b3
(cherry picked from commit da54b54dc5)
Summary:
This PR twiddles the parameters of the conv layer in `test_conv_large` to better avoid NaN values. Previously, this test would cause a NaN to be computed for `scale` (propagated from `.mean()` on the `.grad` tensor). This NaN would then be propagated to the scaled gradients via division, resulting in a bogus `assertEqual` check as `NaN == NaN` is by default true. (This behavior was observed on V100 and A100).
To improve visibility of failures in the event of NaNs in `grad1`, scale is now computed from `grad2`.
Interestingly enough, we discovered this issue when trying out some less common setups that broke this test; it turns out those breakages were cases where there were no NaN values (leading to an actual `assertEqual` check that would fail for `float16`).
CC ptrblck ngimel puririshi98
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71521
Reviewed By: anjali411
Differential Revision: D33776705
Pulled By: ngimel
fbshipit-source-id: a1ec4792cba04c6322b22ef5b80ce08579ea4cf6
(cherry picked from commit d207bd9b87)
Summary:
We found a discrepancy between cpu & CUDA when using RNN modules where input shapes containing 0s would cause an invalid configuration argument error in CUDA (kernel grid size is 0), while returning a valid tensor in CPU cases.
A reproducer:
```
import torch
x = torch.zeros((5, 0, 3)).cuda()
gru = torch.nn.GRU(input_size=3, hidden_size=4).to("cuda")
gru(x)
```
Run with `CUDA_LAUNCH_BLOCKING=1` set.
cc ngimel albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/71696
Reviewed By: mikaylagawarecki
Differential Revision: D33743674
Pulled By: ngimel
fbshipit-source-id: e9334175d10969fdf1f9c63985910d944bbd26e7
(cherry picked from commit 70838ba69b)
Summary:
Helps fix a part of https://github.com/pytorch/pytorch/issues/69865
The first commit just migrates everything as is.
The second commit uses the "device" variable instead of passing "cuda" everywhere
Pull Request resolved: https://github.com/pytorch/pytorch/pull/70872
Reviewed By: jbschlosser
Differential Revision: D33455941
Pulled By: janeyx99
fbshipit-source-id: 9d9ec8c95f1714c40d55800e652ccd69b0c314dc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69727
Still need to test the backward ones. We would need to update gradgradcheck to check forward over backward.
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D33031728
Pulled By: soulitzer
fbshipit-source-id: 86c59df5d2196b5c8dbbb1efed9321e02ab46d30
Summary:
Fixes https://github.com/pytorch/pytorch/issues/68476
We implemented all of the following `dict` methods for `ParameterDict`
- `get `
- `setdefault`
- `popitem`
- `fromkeys`
- `copy`
- `__or__`
- `__ior__`
- `__reversed__`
- `__ror__`
The behavior of these new methods matches the expected behavior of python `dict` as defined by the language itself: https://docs.python.org/3/library/stdtypes.html#typesmapping
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69403
Reviewed By: albanD
Differential Revision: D33187111
Pulled By: jbschlosser
fbshipit-source-id: ecaa493837dbc9d8566ddbb113b898997e2debcb
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69272
In transformer encoder and MHA, masked_softmax's mask is a 2D tensor (B, D), where input is a 4D tensor (B, H, D, D).
This mask could be simply broadcasted to a (B, H, D, D) like input, and then do a regular masked_softmax, however it will bring the problem of non-contiguous mask & consume more memory.
In this diff, we maintained mask's shape unchanged, while calc the corresponding mask for input in each cuda thread.
This new layout is not currently supported in CPU yet.
Test Plan: buck build mode/opt -c fbcode.enable_gpu_sections=true caffe2/test:nn && buck-out/gen/caffe2/test/nn\#binary.par -r test_masked_softmax
Reviewed By: ngimel
Differential Revision: D32605557
fbshipit-source-id: ef37f86981fdb2fb264d776f0e581841de5d68d2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/69268
This diff enabled native masked softmax on CUDA, also expanded our current warp_softmax to accept masking.
The mask in this masked softmax has to be the same shape as input, and has to be contiguous.
In a following diff I will submit later, I will have encoder mask layout included, where input is BHDD and mask is BD.
Test Plan: buck build mode/opt -c fbcode.enable_gpu_sections=true caffe2/test:nn && buck-out/gen/caffe2/test/nn\#binary.par -r test_masked_softmax
Reviewed By: ngimel
Differential Revision: D32338419
fbshipit-source-id: 48c3fde793ad4535725d9dae712db42e2bdb8a49
Summary:
Towards [convolution consolidation](https://fb.quip.com/tpDsAYtO15PO).
Introduces the general `convolution_backward` function that uses the factored-out backend routing logic from the forward function.
Some notes:
* `finput` is now recomputed in the backward pass for the slow 2d / 3d kernels instead of being saved from the forward pass. The logic for is based on the forward computation and is present in `compute_finput2d` / `compute_finput3d` functions in `ConvUtils.h`.
* Using structured kernels for `convolution_backward` requires extra copying since the backend-specific backward functions return tensors. Porting to structured is left as future work.
* The tests that check the routing logic have been renamed from `test_conv_backend_selection` -> `test_conv_backend` and now also include gradcheck validation using an `autograd.Function` hooking up `convolution` to `convolution_backward`. This was done to ensure that gradcheck passes for the same set of inputs / backends.
