Summary:
Something flaky is going on with `test_inplace_view_saved_output` on Windows.
With my PR #20598 applied, the test fails, even though there is no obvious reason it should be related, so the PR was reverted.
Based on commenting out various parts of my change and re-building, I think the problem is with the name -- renaming everything from `T` to `asdf` seems to make the test stop failing. I can't be sure that this is actually the case though, since I could just be seeing patterns in non-deterministic build output...
I spoke with colesbury offline and we agreed that it is okay to just disable this test on Windows for now and not block landing the main change. He will look into why it is failing.
**Test Plan:** I will wait to make sure the Windows CI suite passes before landing this.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21175
Differential Revision: D15566970
Pulled By: umanwizard
fbshipit-source-id: edf223375d41faaab0a3a14dca50841f08030da3
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20665
Add gelu activation forward on CPU in pytorch
Compare to current python implemented version of gelu in BERT model like
def gelu(self, x):
x * 0.5 * (1.0 + torch.erf(x / self.sqrt_two))
The torch.nn.functional.gelu function can reduce the forward time from 333ms to 109ms (with MKL) / 112ms (without MKL) for input size = [64, 128, 56, 56] on a devvm.
Reviewed By: zheng-xq
Differential Revision: D15400974
fbshipit-source-id: f606b43d1dd64e3c42a12c4991411d47551a8121
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21196
we'll add `quantize(quantizer)` as a tensor method later when we expose `quantizer` in Python frontend
Python
```
torch.quantize_linear(t, ...)
```
C++
```
at::quantize_linear(t, ...)
```
Differential Revision: D15577123
fbshipit-source-id: d0abeea488418fa9ab212f84b0b97ee237124240
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/21156
we'll add `quantize(quantizer)` as a tensor method later when we expose `quantizer` in Python frontend
Python
```
torch.quantize_linear(t, ...)
```
C++
```
at::quantize_linear(t, ...)
```
Differential Revision: D15558784
fbshipit-source-id: 0b194750c423f51ad1ad5e9387a12b4d58d969a9
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20874
A criteria for what should go in Tensor method is whether numpy has it, for this one it does not
so we are removing it as a Tensor method, we can still call it as function.
Python
```
torch.quantize_linear(t, ...), torch.dequantize(t)
```
C++
```
at::quantize_linear(t, ...), at::dequantize(t)
```
Reviewed By: dzhulgakov
Differential Revision: D15477933
fbshipit-source-id: c8aa81f681e02f038d72e44f0c700632f1af8437
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20938
Dequantize_linear need not be exposed to the front end users.
It will only be used for the jit passes for q-dq insertion and op
substitution.
Differential Revision: D15446097
fbshipit-source-id: a5fbcf2bb72115122c9653e5089d014e2a2e891d
Summary:
I started adding support for the new **[mesh/point cloud](https://github.com/tensorflow/graphics/blob/master/tensorflow_graphics/g3doc/tensorboard.md)** data type introduced to TensorBoard recently.
I created the functions to add the data, created the appropriate summaries.
This new data type however requires a **Merged** summary containing the data for the vertices, colors and faces.
I got stuck at this stage. Maybe someone can help. lanpa?
I converted the example code by Google to PyTorch:
```python
import numpy as np
import trimesh
import torch
from torch.utils.tensorboard import SummaryWriter
sample_mesh = 'https://storage.googleapis.com/tensorflow-graphics/tensorboard/test_data/ShortDance07_a175_00001.ply'
log_dir = 'runs/torch'
batch_size = 1
# Camera and scene configuration.
config_dict = {
'camera': {'cls': 'PerspectiveCamera', 'fov': 75},
'lights': [
{
'cls': 'AmbientLight',
'color': '#ffffff',
'intensity': 0.75,
}, {
'cls': 'DirectionalLight',
'color': '#ffffff',
'intensity': 0.75,
'position': [0, -1, 2],
}],
'material': {
'cls': 'MeshStandardMaterial',
'roughness': 1,
'metalness': 0
}
}
# Read all sample PLY files.
mesh = trimesh.load_remote(sample_mesh)
vertices = np.array(mesh.vertices)
# Currently only supports RGB colors.
colors = np.array(mesh.visual.vertex_colors[:, :3])
faces = np.array(mesh.faces)
# Add batch dimension, so our data will be of shape BxNxC.
vertices = np.expand_dims(vertices, 0)
colors = np.expand_dims(colors, 0)
faces = np.expand_dims(faces, 0)
# Create data placeholders of the same shape as data itself.
vertices_tensor = torch.as_tensor(vertices)
faces_tensor = torch.as_tensor(faces)
colors_tensor = torch.as_tensor(colors)
writer = SummaryWriter(log_dir)
writer.add_mesh('mesh_color_tensor', vertices=vertices_tensor, faces=faces_tensor,
colors=colors_tensor, config_dict=config_dict)
writer.close()
```
I tried adding only the vertex summary, hence the others are supposed to be optional.
