Michael Suo
dbe850af5b
[jit] do the code reorg ( #33851 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33851
Rationale and context described in #33828 .
Script to reproduce the move:
https://gist.github.com/suo/16cbefaaeb67ca5a7c6caffd49b7f6e9
ghstack-source-id: 99079645
Test Plan: Make sure CI passes
Reviewed By: jamesr66a
Differential Revision: D20133869
fbshipit-source-id: 390e9241a9c85366d9005c492ac31f10aa96488e
2020-02-27 13:02:51 -08:00
Omkar Salpekar
24dd800e6a
[Dist Autograd] Functional API for Dist Autograd and Dist Optimizer ( #33711 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33711
Fixed #33480
This makes `dist_autograd.backward` and `dist_optimizer.step` functional by making the user explicitly pass in the `context_id` as opposed to relying on the confusing thread_local context_id.
This diff incorporates these API changes and all places where these functions are called.
More concretely, this code:
```
with dist_autograd.context():
# Forward pass.
dist_autograd.backward([loss.sum()])
dist_optim.step()
```
should now be written as follows:
```
with dist_autograd.context() as context_id:
# Forward pass.
dist_autograd.backward(context_id, [loss.sum()])
dist_optim.step(context_id)
```
Test Plan: Ensuring all existing dist_autograd and dist_optimizer tests pass with the new API. Also added a new test case for input checking.
Differential Revision: D20011710
fbshipit-source-id: 216e12207934a2a79c7223332b97c558d89d4d65
2020-02-26 19:08:28 -08:00
Elias Ellison
857eb4145e
[JIT] add support for torch.cdist ( #33737 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/33737
Test Plan: Imported from OSS
Differential Revision: D20121916
Pulled By: eellison
fbshipit-source-id: b0427bbfd3ade1f3129c4a95a542fbc32c3abd76
2020-02-26 18:37:37 -08:00
Elias Ellison
f31b1d3453
[JIT] add support for lu_unpack ( #33736 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/33736
Test Plan: Imported from OSS
Differential Revision: D20121914
Pulled By: eellison
fbshipit-source-id: 1136f4d7678a2233129aefe3e30234af385b8353
2020-02-26 18:37:33 -08:00
Elias Ellison
4543cf4eb1
[JIT] add support for torch.lu to torchscript ( #33724 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33724
Fix for https://github.com/pytorch/pytorch/issues/33381 , partial fix of https://github.com/pytorch/pytorch/issues/30786
Test Plan: Imported from OSS
Differential Revision: D20077321
Pulled By: eellison
fbshipit-source-id: a1e6a0370712b36c9f66979098ac2f9d500ca5f6
2020-02-26 18:37:28 -08:00
Ahmad Salim Al-Sibahi
24659d28a1
Feature/vonmises upstream ( #33418 )
...
Summary:
Third try of https://github.com/pytorch/pytorch/issues/33177 😄
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33418
Differential Revision: D20069683
Pulled By: ezyang
fbshipit-source-id: f58e45e91b672bfde2e41a4480215ba4c613f9de
2020-02-26 08:19:12 -08:00
Michael Carilli
fc6a153688
[WIP] Reanimate gradient scaling API with original scale update heuristic ( #33366 )
...
Summary:
Also, windows memory failures responsible for the earlier reversion have been fixed.
This PR (initially) contains 2 commits:
* a revert of the revert
* all changes to implement the original Apex scale update heuristic, squashed into a single commit for easier diff review
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33366
Differential Revision: D20099026
Pulled By: ngimel
fbshipit-source-id: 339b9b6bd5134bf055057492cd1eedb7e4461529
2020-02-25 19:00:34 -08:00
peter
adbe289870
Update MKL to 2020.0.166 for Windows ( #33690 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/33690
Differential Revision: D20089300
Pulled By: ezyang
fbshipit-source-id: 887c006fbdb2c837f0a1c607a196811f44f1fb35
2020-02-24 22:43:34 -08:00
Michael Suo
dc3d47110a
[docs] add experimental warning to TorchScript classes in language reference ( #33697 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33697
reference
Test Plan: Imported from OSS
Differential Revision: D20070220
Pulled By: suo
fbshipit-source-id: 9828d876afed59203cc472eaf0134d52d399069e
2020-02-24 14:01:19 -08:00
anjali411
13e4ee7883
Added tensor.is_complex(), is_complex and dtype.is_complex py binding, tensor printing, and dixed the scalar type returned for complex float ( #33268 )
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/33268
Test Plan: Imported from OSS
Differential Revision: D19907698
Pulled By: anjali411
fbshipit-source-id: c3ce2e99fc09da91a90a8fb94e5525a00bb23703
2020-02-20 13:38:01 -08:00
Edward Yang
ae53f8dd25
Revert D19859905: [pytorch][PR] Gradient scaling API
...
Test Plan: revert-hammer
Differential Revision:
D19859905
Original commit changeset: bb8ae6966214
fbshipit-source-id: 28f1c93e8a00e3a4bbe8cc981499b15468f0b970
2020-02-14 11:03:27 -08:00
Nicki Skafte
4bef344210
Implementation of mixture distributions ( #22742 )
...