The forward pass routing is done as shown in this flowchart (probably need to download it for it to be readable since it's ridiculous):
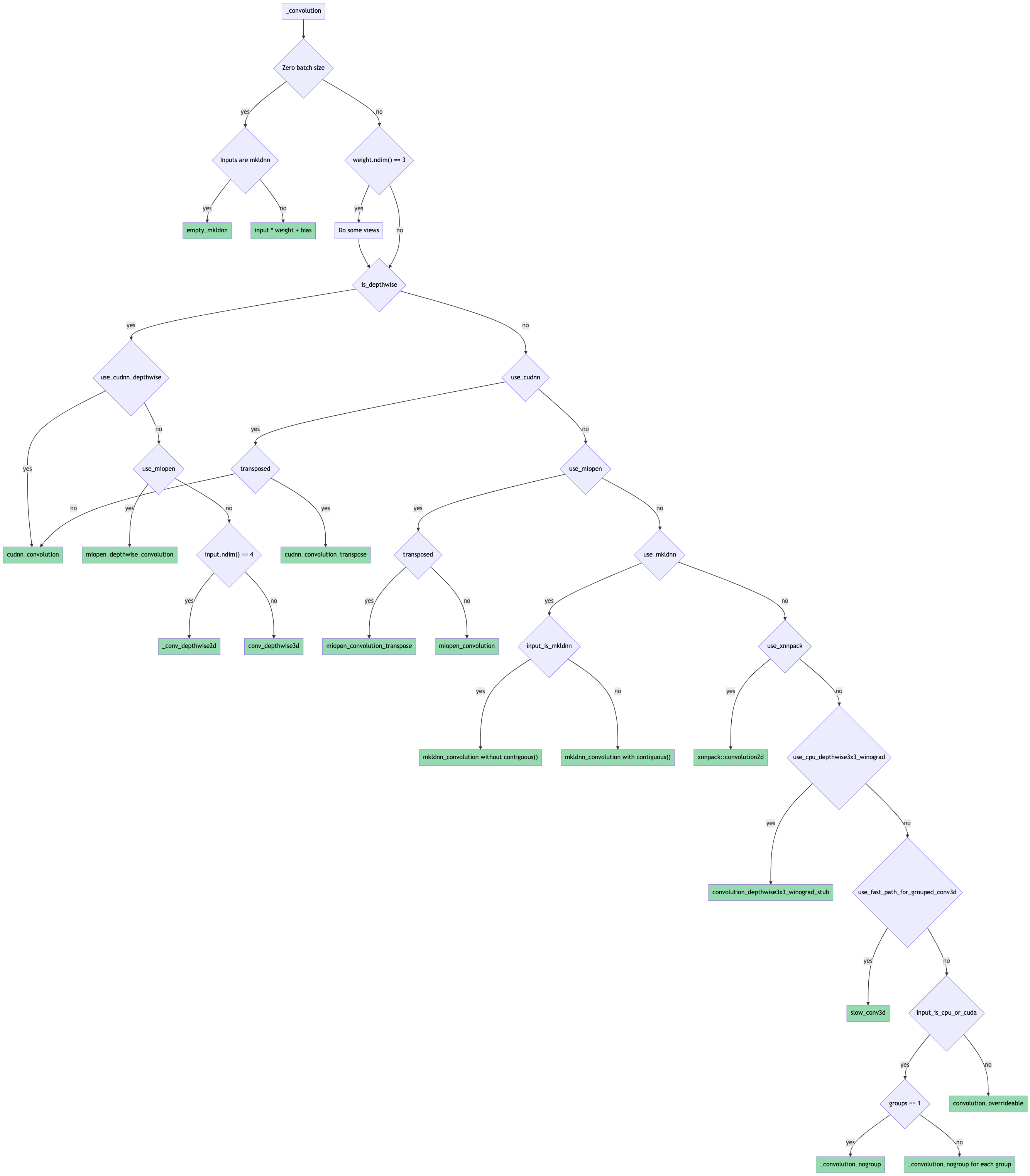
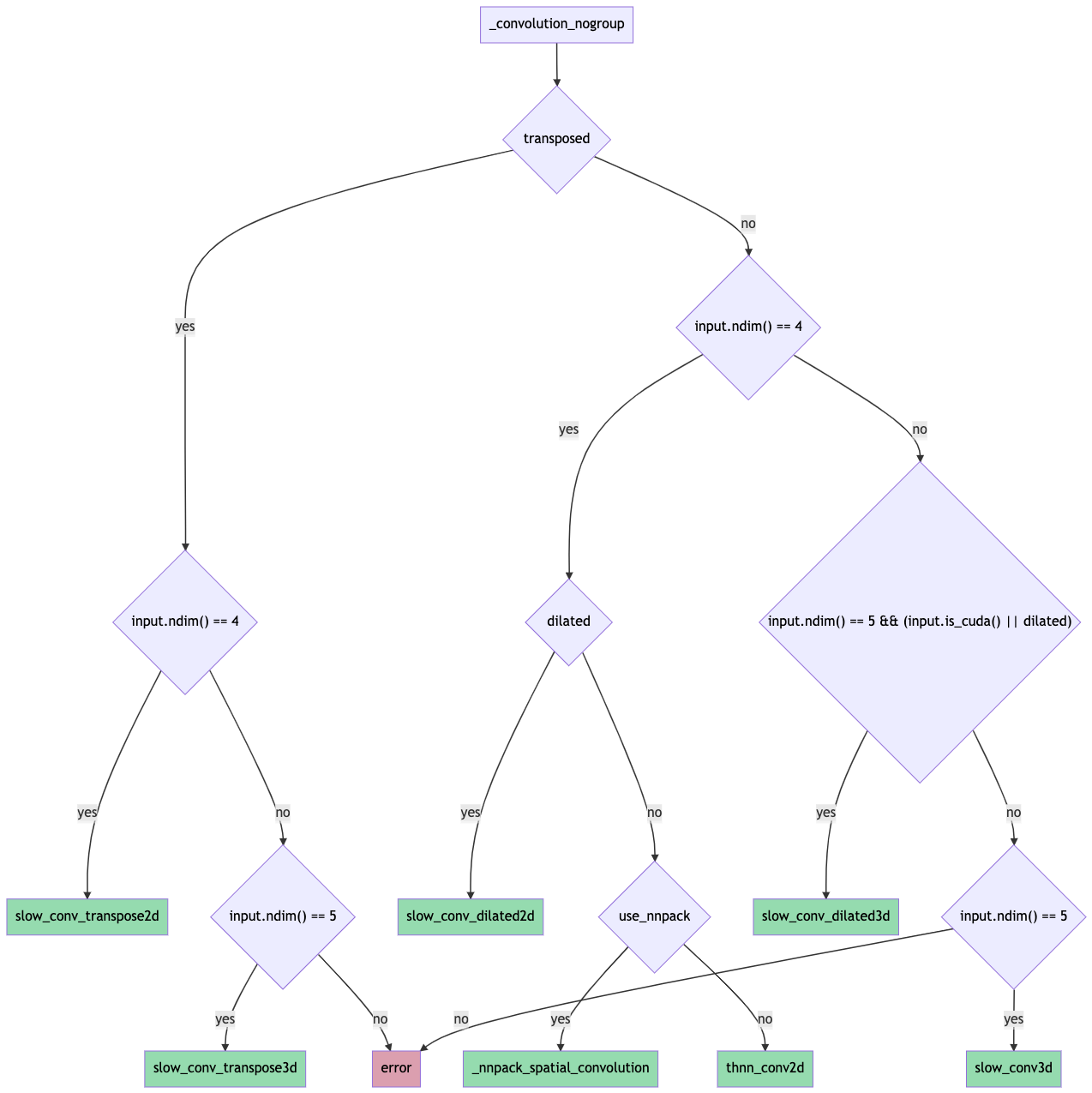
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65219
Reviewed By: mruberry
Differential Revision: D32611368
Pulled By: jbschlosser
fbshipit-source-id: 26d759b7c908ab8f19ecce627acea7bd3d5f59ba
Summary:
Adds native_dropout to have a reasonable target for torchscript in auto diff. native_dropout has scale and train as arguments in its signature, this makes native_dropout more consistent with other operators and removes conditionals in the autodiff definition.
cc gmagogsfm
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63937
Reviewed By: mruberry
Differential Revision: D32477657
Pulled By: ngimel
fbshipit-source-id: d37b137a37acafa50990f60c77f5cea2818454e4
Summary:
Fixes https://github.com/pytorch/pytorch/issues/53647
With this if a test forgets to add `dtypes` while using `dtypesIf`, following error is raised
```
AssertionError: dtypes is mandatory when using dtypesIf however 'test_exponential_no_zero' didn't specify it
```
**Tested Locally**
Pull Request resolved: https://github.com/pytorch/pytorch/pull/68186
Reviewed By: VitalyFedyunin
Differential Revision: D32468581
Pulled By: mruberry
fbshipit-source-id: 805e0855f988b77a5d8d4cd52b31426c04c2200b
Summary:
This PR introduces a new function `_select_conv_backend` that returns a `ConvBackend` enum representing the selected backend for a given set of convolution inputs and params.