I got the following error from TensorBoard and it also didn't display the points:
```
Traceback (most recent call last):
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/werkzeug/serving.py", line 302, in run_wsgi
execute(self.server.app)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/werkzeug/serving.py", line 290, in execute
application_iter = app(environ, start_response)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/backend/application.py", line 309, in __call__
return self.data_applications[clean_path](environ, start_response)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/werkzeug/wrappers/base_request.py", line 235, in application
resp = f(*args[:-2] + (request,))
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/plugins/mesh/mesh_plugin.py", line 252, in _serve_mesh_metadata
tensor_events = self._collect_tensor_events(request)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/plugins/mesh/mesh_plugin.py", line 188, in _collect_tensor_events
tensors = self._multiplexer.Tensors(run, instance_tag)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/backend/event_processing/plugin_event_multiplexer.py", line 400, in Tensors
return accumulator.Tensors(tag)
File "/home/dawars/workspace/pytorch/venv/lib/python3.6/site-packages/tensorboard/backend/event_processing/plugin_event_accumulator.py", line 437, in Tensors
return self.tensors_by_tag[tag].Items(_TENSOR_RESERVOIR_KEY)
KeyError: 'mesh_color_tensor_COLOR'
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20413
Differential Revision: D15500737
Pulled By: orionr
fbshipit-source-id: 426e8b966037d08c065bce5198fd485fd80a2b67
Summary:
To say that we don't do refinement on module attributes
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20912
Differential Revision: D15496453
Pulled By: eellison
fbshipit-source-id: a1ab9fb0157a30fa1bb71d0793fcc9b1670c4926
Summary:
The current variance kernels compute mean at the same time. Many times we want both statistics together, so it seems reasonable to have a kwarg/function that allows us to get both values without launching an extra kernel.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18731
Differential Revision: D14726082
Pulled By: ifedan
fbshipit-source-id: 473cba0227b69eb2240dca5e61a8f4366df0e029
Summary:
As a part of supporting writing data into TensorBoard readable format, we show more example on how to use the function in addition to the API docs.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/20008
Reviewed By: natalialunova
Differential Revision: D15261502
Pulled By: orionr
fbshipit-source-id: 16611695a27e74bfcdf311e7cad40196e0947038
Summary:
This adds method details and corrects example on the page that didn't run properly. I've now confirmed that it runs in colab with nightly.
For those with internal access the rendered result can be seen at https://home.fburl.com/~orionr/pytorch-docs/tensorboard.html
cc lanpa, soumith, ezyang, brianjo
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19915
Differential Revision: D15137430
Pulled By: orionr
fbshipit-source-id: 833368fb90f9d75231b8243b43de594b475b2cb1
Summary:
This PR adds TensorBoard logging support natively within PyTorch. It is based on the tensorboardX code developed by lanpa and relies on changes inside the tensorflow/tensorboard repo landing at https://github.com/tensorflow/tensorboard/pull/2065.
With these changes users can simply `pip install tensorboard; pip install torch` and then log PyTorch data directly to the TensorBoard protobuf format using
```
import torch
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
s1 = torch.rand(1)
writer.add_scalar('data/scalar1', s1[0], 0)
writer.close()
```
Design:
- `EventFileWriter` and `RecordWriter` from tensorboardX now live in tensorflow/tensorboard
- `SummaryWriter` and PyTorch-specific conversion from tensors, nn modules, etc. now live in pytorch/pytorch. We also support Caffe2 blobs and nets.
Action items:
- [x] `from torch.utils.tensorboard import SummaryWriter`
- [x] rename functions
- [x] unittests
- [x] move actual writing function to tensorflow/tensorboard in https://github.com/tensorflow/tensorboard/pull/2065
Review:
- Please review for PyTorch standard formatting, code usage, etc.