Summary:
Addressing issue https://github.com/pytorch/pytorch/issues/18125
This implements a mixture distributions, where all components are from the same distribution family. Right now the implementation supports the ```mean, variance, sample, log_prob``` methods.
cc: fritzo and neerajprad
- [x] add import and `__all__` string in `torch/distributions/__init__.py`
- [x] register docs in docs/source/distributions.rst
### Tests
(all tests live in tests/distributions.py)
- [x] add an `Example(MixtureSameFamily, [...])` to the `EXAMPLES` list,
populating `[...]` with three examples:
one with `Normal`, one with `Categorical`, and one with `MultivariateNormal`
(to exercise, `FloatTensor`, `LongTensor`, and nontrivial `event_dim`)
- [x] add a `test_mixture_same_family_shape()` to `TestDistributions`. It would be good to test this with both `Normal` and `MultivariateNormal`
- [x] add a `test_mixture_same_family_log_prob()` to `TestDistributions`.
- [x] add a `test_mixture_same_family_sample()` to `TestDistributions`.
- [x] add a `test_mixture_same_family_shape()` to `TestDistributionShapes`
### Triaged for follup-up PR?
- support batch shape
- implement `.expand()`
- implement `kl_divergence()` in torch/distributions/kl.py
Pull Request resolved: https://github.com/pytorch/pytorch/pull/22742
Differential Revision: D19899726
Pulled By: ezyang
fbshipit-source-id: 9c816e83a2ef104fe3ea3117c95680b51c7a2fa4
2020-02-14 10:31:56 -08:00
George Guanheng Zhang
0c98939b7b
Revert D19899550: [pytorch][PR] Second try on Von Mises: Make it JIT compatible
...
Test Plan: revert-hammer
Differential Revision:
D19899550
Original commit changeset: fbcdd9bc9143
fbshipit-source-id: c8a675a8b53f884acd0e6c57bc7aa15faf83d5d6
2020-02-14 08:42:16 -08:00
Ahmad Salim Al-Sibahi
b1583ceb1e
Second try on Von Mises: Make it JIT compatible ( #33177 )
...
Summary:
Follow up from https://github.com/pytorch/pytorch/issues/17168 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33177
Differential Revision: D19899550
Pulled By: ezyang
fbshipit-source-id: fbcdd9bc91438164bcb2b1cbc314c765520754e1
2020-02-14 07:16:41 -08:00
Michael Carilli
40246fa63c
Gradient scaling API ( #26512 )
...
Summary:
This PR implements the gradient scaling API that mruberry, jjsjann123, ngimel, zdevito, gchanan and I have been discussing. Relevant issue/RFC: https://github.com/pytorch/pytorch/issues/25081 .
Volume-wise, this PR is mostly documentation and tests. The Python API (found entirely in `torch/cuda/amp/amp_scaler.py`) is lightweight . The exposed functions are intended to make the implementation and control flow of gradient scaling convenient, intuitive, and performant.
The API is probably easiest to digest by looking at the documentation and examples. `docs/source/amp.rst` is the homepage for the Automatic Mixed Precision package. `docs/source/notes/amp_examples.rst` includes several examples demonstrating common but not-immediately-obvious use cases. Examples are backed by tests in `test_cuda.py` (and thankfully the tests pass :P).
Two small utility kernels have been added in `native/cuda/AmpKernels.cu` to improve performance and avoid host-device synchronizations wherever possible.
Existing optimizers, both in the wild and in Pytorch core, do not need to change to use the scaling API.
However, the API was also designed to establish a contract between user scripts and optimizers such that writers of _new_ custom optimizers have the control points they need to implement fast, optionally sync-free updates. User scripts that obey the scaling API can drop such custom optimizers in and reap performance benefits without having to change anything aside from the optimizer constructor itself. [I know what the contract with custom optimizers should be](35829f24ef/torch/cuda/amp/amp_scaler.py (L179-L184)https://github.com/pytorch/pytorch/issues/25081 . The gradient scaling API is intended to be orthogonal/modular relative to autocasting. Without auto-casting the gradient scaling API is fully use-_able_, but not terribly use-_ful_, so it's up to you guys whether you want to wait until auto-casting is ready before merging the scaling API as well.
### Todo
- [ ] How do I get c10 registered status for my two custom kernels? They're very simple.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/26512
Differential Revision: D19859905
Pulled By: mruberry
fbshipit-source-id: bb8ae6966214718dfee11345db824389e4286923
2020-02-13 11:06:06 -08:00
Ilia Cherniavskii
04829e924a
Update CPU threading doc ( #33083 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/33083
Added more recommendations, some notes and warning
Test Plan: cd docs ; make html
Differential Revision: D19829133
Pulled By: ilia-cher
fbshipit-source-id: b9fbd89f5875b3ce35cc42ba75a3b44bb132c506
2020-02-11 14:13:51 -08:00
Shinichiro Hamaji
478356aeec
Fix broken links in governance.rst
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/30815
Differential Revision: D19697401
Pulled By: ezyang
fbshipit-source-id: d7e1a1b54039624f471b6cfb568428feb73060f4
2020-02-04 14:26:09 -08:00
Shinichiro Hamaji
67706187fb
Fix a broken link in contribution_guide.rst
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/30814
Differential Revision: D19697403
Pulled By: ezyang
fbshipit-source-id: b01fd0e189b3bc7ccaa197c9c64e12fee70a6310
2020-02-04 14:14:25 -08:00
BowenBao
10183061eb
[ONNX] Update ONNX landing page since 1.3 ( #32805 )
...
Summary:
* New ops supported for exporting.
* Updates on support for tensor indexing and dynamic list of tensors.