The function and enum are exposed to python for testing purposes through `torch/csrc/Module.cpp` (please let me know if there's a better place to do this).
A new set of tests validates that the correct backend is selected for several sets of inputs + params. Some backends aren't tested yet:
* nnpack (for mobile)
* xnnpack (for mobile)
* winograd 3x3 (for mobile)
Some flowcharts for reference:


Pull Request resolved: https://github.com/pytorch/pytorch/pull/67790
Reviewed By: zou3519
Differential Revision: D32280878
Pulled By: jbschlosser
fbshipit-source-id: 0ce55174f470f65c9b5345b9980cf12251f3abbb
Summary:
This PR makes several changes:
- Changed function `bool cudnn_conv_use_channels_last(...)` to `at::MemoryFormat cudnn_conv_suggest_memory_format(...)`
- Removed `resize_` in cudnn convolution code. Added a new overloading method `TensorDescriptor::set` that also passes the desired memory format of the tensor.
- Disabled the usage of double + channels_last on cuDNN Conv-Relu and Conv-Bias-Relu. Call `.contiguous(memory_format)` before passing data to cuDNN functions.
- Disabled the usage of cuDNN fused Conv-Bias-Relu in cuDNN < 8.0 version due to a CUDNN_STATUS_NOT_SUPPORTED error. Instead, use the native fallback path.
- Let Conv-Bias-Relu code respect the global `allow_tf32` flag.
From cuDNN document, double + NHWC is genenrally not supported.
Close https://github.com/pytorch/pytorch/pull/66968
Fix https://github.com/pytorch/pytorch/issues/55301
Pull Request resolved: https://github.com/pytorch/pytorch/pull/65594
Reviewed By: jbschlosser, malfet
Differential Revision: D32175766
Pulled By: ngimel
fbshipit-source-id: 7ba079c9f7c46fc56f8bfef05bad0854acf380d7
Summary:
Partially fixes https://github.com/pytorch/pytorch/issues/66066
This PR:
- cleans up op-specific testing from test_autograd. test_autograd should be reserved for testing generic autograd functionality
- tests related to an operator are better colocated
- see the tracker for details
What to think about when moving tests to their correct test suite:
- naming, make sure its not too generic
- how the test is parametrized, sometimes we need to add/remove a device/dtype parameter
- can this be merged with existing tests
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67413
Reviewed By: jbschlosser, albanD
Differential Revision: D32031480
Pulled By: soulitzer
fbshipit-source-id: 8e13da1e58a38d5cecbfdfd4fe2b4fe6f816897f
Summary:
Fix https://github.com/pytorch/pytorch/issues/67239
The CUDA kernels for `adaptive_max_pool2d` (forward and backward) were written for contiguous output. If outputs are non-contiguous, first create a contiguous copy and let the kernel write output to the contiguous memory space. Then copy the output from contiguous memory space to the original non-contiguous memory space.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67697
Reviewed By: ejguan
Differential Revision: D32112443
Pulled By: ngimel
fbshipit-source-id: 0e3bf06d042200c651a79d13b75484526fde11fe
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/66879
This adds a quantized implementation for bilinear gridsample. Bicubic interpolation cannot be supported as easily since we rely on the linearity of quantization to operate on the raw values, i.e.
f(q(a), q(b)) = q(f(a, b)) where f is the linear interpolation function.
ghstack-source-id: 141321116
Test Plan: test_quantization
Reviewed By: kimishpatel
Differential Revision: D31656893
fbshipit-source-id: d0bc31da8ce93daf031a142decebf4a155943f0f
Summary:
Removes the 3D special case logic in `_convolution_double_backward()` that never worked.
The logic was never called previously since `convolution()` expands input / weight from 3D -> 4D before passing them to backends; backend-specific backward calls thus save the 4D version to pass to `_convolution_double_backward()`.
The new general `convolution_backward()` saves the original 3D input / weight, uncovering the bug.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/67283
Reviewed By: anjali411
Differential Revision: D32021100
Pulled By: jbschlosser
fbshipit-source-id: 0916bcaa77ef49545848b344d6385b33bacf473d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64181
This PR replaces all the calls to:
- `transpose(-2, -1)` or `transpose(-1, -2)` by `mT()` in C++ and `mT` in Python
- `conj().transpose(-2, -1)` or `transpose(-2, -1).conj()` or `conj().transpose(-1, -2)` or `transpose(-1, -2).conj()` by `mH()` in C++ and `mH` in Python.
It also simplifies two pieces of code, and fixes one bug where a pair
of parentheses were missing in the function `make_symmetric_matrices`.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D31692896
Pulled By: anjali411
fbshipit-source-id: e9112c42343663d442dc5bd53ff2b492094b434a
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64572
Fixes https://github.com/pytorch/pytorch/issues/64256
It also fixes an inconsistent treatment of the case `reduction = "mean"`
when the whole target is equal to `ignore_index`. It now returns `NaN`
in this case, consistently with what it returns when computing the mean
over an empty tensor.
We add tests for all these cases.
Test Plan: Imported from OSS
Reviewed By: ezyang
Differential Revision: D31116297
Pulled By: albanD
fbshipit-source-id: cc44e79205f5eeabf1efd7d32fe61e26ba701b52
Summary:
- Added 2D-Convolution NHWC support
- on ROCm 4.3, with `PYTORCH_MIOPEN_SUGGEST_NHWC=1` flag
- May need to force MIOpen to search for solutions ( see examples below for flags )
**PYTORCH_MIOPEN_SUGGEST_NHWC Environment Flag**
MIOpen does not officially support NHWC yet, although convolution support has been added to tip-of-tree of MIOpen. This flag is intended to be a short-lived flag to explicitly turn on NHWC support until ROCm officially supports NHWC and performance is verified.
**Examples**
1. Example usage 1 : Run test on ROCm4.3
`PYTORCH_TEST_WITH_ROCM=1 PYTORCH_MIOPEN_SUGGEST_NHWC=1 MIOPEN_FIND_ENFORCE=4 MIOPEN_DEBUG_CONV_GEMM=0 MIOPEN_FIND_MODE=1 pytest test_nn.py -v -k "test_conv_cudnn_nhwc" `
2. Example usage 2: Run the following with `PYTORCH_MIOPEN_SUGGEST_NHWC=1` on ROCm4.3.
```
#!/usr/bin/env python3
import torch
model = torch.nn.Conv2d(8, 4, 3).cuda().half()
model = model.to(memory_format=torch.channels_last)
input = torch.randint(1, 10, (2, 8, 4, 4), dtype=torch.float32, requires_grad=True)
input = input.to(device="cuda", memory_format=torch.channels_last, dtype=torch.float16)
# should print True for is_contiguous(channels_last), and strides must match NHWC format
print(input.is_contiguous(memory_format=torch.channels_last), input.shape, input.stride() )
out = model(input)
# should print True for is_contiguous(channels_last), and strides must match NHWC format
print("Contiguous channel last :", out.is_contiguous(memory_format=torch.channels_last), " out shape :", out.shape, "out stride :", out.stride() )
```
See https://pytorch.org/tutorials/intermediate/memory_format_tutorial.html for more examples.
cc jeffdaily sunway513 jithunnair-amd ROCmSupport
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63617
Reviewed By: saketh-are
Differential Revision: D30730800
Pulled By: ezyang
fbshipit-source-id: 61906a0f30be8299e6547d312ae6ac91cc7c3238
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63554
Following https://github.com/pytorch/pytorch/pull/61840#issuecomment-884087809, this deprecates all the dtype getters publicly exposed in the `torch.testing` namespace. The reason for this twofold:
1. If someone is not familiar with the C++ dispatch macros PyTorch uses, the names are misleading. For example `torch.testing.floating_types()` will only give you `float32` and `float64` skipping `float16` and `bfloat16`.