- Please verify unittest usage is correct and executing in CI
Any significant changes made here will likely be synced back to github.com/lanpa/tensorboardX/ in the future.
cc orionr, ezyang
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16196
Differential Revision: D15062901
Pulled By: orionr
fbshipit-source-id: 3812eb6aa07a2811979c5c7b70810261f9ea169e
Summary:
Changelog:
- Rename `potri` to `cholesky_inverse` to remain consistent with names of `cholesky` methods (`cholesky`, `cholesky_solve`)
- Fix all callsites
- Rename all tests
- Create a tentative alias for `cholesky_inverse` under the name `potri` and add a deprecation warning to not promote usage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19498
Differential Revision: D15029901
Pulled By: ezyang
fbshipit-source-id: 2074286dc93d8744cdc9a45d54644fe57df3a57a
Summary:
This is a simple yet useful addition to the torch.nn modules: an identity module. This is a first draft - please let me know what you think and I will edit my PR.
There is no identity module - nn.Sequential() can be used, however it is argument sensitive so can't be used interchangably with any other module. This adds nn.Identity(...) which can be swapped with any module because it has dummy arguments. It's also more understandable than seeing an empty Sequential inside a model.
See discussion on #9160. The current solution is to use nn.Sequential(). However this won't work as follows:
```python
batch_norm = nn.BatchNorm2d
if dont_use_batch_norm:
batch_norm = Identity
```
Then in your network, you have:
```python
nn.Sequential(
...
batch_norm(N, momentum=0.05),
...
)
```
If you try to simply set `Identity = nn.Sequential`, this will fail since `nn.Sequential` expects modules as arguments. Of course there are many ways to get around this, including:
- Conditionally adding modules to an existing Sequential module
- Not using Sequential but writing the usual `forward` function with an if statement
- ...
**However, I think that an identity module is the most pythonic strategy,** assuming you want to use nn.Sequential.
Using the very simple class (this isn't the same as the one in my commit):
```python
class Identity(nn.Module):
def __init__(self, *args, **kwargs):
super().__init__()
def forward(self, x):
return x
```
we can get around using nn.Sequential, and `batch_norm(N, momentum=0.05)` will work. There are of course other situations this would be useful.
Thank you.
Best,
Miles
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19249
Differential Revision: D15012969
Pulled By: ezyang
fbshipit-source-id: 9f47e252137a1679e306fd4c169dca832eb82c0c
Summary:
A few improvements while doing bert model
Pull Request resolved: https://github.com/pytorch/pytorch/pull/19247
Differential Revision: D14989345
Pulled By: ailzhang
fbshipit-source-id: f4846813f62b6d497fbe74e8552c9714bd8dc3c7
Summary:
* `torch.hub.list('pytorch/vision')` - show all available hub models in `pytorch/vision`
* `torch.hub.show('pytorch/vision', 'resnet18')` - show docstring & example for `resnet18` in `pytorch/vision`
* Moved `torch.utils.model_zoo.load_url` to `torch.hub.load_state_dict_from_url` and deprecate `torch.utils.model_zoo`
* We have too many env to control where the cache dir is, it's not very necessary. I actually want to unify `TORCH_HUB_DIR`, `TORCH_HOME` and `TORCH_MODEL_ZOO`, but haven't done it. (more suggestions are welcome!)
* Simplify `pytorch/vision` example in doc, it was used to show how how hub entrypoint can be written so had some confusing unnecessary args.