* lara-hdr, spandantiwari Should we also include updates on torchvision support in this page?
cc houseroad, neginraoof Please review if I have missed anything.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/32805
Reviewed By: hl475
Differential Revision: D19635699
Pulled By: houseroad
fbshipit-source-id: b6be4fce641f852dcbceed20b4433f4037d8024a
2020-02-03 10:38:29 -08:00
Edward Z. Yang
1177191c8e
Synchronize with ShipIt.
...
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
2020-01-21 13:39:28 -05:00
Brian Wignall
f326045b37
Fix typos, via a Levenshtein-type corrector ( #31523 )
...
Summary:
Should be non-semantic.
Uses https://en.wikipedia.org/wiki/Wikipedia:Lists_of_common_misspellings/For_machines to find likely typos, with https://github.com/bwignall/typochecker to help automate the checking.
Uses an updated version of the tool used in https://github.com/pytorch/pytorch/pull/30606 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31523
Differential Revision: D19216749
Pulled By: mrshenli
fbshipit-source-id: 7fd489cb9a77cd7e4950c1046f925d57524960ea
2020-01-17 16:03:19 -08:00
anjali411
5b815d980e
Added cummin
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/32238
Differential Revision: D19416791
Pulled By: anjali411
fbshipit-source-id: 5aadc0a7a55af40d76f444ab7d7d47ec822f55a5
2020-01-17 10:51:58 -08:00
Shen Li
322f34b245
Adding DDP Design Note
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/32158
Test Plan: Imported from OSS
Differential Revision: D19405980
Pulled By: mrshenli
fbshipit-source-id: 808ef1c71b637546f8872375bf1828967b1a5a60
2020-01-15 14:10:45 -08:00
Vamshi Chowdary
05088da8e9
[pytorch][PR] Fixed error in sample code of documentation ( #31682 )
...
Summary:
"in_features" and "out_features" are not defined. Possibly a typo. They should be "input_features" and "output_features" instead
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31682
Differential Revision: D19251685
Pulled By: zou3519
fbshipit-source-id: ac9e524e792a1853a16e8876d76b908495d8f35e
2020-01-15 10:34:07 -08:00
anjali411
8dc67a014f
Add cummax
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/32169
Differential Revision: D19393236
Pulled By: anjali411
fbshipit-source-id: 5dac6b0a4038eb48458d4a0b253418daeccbb6bc
2020-01-14 17:19:10 -08:00
Zafar Takhirov
701ca68882
Docs entry for the is_quantized
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/32075
Test Plan: Imported from OSS
Differential Revision: D19353861
Pulled By: z-a-f
fbshipit-source-id: 4249216ac9a4af354a251c62181d65bc14cbfd3e
2020-01-13 13:54:35 -08:00
Shen Li
62f93443e5
Explain RPC behavior when using Tensor as arg or return value
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/31968
Test Plan: Imported from OSS
Differential Revision: D19321380
Pulled By: mrshenli
fbshipit-source-id: e3431f1f02963cc8d8266a420ab03866106f26ac
2020-01-09 16:42:24 -08:00
Bram Wasti
021e1e20c1
Revert D19320493: Javadoc changes
...
Test Plan: revert-hammer
Differential Revision:
D19320493
Original commit changeset: cc76b2a2acbe
fbshipit-source-id: 3b36dd2d2591acc60a06a421dd625c21adbe578a
2020-01-09 14:23:30 -08:00
Jessica Lin
26f552a3d1
Javadoc changes ( #31956 )
...
Summary:
- Add Javadoc url in index.rst
- Delete no longer needed java rst files
- Remove intersphinx extension from conf.oy
- Remove javasphinx from docs/requirements.txt
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31956
Differential Revision: D19320493
Pulled By: jlin27
fbshipit-source-id: cc76b2a2acbe2ecdabcd3339e1cc3182f0c906ae
2020-01-09 10:55:24 -08:00
xiaobing.zhang
9ba6a768de
Add op bitwise_or ( #31559 )
...
Summary:
ezyang , this PR add bitwise_or operator as https://github.com/pytorch/pytorch/pull/31104 .