2. The dtype getters provide very minimal functionality that can be easily emulated by downstream libraries.
We thought about [providing an replacement](https://gist.github.com/pmeier/3dfd2e105842ad0de4505068a1a0270a), but ultimately decided against it. The major problem is BC: by keeping it, either the namespace is getting messy again after a new dtype is added or we need to somehow version the return values of the getters.
Test Plan: Imported from OSS
Reviewed By: H-Huang
Differential Revision: D30662206
Pulled By: mruberry
fbshipit-source-id: a2bdb10ab02ae665df1b5b76e8afa9af043bbf56
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64385
It was deleted in https://github.com/pytorch/pytorch/pull/63276.
The numerics test was meant to check LayerNorm behavior on large inputs,
but we deleted it without realizing that.
Test Plan: - wait for tests.
Reviewed By: ngimel
Differential Revision: D30702950
Pulled By: zou3519
fbshipit-source-id: a480e26c45ec38fb628938b70416cdb22d976a46
Summary:
Implements an orthogonal / unitary parametrisation.
It does passes the tests and I have trained a couple models with this implementation, so I believe it should be somewhat correct. Now, the implementation is very subtle. I'm tagging nikitaved and IvanYashchuk as reviewers in case they have comments / they see some room for optimisation of the code, in particular of the `forward` function.
Fixes https://github.com/pytorch/pytorch/issues/42243
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62089
Reviewed By: ezyang
Differential Revision: D30639063
Pulled By: albanD
fbshipit-source-id: 988664f333ac7a75ce71ba44c8d77b986dff2fe6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/64039
There are two distinct problems here.
1. If `grad_output` is channels last but not input, then input would be read as-if it were channels last. So reading the wrong values.
2. `use_channels_last_kernels` doesn't guarunte that `suggest_memory_format` will actually return channels last, so use `empty_like` instead so the strides always match.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/64100
Reviewed By: mruberry
Differential Revision: D30622127
Pulled By: ngimel
fbshipit-source-id: e28cc57215596817f1432fcdd6c49d69acfedcf2
Summary:
I think the original intention here is to only take effect in the case of align_corners (because output_size = 1 and the divisor will be 0), but it affects non-align_corners too. For example:
```python
input = torch.tensor(
np.arange(1, 5, dtype=np.int32).reshape((1, 1, 2, 2)) )
m = torch.nn.Upsample(scale_factor=0.5, mode="bilinear")
of_out = m(input)
```
The result we expect should be [[[[2.5]]]]
but pytorch get [[[[1.0]]]] which is different from OpenCV and PIL, this pr try to fixed it。
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61166
Reviewed By: malfet
Differential Revision: D30543178
Pulled By: heitorschueroff
fbshipit-source-id: 21a4035483981986b0ae4a401ef0efbc565ccaf1
Summary:
Fixes https://github.com/pytorch/pytorch/issues/62094
Introduces functionality for adding arbitrary objects to module state_dicts. To take advantage of this, the following functions can be defined on a module:
* `get_extra_state(self) -> dict` - Returns a dict defining any extra state this module wants to save
* `set_extra_state(self, state)` - Subsumes the given state within the module
In the details, a sub-dictionary is stored in the state_dict under the key `_extra_state` for each module that requires extra state.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62976
Reviewed By: heitorschueroff
Differential Revision: D30518657
Pulled By: jbschlosser
fbshipit-source-id: 5fb35ab8e3d36f35e3e96dcd4498f8c917d1f386
Summary:
Interestingly enough, the original code did have a mechanism that aims to prevent this very issue:
but it performs a clone AFTER modifying u and v in-place.
This wouldn't work though because we can later use the cloned u and v in operations that save for backward, and the next time we execute forward, we modify the same cloned u and v in-place.
So if the idea is that we want to avoid modifying saved variable in-place we should clone it BEFORE the in-place operation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62293
Reviewed By: bdhirsh
Differential Revision: D30489750
Pulled By: soulitzer
fbshipit-source-id: cbe8dea885aef97adda8481f7a822e5bd91f7889
Summary:
As discussed here https://github.com/pytorch/pytorch/pull/62897, in the path of BF16/non-last-dim Softmax, we miss the subtractions of max value which will cause the overflow in the `exp()` calculation when the value of input tensor is large, such as `1000.0`.
To avoid this issue, we add the subtractions of max value and the corresponding test cases in this PR.
Note w/o subtractions of max value(accidental reverts or changes), we will get the underlying error message of the test case
```
AssertionError: False is not true : Tensors failed to compare as equal!With rtol=0.05 and atol=0.05, found 103984 element(s) (out of 126720) whose difference(s) exceeded the margin of error (including 103984 nan comparisons). The greatest difference was nan (0.0 vs. nan), which occurred at index (0, 0, 0, 1).
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/63132
Reviewed By: VitalyFedyunin
Differential Revision: D30280792
Pulled By: cpuhrsch
fbshipit-source-id: 722821debf983bbb4fec878975fa8a4da0d1d866
Summary:
This issue fixes a part of https://github.com/pytorch/pytorch/issues/12013, which is summarized concretely in https://github.com/pytorch/pytorch/issues/38115.
This PR allows `MaxPool` and `AdaptiveMaxPool` to accept tensors whose batch size is 0. Some changes have been made to modernize the tests so that they will show the name of C++ function that throws an error.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62088
Reviewed By: bdhirsh
Differential Revision: D30281285
Pulled By: jbschlosser
fbshipit-source-id: 52bffc67bfe45a78e11e4706b62cce1469eba1b9
Summary: skip rocm test for test_cudnn_convolution_relu
Test Plan: This skips a test
Reviewed By: ngimel
Differential Revision: D30233620
fbshipit-source-id: 31eab8b03c3f15674e0d262a8f55965c1aa6b809
Summary:
Currently when cudnn_convolution_relu is passed a channels last Tensor it will return a contiguous Tensor. This PR changes this behavior and bases the output format on the input format.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62482
Reviewed By: ngimel
Differential Revision: D30049905
Pulled By: cpuhrsch
fbshipit-source-id: 98521d14ee03466e7128a1912b9f754ffe10b448
Summary:
Enable Gelu bf16/fp32 in CPU path using Mkldnn implementation. User doesn't need to_mkldnn() explicitly. New Gelu fp32 performs better than original one.