An example of hub usage is shown below
```
In [1]: import torch
In [2]: torch.hub.list('pytorch/vision', force_reload=True)
Downloading: "https://github.com/pytorch/vision/archive/master.zip" to /private/home/ailzhang/.torch/hub/master.zip
Out[2]: ['resnet18', 'resnet50']
In [3]: torch.hub.show('pytorch/vision', 'resnet18')
Using cache found in /private/home/ailzhang/.torch/hub/vision_master
Resnet18 model
pretrained (bool): a recommended kwargs for all entrypoints
args & kwargs are arguments for the function
In [4]: model = torch.hub.load('pytorch/vision', 'resnet18', pretrained=True)
Using cache found in /private/home/ailzhang/.torch/hub/vision_master
```
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18758
Differential Revision: D14883651
Pulled By: ailzhang
fbshipit-source-id: 6db6ab708a74121782a9154c44b0e190b23e8309
Summary:
Changelog:
- Rename `btrisolve` to `lu_solve` to remain consistent with names of solve methods (`cholesky_solve`, `triangular_solve`, `solve`)
- Fix all callsites
- Rename all tests
- Create a tentative alias for `lu_solve` under the name `btrisolve` and add a deprecation warning to not promote usage
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18726
Differential Revision: D14726237
Pulled By: zou3519
fbshipit-source-id: bf25f6c79062183a4153015e0ec7ebab2c8b986b
Summary:
This is a minimalist PR to add MKL-DNN tensor per discussion from Github issue: https://github.com/pytorch/pytorch/issues/16038
Ops with MKL-DNN tensor will be supported in following-up PRs to speed up imperative path.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17748
Reviewed By: dzhulgakov
Differential Revision: D14614640
Pulled By: bddppq
fbshipit-source-id: c58de98e244b0c63ae11e10d752a8e8ed920c533
Summary:
Per our offline discussion, allow Tensors, ints, and floats to be casted to be bool when used in a conditional
Fix for https://github.com/pytorch/pytorch/issues/18381
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18755
Reviewed By: driazati
Differential Revision: D14752476
Pulled By: eellison
fbshipit-source-id: 149960c92afcf7e4cc4997bccc57f4e911118ff1
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18230
Implementing minimum qtensor API to unblock other workstreams in quantization
Changes:
- Added Quantizer which represents different quantization schemes
- Added qint8 as a data type for QTensor
- Added a new ScalarType QInt8
- Added QTensorImpl for QTensor
- Added following user facing APIs
- quantize_linear(scale, zero_point)
- dequantize()
- q_scale()
- q_zero_point()
Reviewed By: dzhulgakov
Differential Revision: D14524641
fbshipit-source-id: c1c0ae0978fb500d47cdb23fb15b747773429e6c
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18628
ghimport-source-id: d94b81a6f303883d97beaae25344fd591e13ce52
Stack from [ghstack](https://github.com/ezyang/ghstack):
* #18629 Provide flake8 install instructions.
* **#18628 Delete duplicated technical content from contribution_guide.rst**
There's useful guide in contributing_guide.rst, but the
technical bits were straight up copy-pasted from CONTRIBUTING.md,
and I don't think it makes sense to break the CONTRIBUTING.md
link. Instead, I deleted the duplicate bits and added a cross
reference to the rst document.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14701003
fbshipit-source-id: 3bbb102fae225cbda27628a59138bba769bfa288
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18598
ghimport-source-id: c74597e5e7437e94a43c163cee0639b20d0d0c6a
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18598 Turn on F401: Unused import warning.**
This was requested by someone at Facebook; this lint is turned
on for Facebook by default. "Sure, why not."
I had to noqa a number of imports in __init__. Hypothetically
we're supposed to use __all__ in this case, but I was too lazy
to fix it. Left for future work.
Be careful! flake8-2 and flake8-3 behave differently with
respect to import resolution for # type: comments. flake8-3 will
report an import unused; flake8-2 will not. For now, I just
noqa'd all these sites.
All the changes were done by hand.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14687478
fbshipit-source-id: 30d532381e914091aadfa0d2a5a89404819663e3
Summary:
Changelog:
- Renames `btriunpack` to `lu_unpack` to remain consistent with the `lu` function interface.
- Rename all relevant tests, fix callsites
- Create a tentative alias for `lu_unpack` under the name `btriunpack` and add a deprecation warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18529
Differential Revision: D14683161
Pulled By: soumith
fbshipit-source-id: 994287eaa15c50fd74c2f1c7646edfc61e8099b1
Summary:
Changelog:
- Renames `btrifact` and `btrifact_with_info` to `lu`to remain consistent with other factorization methods (`qr` and `svd`).
- Now, we will only have one function and methods named `lu`, which performs `lu` decomposition. This function takes a get_infos kwarg, which when set to True includes a infos tensor in the tuple.
- Rename all tests, fix callsites
- Create a tentative alias for `lu` under the name `btrifact` and `btrifact_with_info`, and add a deprecation warning to not promote usage.
- Add the single batch version for `lu` so that users don't have to unsqueeze and squeeze for a single square matrix (see changes in determinant computation in `LinearAlgebra.cpp`)
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18435
Differential Revision: D14680352
Pulled By: soumith
fbshipit-source-id: af58dfc11fa53d9e8e0318c720beaf5502978cd8
Summary:
This implements a cyclical learning rate (CLR) schedule with an optional inverse cyclical momentum. More info about CLR: https://github.com/bckenstler/CLR
This is finishing what #2016 started. Resolves#1909.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18001
Differential Revision: D14451845
Pulled By: sampepose
fbshipit-source-id: 8f682e0c3dee3a73bd2b14cc93fcf5f0e836b8c9
Summary:
There are a number of pages in the docs that serve insecure content. AFAICT this is the sole source of that.