Benchmark script :
```
import timeit
import torch
torch.manual_seed(1)
for n, t in [(10, 100000),(1000, 10000)]:
print('__or__ (a.numel() == {}) for {} times'.format(n, t))
for device in ('cpu', 'cuda'):
for dtype in ('torch.int8', 'torch.uint8', 'torch.int16', 'torch.int32', 'torch.int64'):
print(f'device: {device}, dtype: {dtype}, {t} times', end='\t\t')
print(timeit.timeit(f'a | b\nif "{device}" == "cuda": torch.cuda.synchronize()', setup=f'import torch; a = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}"); b = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}")', number=t))
for n, t in [(10, 100000),(1000, 10000)]:
print('__ior__ (a.numel() == {}) for {} times'.format(n, t))
for device in ('cpu', 'cuda'):
for dtype in ('torch.int8', 'torch.uint8', 'torch.int16', 'torch.int32', 'torch.int64'):
print(f'device: {device}, dtype: {dtype}, {t} times', end='\t\t')
print(timeit.timeit(f'a | b\nif "{device}" == "cuda": torch.cuda.synchronize()', setup=f'import torch; a = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}"); b = torch.tensor(5, dtype = {dtype}, device="{device}")', number=t))
```
Device: **Tesla P100, skx-8180**
Cuda verison: **9.0.176**
Before:
```
__or__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.17616272252053022
device: cpu, dtype: torch.uint8, 100000 times 0.17148233391344547
device: cpu, dtype: torch.int16, 100000 times 0.17616403382271528
device: cpu, dtype: torch.int32, 100000 times 0.17717823758721352
device: cpu, dtype: torch.int64, 100000 times 0.1801931718364358
device: cuda, dtype: torch.int8, 100000 times 1.270583058707416
device: cuda, dtype: torch.uint8, 100000 times 1.2636413089931011
device: cuda, dtype: torch.int16, 100000 times 1.2839747751131654
device: cuda, dtype: torch.int32, 100000 times 1.2548385225236416
device: cuda, dtype: torch.int64, 100000 times 1.2650810535997152
__or__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.031136621721088886
device: cpu, dtype: torch.uint8, 10000 times 0.030786747112870216
device: cpu, dtype: torch.int16, 10000 times 0.02391665056347847
device: cpu, dtype: torch.int32, 10000 times 0.024147341027855873
device: cpu, dtype: torch.int64, 10000 times 0.024414129555225372
device: cuda, dtype: torch.int8, 10000 times 0.12741921469569206
device: cuda, dtype: torch.uint8, 10000 times 0.1249831635504961
device: cuda, dtype: torch.int16, 10000 times 0.1283819805830717
device: cuda, dtype: torch.int32, 10000 times 0.12591975275427103
device: cuda, dtype: torch.int64, 10000 times 0.12655890546739101
__ior__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.3908365070819855
device: cpu, dtype: torch.uint8, 100000 times 0.38267823681235313
device: cpu, dtype: torch.int16, 100000 times 0.38239253498613834
device: cpu, dtype: torch.int32, 100000 times 0.3817988149821758
device: cpu, dtype: torch.int64, 100000 times 0.3901665909215808
device: cuda, dtype: torch.int8, 100000 times 1.4211318120360374
device: cuda, dtype: torch.uint8, 100000 times 1.4215159295126796
device: cuda, dtype: torch.int16, 100000 times 1.4307750314474106
device: cuda, dtype: torch.int32, 100000 times 1.4123614141717553
device: cuda, dtype: torch.int64, 100000 times 1.4480243818834424
__ior__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.06468924414366484
device: cpu, dtype: torch.uint8, 10000 times 0.06442475505173206
device: cpu, dtype: torch.int16, 10000 times 0.05267547257244587
device: cpu, dtype: torch.int32, 10000 times 0.05286940559744835
device: cpu, dtype: torch.int64, 10000 times 0.06211103219538927
device: cuda, dtype: torch.int8, 10000 times 0.15332304500043392
device: cuda, dtype: torch.uint8, 10000 times 0.15353196952492
device: cuda, dtype: torch.int16, 10000 times 0.15300503931939602
device: cuda, dtype: torch.int32, 10000 times 0.15274472255259752
device: cuda, dtype: torch.int64, 10000 times 0.1512152962386608
```
After:
```
__or__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.2465507509186864
device: cpu, dtype: torch.uint8, 100000 times 0.2472386620938778
device: cpu, dtype: torch.int16, 100000 times 0.2469814233481884
device: cpu, dtype: torch.int32, 100000 times 0.2535214088857174
device: cpu, dtype: torch.int64, 100000 times 0.24855613708496094
device: cuda, dtype: torch.int8, 100000 times 1.4351346511393785
device: cuda, dtype: torch.uint8, 100000 times 1.4434308474883437
device: cuda, dtype: torch.int16, 100000 times 1.4520929995924234
device: cuda, dtype: torch.int32, 100000 times 1.4456610176712275
device: cuda, dtype: torch.int64, 100000 times 1.4580101007595658
__or__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.029985425993800163
device: cpu, dtype: torch.uint8, 10000 times 0.03024935908615589
device: cpu, dtype: torch.int16, 10000 times 0.026356655173003674
device: cpu, dtype: torch.int32, 10000 times 0.027377349324524403
device: cpu, dtype: torch.int64, 10000 times 0.029163731262087822
device: cuda, dtype: torch.int8, 10000 times 0.14540370367467403
device: cuda, dtype: torch.uint8, 10000 times 0.1456305105239153
device: cuda, dtype: torch.int16, 10000 times 0.1450125053524971
device: cuda, dtype: torch.int32, 10000 times 0.1472016740590334
device: cuda, dtype: torch.int64, 10000 times 0.14709716010838747
__ior__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.27195510920137167
device: cpu, dtype: torch.uint8, 100000 times 0.2692424338310957
device: cpu, dtype: torch.int16, 100000 times 0.27726674638688564
device: cpu, dtype: torch.int32, 100000 times 0.2815811652690172
device: cpu, dtype: torch.int64, 100000 times 0.2852728571742773
device: cuda, dtype: torch.int8, 100000 times 1.4743850827217102
device: cuda, dtype: torch.uint8, 100000 times 1.4766502184793353
device: cuda, dtype: torch.int16, 100000 times 1.4774163831025362
device: cuda, dtype: torch.int32, 100000 times 1.4749693805351853
device: cuda, dtype: torch.int64, 100000 times 1.5772947426885366
__ior__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.03614502027630806
device: cpu, dtype: torch.uint8, 10000 times 0.03619729354977608
device: cpu, dtype: torch.int16, 10000 times 0.0319912089034915
device: cpu, dtype: torch.int32, 10000 times 0.03319283854216337
device: cpu, dtype: torch.int64, 10000 times 0.0343862259760499
device: cuda, dtype: torch.int8, 10000 times 0.1581476852297783
device: cuda, dtype: torch.uint8, 10000 times 0.15974601730704308
device: cuda, dtype: torch.int16, 10000 times 0.15957212820649147
device: cuda, dtype: torch.int32, 10000 times 0.16002820804715157
device: cuda, dtype: torch.int64, 10000 times 0.16129320487380028
```
Fix https://github.com/pytorch/pytorch/issues/24511 , https://github.com/pytorch/pytorch/issues/24515 , https://github.com/pytorch/pytorch/issues/24658 , https://github.com/pytorch/pytorch/issues/24662 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31559
Differential Revision: D19315875
Pulled By: ezyang
fbshipit-source-id: 4a3ca88fdafbeb796079687e676228111eb44aad
2020-01-08 15:06:30 -08:00
Jessica Lin
c888473b57
Restructure docs organization and naming ( #31849 )
...