Add Gelu backward for https://github.com/pytorch/pytorch/pull/53615.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58525
Reviewed By: ejguan
Differential Revision: D29940369
Pulled By: ezyang
fbshipit-source-id: df9598262ec50e5d7f6e96490562aa1b116948bf
Summary:
Fixes https://github.com/pytorch/pytorch/issues/11959
Alternative approach to creating a new `CrossEntropyLossWithSoftLabels` class. This PR simply adds support for "soft targets" AKA class probabilities to the existing `CrossEntropyLoss` and `NLLLoss` classes.
Implementation is dumb and simple right now, but future work can add higher performance kernels for this case.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61044
Reviewed By: zou3519
Differential Revision: D29876894
Pulled By: jbschlosser
fbshipit-source-id: 75629abd432284e10d4640173bc1b9be3c52af00
Summary:
Fixes Python part of https://github.com/pytorch/pytorch/issues/60747
Enhances the Python versions of `Transformer`, `TransformerEncoderLayer`, and `TransformerDecoderLayer` to support callables as their activation functions. The old way of specifying activation function still works as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61355
Reviewed By: bdhirsh
Differential Revision: D29967302
Pulled By: jbschlosser
fbshipit-source-id: 8ee6f20083d49dcd3ab432a18e6ad64fe1e05705
Summary:
Here is the PR to enable the softmax calculation with data type of `bfloat16` when not along the last dim.
* Use bf16 specialization for forward calculation to reduce the bf16/fp32 cast in vec template.
* Release the bf16 limitation for backward calculation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60371
Reviewed By: ejguan
Differential Revision: D29563109
Pulled By: cpuhrsch
fbshipit-source-id: f6b439fa3850a6c633f35db65ea3d735b747863e
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62281
Closes gh-24646, Closes gh-24647
There is no `TensorIterator` equivalent to these kernels so this is just
migrating the existing kernels over to the ATen style.
I've benchmarked for contiguous tensors with this script:
```
import torch
shape = (10, 10, 100, 100)
x = torch.randn(*shape, device='cuda')
w = torch.randn((10, 1, 5, 5), device='cuda')
for _ in range(100):
torch.nn.functional.conv2d(x, w, groups=10)
```
and similarly for backwards. I see these as the same to within measurement error.
| | Master Forward (us) | This PR Forward (us) |
|------------------:|:-------------------:|:--------------------:|
| Forward | 133.5 | 133.6 |
| Backward (input) | 1,102 | 1,119 |
| Backward (weight) | 2,220 | 2,217 |
Test Plan: Imported from OSS
Reviewed By: ejguan
Differential Revision: D29943062
Pulled By: ngimel
fbshipit-source-id: fc5d16496eb733743face7c5a14e532d7b8ee26a
Summary:
Part of the fix for https://github.com/pytorch/pytorch/issues/12013
Checks if the inputs and outputs are non-zero in order to allow the Bilinear layer to accept 0-dim batch sizes. The if-check for this checks for both input and output dim sizes since the `_trilinear` function is written to work with both forward and backward for Bilinear.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/47106
Reviewed By: ejguan
Differential Revision: D29935589
Pulled By: jbschlosser
fbshipit-source-id: 607d3352bd4f88e2528c64408f04999960be049d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/62006
Closes gh-24646, gh-24647
There is no `TensorIterator` equivalent to these kernels so this is just
migrating the existing kernels over to the ATen style.
I've benchmarked for contiguous tensors with this script:
```
import torch
shape = (10, 10, 100, 100)
x = torch.randn(*shape, device='cuda')
w = torch.randn((10, 1, 5, 5), device='cuda')
for _ in range(100):
torch.nn.functional.conv2d(x, w, groups=10)
```
and similarly for backwards. I see these as the same to within measurement error.
| | Master Forward (us) | This PR Forward (us) |
|------------------:|:-------------------:|:--------------------:|
| Forward | 133.5 | 133.6 |
| Backward (input) | 1,102 | 1,119 |
| Backward (weight) | 2,220 | 2,217 |
Test Plan: Imported from OSS
Reviewed By: jbschlosser
Differential Revision: D29883676
Pulled By: ngimel
fbshipit-source-id: 9b2ac62cdd8a84e1a23ffcd66035b2b2fe2374d8
Summary:
Fixes https://github.com/pytorch/pytorch/issues/61924
The fused backward kernel was using the weight dtype to detect mixed precision usage, but the weights can be none and the `running_mean` and `running_var` can still be mixed precision. So, I update the check to look at those variables as well.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61962
Reviewed By: albanD
Differential Revision: D29825516
Pulled By: ngimel
fbshipit-source-id: d087fbf3bed1762770cac46c0dcec30c03a86fda
Summary:
Fixes https://github.com/pytorch/pytorch/issues/58816
- enhance the backward of `nn.SmoothL1Loss` to allow integral `target`
- add test cases in `test_nn.py` to check the `input.grad` between the integral input and its floating counterpart.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61112
Reviewed By: mrshenli
Differential Revision: D29775660
Pulled By: albanD
fbshipit-source-id: 544eabb6ce1ea13e1e79f8f18c70f148e92be508
Summary:
Fixes https://github.com/pytorch/pytorch/issues/61242
Previous code was wrongly checking if a tensor is a buffer in a module by comparing values; fix compares names instead.
Docs need some updating as well- current plan is to bump that to a separate PR, but I'm happy to do it here as well if preferred.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61429
Reviewed By: gchanan
Differential Revision: D29712341
Pulled By: jbschlosser
fbshipit-source-id: 41f29ab746505e60f13de42a9053a6770a3aac22
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/61584
add_relu is not working with broadcasting. This registers a scalar version of add_relu in native_functions that casts to tensor before calling the regular function. TensorIterator handles broadcasting analogously to existing add.
ghstack-source-id: 133480068
Test Plan: python3 test/test_nn.py TestAddRelu
Reviewed By: kimishpatel
Differential Revision: D29641768
fbshipit-source-id: 1b0ecfdb7eaf44afed83c9e9e74160493c048cbc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60517
This is to fix the module support on lazymodulefixin on the bug issue #60132
Check the link: https://github.com/pytorch/pytorch/issues/60132
We will have to update lazy_extension given the dependency on module.py and update the unit test as well.
Test Plan:
Unit test passes
torchrec test passes
Reviewed By: albanD
Differential Revision: D29274068
fbshipit-source-id: 1c20f7f0556e08dc1941457ed20c290868346980
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59987
Similar as GroupNorm, improve numerical stability of LayerNorm by Welford algorithm and pairwise sum.