Summary:
* Rename “Other Languages” → “Language Bindings”
* Move the Community section to the bottom
* Move "Language Bindings" above "Python API"
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31849
Differential Revision: D19290966
Pulled By: jlin27
fbshipit-source-id: 30b579e032a9fb1636e4afc7bbbd85a2708f637d
2020-01-07 11:16:53 -08:00
Rohan Varma
a561a8448b
minor doc tweak to use mp.spawn in example ( #30381 )
...
Summary:
Per pietern's comment in https://github.com/pytorch/pytorch/issues/30022 , we can make this example launcher a bit simpler by using `torch.multiprocessing`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30381
Differential Revision: D19292080
Pulled By: rohan-varma
fbshipit-source-id: 018ace945601166ef3af05d8c3e69d900bd77c3b
2020-01-06 22:19:01 -08:00
xiaobing.zhang
b47e9b97a2
Add op bitwise_and ( #31104 )
...
Summary:
Refer to https://github.com/pytorch/pytorch/pull/25665 , add `bitwise_and` operator.
Benchmark script :
```
import timeit
#for __and__
for n, t in [(10, 100000),(1000, 10000)]:
print('__and__ (a.numel() == {}) for {} times'.format(n, t))
for device in ('cpu', 'cuda'):
for dtype in ('torch.int8', 'torch.uint8', 'torch.int16', 'torch.int32', 'torch.int64'):
print(f'device: {device}, dtype: {dtype}, {t} times', end='\t\t')
print(timeit.timeit(f'a & b\nif "{device}" == "cuda": torch.cuda.synchronize()', setup=f'import torch; a = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}"); b = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}")', number=t))
#for __iand__
for n, t in [(10, 100000),(1000, 10000)]:
print('__iand__ (a.numel() == {}) for {} times'.format(n, t))
for device in ('cpu', 'cuda'):
for dtype in ('torch.int8', 'torch.uint8', 'torch.int16', 'torch.int32', 'torch.int64'):
print(f'device: {device}, dtype: {dtype}, {t} times', end='\t\t')
print(timeit.timeit(f'a & b\nif "{device}" == "cuda": torch.cuda.synchronize()', setup=f'import torch; a = torch.randint(0, 10, ({n},), dtype = {dtype}, device="{device}"); b = torch.tensor(5, dtype = {dtype}, device="{device}")', number=t))
```
Device: **Tesla P100, skx-8180**
Cuda verison: **9.0.176**
Before:
```
__and__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.1766007635742426
device: cpu, dtype: torch.uint8, 100000 times 0.17322628945112228
device: cpu, dtype: torch.int16, 100000 times 0.17650844901800156
device: cpu, dtype: torch.int32, 100000 times 0.17711848113685846
device: cpu, dtype: torch.int64, 100000 times 0.18240160401910543
device: cuda, dtype: torch.int8, 100000 times 1.273967768996954
device: cuda, dtype: torch.uint8, 100000 times 1.2778537990525365
device: cuda, dtype: torch.int16, 100000 times 1.2753686187788844
device: cuda, dtype: torch.int32, 100000 times 1.2797665279358625
device: cuda, dtype: torch.int64, 100000 times 1.2933144550770521
__and__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.031139614060521126
device: cpu, dtype: torch.uint8, 10000 times 0.03091452084481716
device: cpu, dtype: torch.int16, 10000 times 0.022756479680538177
device: cpu, dtype: torch.int32, 10000 times 0.025045674294233322
device: cpu, dtype: torch.int64, 10000 times 0.024164282716810703
device: cuda, dtype: torch.int8, 10000 times 0.12820732593536377
device: cuda, dtype: torch.uint8, 10000 times 0.12775669433176517
device: cuda, dtype: torch.int16, 10000 times 0.12697868794202805
device: cuda, dtype: torch.int32, 10000 times 0.12832533661276102
device: cuda, dtype: torch.int64, 10000 times 0.1280576130375266
__iand__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.3687064303085208
device: cpu, dtype: torch.uint8, 100000 times 0.36253443732857704
device: cpu, dtype: torch.int16, 100000 times 0.362891579978168
device: cpu, dtype: torch.int32, 100000 times 0.37680106051266193
device: cpu, dtype: torch.int64, 100000 times 0.3689364707097411
device: cuda, dtype: torch.int8, 100000 times 1.419940729625523
device: cuda, dtype: torch.uint8, 100000 times 1.4247053815051913
device: cuda, dtype: torch.int16, 100000 times 1.4191444097086787
device: cuda, dtype: torch.int32, 100000 times 1.4305962566286325
device: cuda, dtype: torch.int64, 100000 times 1.4567416654899716
__iand__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.06224383972585201
device: cpu, dtype: torch.uint8, 10000 times 0.06205617543309927
device: cpu, dtype: torch.int16, 10000 times 0.05016433447599411
device: cpu, dtype: torch.int32, 10000 times 0.05216377507895231
device: cpu, dtype: torch.int64, 10000 times 0.06139362137764692
device: cuda, dtype: torch.int8, 10000 times 0.14827249851077795
device: cuda, dtype: torch.uint8, 10000 times 0.14801877550780773
device: cuda, dtype: torch.int16, 10000 times 0.14952312968671322
device: cuda, dtype: torch.int32, 10000 times 0.14999118447303772
device: cuda, dtype: torch.int64, 10000 times 0.14951884001493454
```
After:
```
__and__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.23157884553074837
device: cpu, dtype: torch.uint8, 100000 times 0.23063660878688097
device: cpu, dtype: torch.int16, 100000 times 0.23005440644919872
device: cpu, dtype: torch.int32, 100000 times 0.23748818412423134
device: cpu, dtype: torch.int64, 100000 times 0.24106105230748653
device: cuda, dtype: torch.int8, 100000 times 1.4394256137311459
device: cuda, dtype: torch.uint8, 100000 times 1.4436759827658534
device: cuda, dtype: torch.int16, 100000 times 1.4631587155163288
device: cuda, dtype: torch.int32, 100000 times 1.459101552143693
device: cuda, dtype: torch.int64, 100000 times 1.4784048134461045
__and__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.028442862443625927
device: cpu, dtype: torch.uint8, 10000 times 0.028130197897553444
device: cpu, dtype: torch.int16, 10000 times 0.025318274274468422
device: cpu, dtype: torch.int32, 10000 times 0.02519288007169962
device: cpu, dtype: torch.int64, 10000 times 0.028299466706812382
device: cuda, dtype: torch.int8, 10000 times 0.14342594426125288
device: cuda, dtype: torch.uint8, 10000 times 0.145280827768147
device: cuda, dtype: torch.int16, 10000 times 0.14673697855323553
device: cuda, dtype: torch.int32, 10000 times 0.14499565307050943
device: cuda, dtype: torch.int64, 10000 times 0.14582364354282618
__iand__ (a.numel() == 10) for 100000 times
device: cpu, dtype: torch.int8, 100000 times 0.25548241566866636
device: cpu, dtype: torch.uint8, 100000 times 0.2552562616765499
device: cpu, dtype: torch.int16, 100000 times 0.25905191246420145
device: cpu, dtype: torch.int32, 100000 times 0.26635489892214537
device: cpu, dtype: torch.int64, 100000 times 0.26269810926169157
device: cuda, dtype: torch.int8, 100000 times 1.485458506271243
device: cuda, dtype: torch.uint8, 100000 times 1.4742380809038877
device: cuda, dtype: torch.int16, 100000 times 1.507783885113895
device: cuda, dtype: torch.int32, 100000 times 1.4926990242674947
device: cuda, dtype: torch.int64, 100000 times 1.519851053133607
__iand__ (a.numel() == 1000) for 10000 times
device: cpu, dtype: torch.int8, 10000 times 0.03425929415971041
device: cpu, dtype: torch.uint8, 10000 times 0.03293587639927864
device: cpu, dtype: torch.int16, 10000 times 0.029559112153947353
device: cpu, dtype: torch.int32, 10000 times 0.030915481969714165
device: cpu, dtype: torch.int64, 10000 times 0.03292469773441553
device: cuda, dtype: torch.int8, 10000 times 0.15792148280888796
device: cuda, dtype: torch.uint8, 10000 times 0.16000914946198463
device: cuda, dtype: torch.int16, 10000 times 0.1600684942677617
device: cuda, dtype: torch.int32, 10000 times 0.16162546630948782
device: cuda, dtype: torch.int64, 10000 times 0.1629159888252616
```
Fix https://github.com/pytorch/pytorch/issues/24508 , https://github.com/pytorch/pytorch/issues/24509 , https://github.com/pytorch/pytorch/issues/24655 , https://github.com/pytorch/pytorch/issues/24656 .
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31104
Differential Revision: D18938930
Pulled By: VitalyFedyunin
fbshipit-source-id: a77e805a0b84e8ace16c6e648c2f67dad44f2e44
2020-01-03 10:32:36 -08:00
vishwakftw
22d84204f7
Expose torch.poisson in documentation ( #31667 )
...
Summary:
Changelog:
- Add doc string for torch.poisson briefing current behavior
- Check for non-positive entries in the tensor passed as input to torch.poisson
Closes https://github.com/pytorch/pytorch/issues/31646
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31667
Differential Revision: D19247371
Pulled By: ngimel
fbshipit-source-id: b53d105e73bf59a45beeb566f47365c3eb74efca
2019-12-28 21:32:26 -08:00
davidriazati
ec4e347744
Add Python language reference docs ( #30686 )
...
Summary:
This exposes our audit of https://docs.python.org/3/reference/ with descriptions for each line item.