Test Plan: buck test mode/dev-nosan //caffe2/test:nn -- "LayerNorm"
Reviewed By: ngimel
Differential Revision: D29115235
fbshipit-source-id: 5183346c3c535f809ec7d98b8bdf6d8914bfe790
Summary:
Fixes https://github.com/pytorch/pytorch/issues/24610
Aten Umbrella issue https://github.com/pytorch/pytorch/issues/24507
Related to https://github.com/pytorch/pytorch/issues/59765
The performance does not change between this PR and master with the following benchmark script:
<details>
<summary>Benchmark script</summary>
```python
import torch
import torch.nn as nn
import time
torch.manual_seed(0)
def _time():
torch.cuda.synchronize()
MS_PER_SECOND = 1000
return time.perf_counter() * MS_PER_SECOND
device = "cuda"
C = 30
softmax = nn.LogSoftmax(dim=1)
n_runs = 250
for reduction in ["none", "mean", "sum"]:
for N in [100_000, 500_000, 1_000_000]:
fwd_t = 0
bwd_t = 0
data = torch.randn(N, C, device=device)
target = torch.empty(N, dtype=torch.long, device=device).random_(0, C)
loss = nn.NLLLoss(reduction=reduction)
input = softmax(data)
for i in range(n_runs):
t1 = _time()
result = loss(input, target)
t2 = _time()
fwd_t = fwd_t + (t2 - t1)
fwd_avg = fwd_t / n_runs
print(
f"input size({N}, {C}), reduction: {reduction} "
f"forward time is {fwd_avg:.2f} (ms)"
)
print()
```
</details>
## master
```
input size(100000, 30), reduction: none forward time is 0.02 (ms)
input size(500000, 30), reduction: none forward time is 0.08 (ms)
input size(1000000, 30), reduction: none forward time is 0.15 (ms)
input size(100000, 30), reduction: mean forward time is 1.81 (ms)
input size(500000, 30), reduction: mean forward time is 8.24 (ms)
input size(1000000, 30), reduction: mean forward time is 16.46 (ms)
input size(100000, 30), reduction: sum forward time is 1.66 (ms)
input size(500000, 30), reduction: sum forward time is 8.24 (ms)
input size(1000000, 30), reduction: sum forward time is 16.46 (ms)
```
## this PR
```
input size(100000, 30), reduction: none forward time is 0.02 (ms)
input size(500000, 30), reduction: none forward time is 0.08 (ms)
input size(1000000, 30), reduction: none forward time is 0.15 (ms)
input size(100000, 30), reduction: mean forward time is 1.80 (ms)
input size(500000, 30), reduction: mean forward time is 8.24 (ms)
input size(1000000, 30), reduction: mean forward time is 16.46 (ms)
input size(100000, 30), reduction: sum forward time is 1.66 (ms)
input size(500000, 30), reduction: sum forward time is 8.24 (ms)
input size(1000000, 30), reduction: sum forward time is 16.46 (ms)
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60097
Reviewed By: mrshenli
Differential Revision: D29303099
Pulled By: ngimel
fbshipit-source-id: fc0d636543a79ea81158d286dcfb84043bec079a
Summary:
Before this change it was implemented with the assumption, that number of groups, input and output channels are the same, which is not always the case
Extend the implementation to support any number of output channels as long as number of groups equals to the number of input channels (i.e. kernel.size(1) == 1)
Fixes https://github.com/pytorch/pytorch/issues/60176
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60460
Reviewed By: albanD
Differential Revision: D29299693
Pulled By: malfet
fbshipit-source-id: 31130c71ce86535ccfba2f4929eee3e2e287b2f0
Summary:
Fixes #https://github.com/pytorch/pytorch/issues/50192
It has been discussed in the issue that, currently RNN apis do not support inputs with `seq_len=0` and the error message does not reflect this issue clearly. This PR is suggesting a solution to this issue, by adding a more clear error message that, none of RNN api (nn.RNN, nn.GRU and nn.LSTM) do not support `seq_len=0` for neither one-directional nor bi-directional layers.
```
import torch
input_size = 5
hidden_size = 6
rnn = torch.nn.GRU(input_size, hidden_size)
for seq_len in reversed(range(4)):
output, h_n = rnn(torch.zeros(seq_len, 10, input_size))
print('{}, {}'.format(output.shape, h_n.shape))
```
Previously was giving output as :
```
torch.Size([3, 10, 6]), torch.Size([1, 10, 6])
torch.Size([2, 10, 6]), torch.Size([1, 10, 6])
torch.Size([1, 10, 6]), torch.Size([1, 10, 6])
Traceback (most recent call last):
File "test.py", line 8, in <module>
output, h_n = rnn(torch.zeros(seq_len, 10, input_size))
File "/opt/miniconda3/lib/python3.8/site-packages/torch/nn/modules/module.py", line 727, in _call_impl
result = self.forward(*input, **kwargs)
File "/opt/miniconda3/lib/python3.8/site-packages/torch/nn/modules/rnn.py", line 739, in forward
result = _VF.gru(input, hx, self._flat_weights, self.bias, self.num_layers,
RuntimeError: stack expects a non-empty TensorList
```
However, after adding this PR, this error message change for any combination of
[RNN, GRU and LSTM] x [one-directional, bi-directional].
Let's illustrate the change with the following code snippet:
```
import torch
input_size = 5
hidden_size = 6
rnn = torch.nn.LSTM(input_size, hidden_size, bidirectional=True)
output, h_n = rnn(torch.zeros(0, 10, input_size))
```
would give output as following:
```
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
File "/fsx/users/iramazanli/pytorch/torch/nn/modules/module.py", line 1054, in _call_impl
return forward_call(*input, **kwargs)
File "/fsx/users/iramazanli/pytorch/torch/nn/modules/rnn.py", line 837, in forward
result = _VF.gru(input, hx, self._flat_weights, self.bias, self.num_layers,
RuntimeError: Expected sequence length to be larger than 0 in RNN
```
***********************************
The change for Packed Sequence didn't seem to be necessary because from the following code snippet error message looks clear about the issue:
```
import torch
import torch.nn.utils.rnn as rnn_utils
import torch.nn as nn
packed = rnn_utils.pack_sequence([])
```
returns:
```
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/fsx/users/iramazanli/pytorch/torch/nn/utils/rnn.py", line 398, in pack_sequence
return pack_padded_sequence(pad_sequence(sequences), lengths, enforce_sorted=enforce_sorted)
File "/fsx/users/iramazanli/pytorch/torch/nn/utils/rnn.py", line 363, in pad_sequence
return torch._C._nn.pad_sequence(sequences, batch_first, padding_value)
RuntimeError: received an empty list of sequences
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60269
Reviewed By: mrshenli
Differential Revision: D29299914
Pulled By: iramazanli
fbshipit-source-id: 5ca98faa28d4e6a5a2f7600a30049de384a3b132
Summary:
Partially addresses https://github.com/pytorch/pytorch/issues/49825 by improving the testing
- Rename some of the old tests that had "inplace_view" in their names, but actually mean "inplace_[update_]on_view" so there is no confusion with the naming
- Adds some tests in test_view_ops that verify basic behavior
- Add tests that creation meta is properly handled for no-grad, multi-output, and custom function cases
- Add test that verifies that in the cross dtype view case, the inplace views won't be accounted in the backward graph on rebase as mentioned in the issue.