To generate the `.rst` from the Quip:
```bash
pip install m2r
m2r jit_language_reference.md
```
https://driazati.github.io/pytorch_doc_previews/30686/jit.html#python-functions-and-modules
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30686
Pulled By: driazati
Differential Revision: D19219587
fbshipit-source-id: 249db9b5ee20e38804d4302bbfeca7d54f27d0bd
2019-12-26 13:21:36 -08:00
Martin Yuan
11854bcd38
Add test to torch.jit.export_opnames, make the _C function private
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/31446
Test Plan: Imported from OSS
Differential Revision: D19172851
Pulled By: iseeyuan
fbshipit-source-id: f06d8766ed73c9abe4ebf41c402ee64880d745be
2019-12-20 13:38:43 -08:00
Elias Ellison
779b128872
add back in reference to jit_unsupported section ( #31486 )
...
Summary:
It was added in https://github.com/pytorch/pytorch/pull/31329 and removed in a bad merge in https://github.com/pytorch/pytorch/pull/31138/
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31486
Differential Revision: D19181967
Pulled By: eellison
fbshipit-source-id: 7e4b4a9b2042c30ec18f7f737bc4a9a56fac7d92
2019-12-19 12:44:16 -08:00
davidriazati
503a4e9019
Cleanup after moving language reference ( #31146 )
...
Summary:
Stacked PRs
* **#31146 - [jit] Cleanup after moving language reference**
* #31138 - [jit] Move TorchScript language reference to its own page
Preview: https://driazati.github.io/pytorch_doc_previews/jit.html#torchscript-language
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31146
Pulled By: driazati
Differential Revision: D19167390
fbshipit-source-id: f28daed36754a553264fc8ac142ed22c3e26d63e
2019-12-18 15:09:35 -08:00
davidriazati
ae2487bf4d
Move TorchScript language reference to its own page ( #31138 )
...
Summary:
Stacked PRs
* #31146 - [jit] Cleanup after moving language reference
* **#31138 - [jit] Move TorchScript language reference to its own page**
Preview: https://driazati.github.io/pytorch_doc_previews/jit.html#torchscript-language
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31138
Pulled By: driazati
Differential Revision: D19167375
fbshipit-source-id: d37110d85fc8b8d2c741be49846e873de1357c2a
2019-12-18 15:09:31 -08:00
Elias Ellison
fb30a48b4e
add unsupported section ( #31329 )
...
Summary:
Add a section for unsupported ops, and modules. Automatically generate the properties and attributes that aren't bound, and for ops that have semantic mismatches set up tests so the docs stay up to date.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31329
Differential Revision: D19164472
Pulled By: eellison
fbshipit-source-id: 46290bb8a64d9de928cfb1eda5ff4558c3799c88
2019-12-18 13:56:02 -08:00
Elliot Waite
c63f8e5ebe
Fix typo in data.rst docs
...
Summary: Pull Request resolved: https://github.com/pytorch/pytorch/pull/31395
Differential Revision: D19160010
Pulled By: zou3519
fbshipit-source-id: cbc4e719e69117e8747617729d240c72e7a4e3dd
2019-12-18 09:52:10 -08:00
Vitaly Fedyunin
3e59e80429
Revert D18941024: Move TorchScript language reference to its own page
...
Test Plan: revert-hammer
Differential Revision:
D18941024
Original commit changeset: d0ff600870a1
fbshipit-source-id: 01c0eac4c9741f27b91d710616e71a0d769f6f6a
2019-12-18 08:55:50 -08:00
davidriazati
c05538b831
Move TorchScript language reference to its own page ( #31138 )
...
Summary:
Preview: https://driazati.github.io/pytorch_doc_previews/jit.html#torchscript-language
](https://our.intern.facebook.com/intern/diff/18941024/ )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31138
Pulled By: driazati
Differential Revision: D18941024
fbshipit-source-id: d0ff600870a14c4a7c6ce54867d152072a12c48c
2019-12-18 00:46:19 -08:00
Michael Suo
293a139d79
add a warning for script classes ( #31069 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31069
Just to clarify that they are still experimental.