- Update inference mode tests to also check in-place
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59891
Reviewed By: albanD
Differential Revision: D29272546
Pulled By: soulitzer
fbshipit-source-id: b12acf5f0e3f788167ebe268423cdb58481b56f6
Summary:
Fixes https://github.com/pytorch/pytorch/issues/27655
This PR adds a C++ and Python version of ReflectionPad3d with structured kernels. The implementation uses lambdas extensively to better share code from the backward and forward pass.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59791
Reviewed By: gchanan
Differential Revision: D29242015
Pulled By: jbschlosser
fbshipit-source-id: 18e692d3b49b74082be09f373fc95fb7891e1b56
Summary:
Following https://github.com/pytorch/pytorch/issues/59624 I observed some straggling failing tests on Ampere due to TF32 thresholds. This PR just twiddles some more thresholds to fix the (6) failing tests I saw on A100.
CC Flamefire ptrblck ngimel
Pull Request resolved: https://github.com/pytorch/pytorch/pull/60209
Reviewed By: gchanan
Differential Revision: D29220508
Pulled By: ngimel
fbshipit-source-id: 7c83187a246e1b3a24b181334117c0ccf2baf311
Summary:
Makes possible that the first register parametrization depends on a number of parameters rather than just one. Examples of these types of parametrizations are `torch.nn.utils.weight_norm` and low rank parametrizations via the multiplication of a `n x k` tensor by a `k x m` tensor with `k <= m, n`.
Follows the plan outlined in https://github.com/pytorch/pytorch/pull/33344#issuecomment-768574924. A short summary of the idea is: we call `right_inverse` when registering a parametrization to generate the tensors that we are going to save. If `right_inverse` returns a sequence of tensors, then we save them as `original0`, `original1`... If it returns a `Tensor` or a sequence of length 1, we save it as `original`.
We only allow to have many-to-one parametrizations in the first parametrization registered. The next parametrizations would need to be one-to-one.
There were a number of choices in the implementation:
If the `right_inverse` returns a sequence of parameters, then we unpack it in the forward. This is to allow to write code as:
```python
class Sum(nn.Module):
def forward(self, X, Y):
return X + Y
def right_inverse(Z):
return Z, torch.zeros_like(Z)
```
rather than having to unpack manually a list or a tuple within the `forward` function.
At the moment the errors are a bit all over the place. This is to avoid having to check some properties of `forward` and `right_inverse` when they are registered. I left this like this for now, but I believe it'd be better to call these functions when they are registered to make sure the invariants hold and throw errors as soon as possible.
The invariants are the following:
1. The following code should be well-formed
```python
X = module.weight
Y = param.right_inverse(X)
assert isinstance(Y, Tensor) or isinstance(Y, collections.Sequence)
Z = param(Y) if isisntance(Y, Tensor) else param(*Y)
```
in other words, if `Y` is a `Sequence` of `Tensor`s (we check also that the elements of the sequence are Tensors), then it is of the same length as the number parameters `param.forward` accepts.
2. Always: `X.dtype == Z.dtype and X.shape == Z.shape`. This is to protect the user from shooting themselves in the foot, as it's too odd for a parametrization to change the metadata of a tensor.
3. If it's one-to-one: `X.dtype == Y.dtype`. This is to be able to do `X.set_(Y)` so that if a user first instantiates the optimiser and then puts the parametrisation, then we reuse `X` and the user does not need to add a new parameter to the optimiser. Alas, this is not possible when the parametrisation is many-to-one. The current implementation of `spectral_norm` and `weight_norm` does not seem to care about this, so this would not be a regression. I left a warning in the documentation though, as this case is a bit tricky.
I'm still missing to go over the formatting of the documentation, I'll do that tomorrow.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58488
Reviewed By: soulitzer
Differential Revision: D29100708
Pulled By: albanD
fbshipit-source-id: b9e91f439cf6b5b54d5fa210ec97c889efb9da38
Summary:
Implements a number of changes discussed with soulitzer offline.
In particular:
- Initialise `u`, `v` in `__init__` rather than in `_update_vectors`
- Initialise `u`, `v` to some reasonable vectors by doing 15 power iterations at the start
- Simplify the code of `_reshape_weight_to_matrix` (and make it faster) by using `flatten`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59564
Reviewed By: ailzhang
Differential Revision: D29066238
Pulled By: soulitzer
fbshipit-source-id: 6a58e39ddc7f2bf989ff44fb387ab408d4a1ce3d
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/58950
Use tensor iterator's API to set grain size in order to parallelize gelu op.
ghstack-source-id: 130947174
Test Plan: test_gelu
Reviewed By: ezyang
Differential Revision: D28689819
fbshipit-source-id: 0a02066d47a4d9648323c5ec27d7e0e91f4c303a
Summary:
Make sure tests run explicitely without TF32 don't use TF32 operations
Fixes https://github.com/pytorch/pytorch/issues/52278
After the tf32 accuracy tolerance was increased to 0.05 this is the only remaining change required to fix the above issue (for TestNN.test_Conv3d_1x1x1_no_bias_cuda)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59624
Reviewed By: heitorschueroff
Differential Revision: D28996279
Pulled By: ngimel
fbshipit-source-id: 7f1b165fd52cfa0898a89190055b7a4b0985573a
Summary:
As per title. Resolves https://github.com/pytorch/pytorch/issues/56683.
`gradgradcheck` will fail once `target.requires_grad() == True` because of the limitations of the current double backward implementation.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/59447
Reviewed By: agolynski
Differential Revision: D28910140
Pulled By: albanD
fbshipit-source-id: 20934880eb4d22bec34446a6d1be0a38ef95edc7
Summary:
This PR introduces a helper function named `torch.nn.utils.skip_init()` that accepts a module class object + `args` / `kwargs` and instantiates the module while skipping initialization of parameter / buffer values. See discussion at https://github.com/pytorch/pytorch/issues/29523 for more context. Example usage:
```python
import torch
m = torch.nn.utils.skip_init(torch.nn.Linear, 5, 1)
print(m.weight)
m2 = torch.nn.utils.skip_init(torch.nn.Linear, 5, 1, device='cuda')
print(m2.weight)
m3 = torch.nn.utils.skip_init(torch.nn.Linear, in_features=5, out_features=1)
print(m3.weight)
```
```
Parameter containing:
tensor([[-3.3011e+28, 4.5915e-41, -3.3009e+28, 4.5915e-41, 0.0000e+00]],
requires_grad=True)
Parameter containing:
tensor([[-2.5339e+27, 4.5915e-41, -2.5367e+27, 4.5915e-41, 0.0000e+00]],
device='cuda:0', requires_grad=True)
Parameter containing:
tensor([[1.4013e-45, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00]],
requires_grad=True)
```
Bikeshedding on the name / namespace is welcome, as well as comments on the design itself - just wanted to get something out there for discussion.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57555
Reviewed By: zou3519
Differential Revision: D28640613
Pulled By: jbschlosser
fbshipit-source-id: 5654f2e5af5530425ab7a9e357b6ba0d807e967f
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48919
move data indexing utils
parallel inference contiguous path
parallel inference channels last path
add dim apply
optimize update stats
add channels last support for backward
Revert "add channels last support for backward"
This reverts commit cc5e29dce44395250f8e2abf9772f0b99f4bcf3a.
Revert "optimize update stats"
This reverts commit 7cc6540701448b9cfd5833e36c745b5015ae7643.