Test Plan: Imported from OSS
Differential Revision: D18920496
Pulled By: suo
fbshipit-source-id: d2f3014592a01a21f7fc60a4ce46dd0bfe5e19e9
2019-12-11 14:48:55 -08:00
Rohan Varma
dbc8b00816
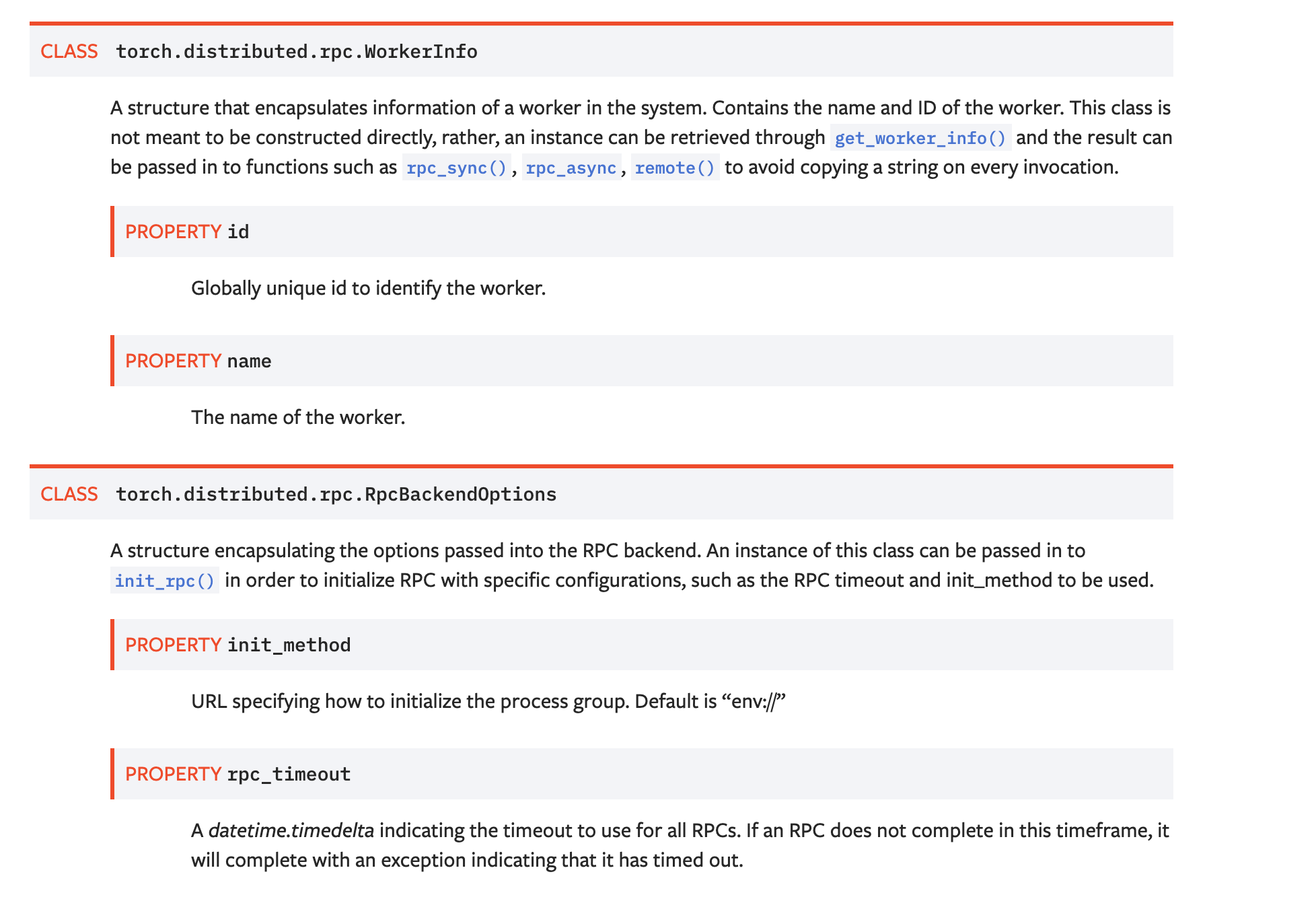
Document WorkerInfo and RpcBackendOptions structures in RPC docs. ( #31077 )
...
Summary:
We mention `WorkerInfo` and `RpcBackendOptions` in a couple of different locations in our docs, and these are public classes that the user may use, so we should add the class to the documentation.
<img width="978" alt="Screen Shot 2019-12-10 at 1 42 22 PM" src="https://user-images.githubusercontent.com/8039770/70571759-47db2080-1b53-11ea-9d61-c83985a29dd9.png ">
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31077
Differential Revision: D18928162
Pulled By: rohan-varma
fbshipit-source-id: 67f11eedd87523c469377b791a0ba23704ec3723
2019-12-11 11:39:57 -08:00
Michael Suo
d02280b432
move migration guide to appendix ( #31068 )
...
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/31068
Let's get it out of the early parts now that the recursive API has been
around for a while
Test Plan: Imported from OSS
Differential Revision: D18920498
Pulled By: suo
fbshipit-source-id: 6f4389739dd9e7e5f3014811b452249cc21d88e7
2019-12-10 18:04:02 -08:00
TH3CHARLie
5edfe9cb80
add torch.square ( #30719 )
...
Summary:
fixes https://github.com/pytorch/pytorch/issues/30524
This adds an new operator `torch.square` to PyTorch
I think it is ready for the first-time review now albanD
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30719
Differential Revision: D18909268
Pulled By: albanD
fbshipit-source-id: 5626c445d8db20471a56fc1d7a3490e77812662b
2019-12-10 15:22:46 -08:00
Elias Ellison
f48a8901c5
Add floor_divide function ( #30493 )
...
Summary:
Adds `torch.floor_divide` following the numpy's `floor_divide` api. I only implemented the out-of-place version, I can add the inplace version if requested.
Also fixes https://github.com/pytorch/pytorch/issues/27512
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30493
Differential Revision: D18896211
Pulled By: eellison
fbshipit-source-id: ee401c96ab23a62fc114ed3bb9791b8ec150ecbd
2019-12-10 07:51:39 -08:00
Joseph Spisak
7af9d77290
Update persons_of_interest.rst
...
Updating to add POI for mobile, quantization and an addition to optimizers.
2019-12-05 21:20:40 -08:00
davidriazati
2308a0ec1b
Improve documentation around builtin functions ( #30347 )
...
Summary:
This breaks the builtins page into some more sections and adds details about Python built-in functions
](https://our.intern.facebook.com/intern/diff/18718166/ )
Pull Request resolved: https://github.com/pytorch/pytorch/pull/30347
Pulled By: driazati
Reviewed By: wanchaol
Differential Revision: D18718166
fbshipit-source-id: bf43260ab7bcf92cccef684a5ce68cb16020771d
2019-12-04 13:50:40 -08:00
{kind=link}