Revert "add dim apply"
This reverts commit b043786d8ef72dee5cf85b5818fcb25028896ecd.
bug fix
add batchnorm nhwc test for cpu, including C=1 and HW=1
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D25399468
Pulled By: VitalyFedyunin
fbshipit-source-id: a4cd7a09cd4e1a8f5cdd79c7c32c696d0db386bd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/48918
enable test case on AvgPool2d channels last for CPU
Test Plan: Imported from OSS
Reviewed By: glaringlee
Differential Revision: D25399466
Pulled By: VitalyFedyunin
fbshipit-source-id: 9477b0c281c0de5ed981a97e2dcbe6072d7f0aef
Summary:
Adds a new file under `torch/nn/utils/parametrizations.py` which should contain all the parametrization implementations
For spectral_norm we add the `SpectralNorm` module which can be registered using `torch.nn.utils.parametrize.register_parametrization` or using a wrapper: `spectral_norm`, the same API the old implementation provided.
Most of the logic is borrowed from the old implementation:
- Just like the old implementation, there should be cases when retrieving the weight should perform another power iteration (thus updating the weight) and cases where it shouldn't. For example in eval mode `self.training=True`, we do not perform power iteration.
There are also some differences/difficulties with the new implementation:
- Using new parametrization functionality as-is there doesn't seem to be a good way to tell whether a 'forward' call was the result of parametrizations are unregistered (and leave_parametrizations=True) or when the injected property's getter was invoked. The issue is that we want perform power iteration in the latter case but not the former, but we don't have this control as-is. So, in this PR I modified the parametrization functionality to change the module to eval mode before triggering their forward call
- Updates the vectors based on weight on initialization to fix https://github.com/pytorch/pytorch/issues/51800 (this avoids silently update weights in eval mode). This also means that we perform twice any many power iterations by the first forward.
- right_inverse is just the identity for now, but maybe it should assert that the passed value already satisfies the constraints
- So far, all the old spectral_norm tests have been cloned, but maybe we don't need so much testing now that the core functionality is already well tested
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57784
Reviewed By: ejguan
Differential Revision: D28413201
Pulled By: soulitzer
fbshipit-source-id: e8f1140f7924ca43ae4244c98b152c3c554668f2
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55189
Currently EmbeddingBag and it variants support either int32 or int64 indices/offsets. We have use cases where there are mix of int32 and int64 indices which are not supported yet. To avoid introducing too many branches we could simply cast offsets type to indices type when they are not the same.
Test Plan: unit tests
Reviewed By: allwu
Differential Revision: D27482738
fbshipit-source-id: deeadd391d49ff65d17d016092df1839b82806cc
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57558Fixes#53359
If someone directly saves an nn.LSTM in PyTorch 1.7 and then loads it in PyTorch
1.8, it errors out with the following:
```
(In PyTorch 1.7)
import torch
model = torch.nn.LSTM(2, 3)
torch.save(model, 'lstm17.pt')
(In PyTorch 1.8)
model = torch.load('lstm17.pt')
AttributeError: 'LSTM' object has no attribute 'proj_size'
```
Although we do not officially support this (directly saving modules via
torch.save), it used to work and the fix is very simple. This PR adds an
extra line to `__setstate__`: if the state we are passed does not have
a `proj_size` attribute, we assume it was saved from PyTorch 1.7 and
older and set `proj_size` equal to 0.
Test Plan:
I wrote a test that tests `__setstate__`. But also,
Run the following:
```
(In PyTorch 1.7)
import torch
x = torch.ones(32, 5, 2)
model = torch.nn.LSTM(2, 3)
torch.save(model, 'lstm17.pt')
y17 = model(x)
(Using this PR)
model = torch.load('lstm17.pt')
x = torch.ones(32, 5, 2)
y18 = model(x)
```
and finally compare y17 and y18.
Reviewed By: mrshenli
Differential Revision: D28198477
Pulled By: zou3519
fbshipit-source-id: e107d1ebdda23a195a1c3574de32a444eeb16191
Summary:
Fix a numerical issue of CUDA channels-last SyncBatchNorm
The added test is a repro for the numerical issue. Thanks for the help from jjsjann123 who identified the root cause. Since pytorch SBN channels-last code was migrated from [nvidia/apex](https://github.com/nvidia/apex), apex SBN channels-last also has this issue. We will submit a fix there soon.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/57077
Reviewed By: mruberry
Differential Revision: D28107672
Pulled By: ngimel
fbshipit-source-id: 0c80e79ddb48891058414ad8a9bedd80f0f7f8df
Summary:
Fixes https://github.com/pytorch/pytorch/issues/45687
Fix changes the input size check for `InstanceNorm*d` to be more restrictive and correctly reject sizes with only a single spatial element, regardless of batch size, to avoid infinite variance.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56659
Reviewed By: pbelevich
Differential Revision: D27948060
Pulled By: jbschlosser
fbshipit-source-id: 21cfea391a609c0774568b89fd241efea72516bb
Summary:
Fixes https://github.com/pytorch/pytorch/issues/56380
BC-breaking note:
This changes the behavior of full backward hooks as they will now fire properly even if no input to the Module require gradients.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56693
Reviewed By: ezyang
Differential Revision: D27947030
Pulled By: albanD
fbshipit-source-id: e8353d769ba5a2c1b6bdf3b64e2d61308cf624a2
Summary:
Fixes https://github.com/pytorch/pytorch/issues/55587
The fix converts the binary `TensorIterator` used by softplus backwards to a ternary one, adding in the original input for comparison against `beta * threshold`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/56484
Reviewed By: malfet
Differential Revision: D27908372
Pulled By: jbschlosser
fbshipit-source-id: 73323880a5672e0242879690514a17886cbc29cd
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/55237
In this PR, we reenable fast-gradcheck and resolve misc issues that arise:
Before landing this PR, land #55182 so that slow tests are still being run periodically.
Bolded indicates the issue is handled in this PR, otherwise it is handled in a previous PR.
**Non-determinism issues**:
- ops that do not have deterministic implementation (as documented https://pytorch.org/docs/stable/generated/torch.use_deterministic_algorithms.html#torch.use_deterministic_algorithms)
- test_pad_cuda (replication_pad2d) (test_nn)
- interpolate (test_nn)
- cummin, cummax (scatter_add_cuda_kernel) (test_ops)
- test_fn_gradgrad_prod_cpu_float64 (test_ops)
Randomness:
- RRelu (new module tests) - we fix by using our own generator as to avoid messing with user RNG state (handled in #54480)
Numerical precision issues:
- jacobian mismatch: test_gelu (test_nn, float32, not able to replicate locally) - we fixed this by disabling for float32 (handled in previous PR)
- cholesky_solve (test_linalg): #56235 handled in previous PR
- **cumprod** (test_ops) - #56275 disabled fast gradcheck
Not yet replicated:
- test_relaxed_one_hot_categorical_2d (test_distributions)
Test Plan: Imported from OSS
Reviewed By: albanD
Differential Revision: D27920906
fbshipit-source-id: 894dd7bf20b74f1a91a5bc24fe56794b4ee24656
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}