I wasn't sure if docs get regenerated for old versions as part of the automation, or if those would need to be manually done.
cf. https://github.com/pytorch/pytorch.github.io/pull/177
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18508
Differential Revision: D14645665
Pulled By: zpao
fbshipit-source-id: 003563b06048485d4f539feb1675fc80bab47c1b
Summary:
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18507
ghimport-source-id: 1c3642befad2da78a7e5f39d6d58732b85c76267
Stack from [ghstack](https://github.com/ezyang/ghstack):
* **#18507 Upgrade flake8-bugbear to master, fix the new lints.**
It turns out Facebobok is internally using the unreleased master
flake8-bugbear, so upgrading it grabs a few more lints that Phabricator
was complaining about but we didn't get in open source.
A few of the getattr sites that I fixed look very suspicious (they're
written as if Python were a lazy language), but I didn't look more
closely into the matter.
Signed-off-by: Edward Z. Yang <ezyang@fb.com>
Differential Revision: D14633682
fbshipit-source-id: fc3f97c87dca40bbda943a1d1061953490dbacf8
Summary:
This depend on https://github.com/pytorch/pytorch/pull/16039
This prevent people (reviewer, PR author) from forgetting adding things to `tensors.rst`.
When something new is added to `_tensor_doc.py` or `tensor.py` but intentionally not in `tensors.rst`, people should manually whitelist it in `test_docs_coverage.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16057
Differential Revision: D14619550
Pulled By: ezyang
fbshipit-source-id: e1c6dd6761142e2e48ec499e118df399e3949fcc
Summary:
This PR adds a Global Site Tag to the site.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17690
Differential Revision: D14620816
Pulled By: zou3519
fbshipit-source-id: c02407881ce08340289123f5508f92381744e8e3
Summary:
`SobolEngine` is a quasi-random sampler used to sample points evenly between [0,1]. Here we use direction numbers to generate these samples. The maximum supported dimension for the sampler is 1111.
Documentation has been added, tests have been added based on Balandat 's references. The implementation is an optimized / tensor-ized implementation of Balandat 's implementation in Cython as provided in #9332.
This closes#9332 .
cc: soumith Balandat
Pull Request resolved: https://github.com/pytorch/pytorch/pull/10505
Reviewed By: zou3519
Differential Revision: D9330179
Pulled By: ezyang
fbshipit-source-id: 01d5588e765b33b06febe99348f14d1e7fe8e55d
Summary:
This is to fix#16141 and similar issues.
The idea is to track a reference to every shared CUDA Storage and deallocate memory only after a consumer process deallocates received Storage.
ezyang Done with cleanup. Same (insignificantly better) performance as in file-per-share solution, but handles millions of shared tensors easily. Note [ ] documentation in progress.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16854
Differential Revision: D13994490
Pulled By: VitalyFedyunin
fbshipit-source-id: 565148ec3ac4fafb32d37fde0486b325bed6fbd1
Summary:
* Adds more headers for easier scanning
* Adds some line breaks so things are displayed correctly
* Minor copy/spelling stuff
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18234
Reviewed By: ezyang
Differential Revision: D14567737
Pulled By: driazati
fbshipit-source-id: 046d991f7aab8e00e9887edb745968cb79a29441
Summary:
Changelog:
- Renames `trtrs` to `triangular_solve` to remain consistent with `cholesky_solve` and `solve`.
- Rename all tests, fix callsites
- Create a tentative alias for `triangular_solve` under the name `trtrs`, and add a deprecation warning to not promote usage.
- Move `isnan` to _torch_docs.py
- Remove unnecessary imports
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18213
Differential Revision: D14566902
Pulled By: ezyang
fbshipit-source-id: 544f57c29477df391bacd5de700bed1add456d3f
Summary:
Fixes Typo and a Link in the `docs/source/community/contribution_guide.rst`
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18237
Differential Revision: D14566907
Pulled By: ezyang
fbshipit-source-id: 3a75797ab6b27d28dd5566d9b189d80395024eaf
Summary:
Changelog:
- Renames `gesv` to `solve` to remain consistent with `cholesky_solve`.
- Rename all tests, fix callsites
- Create a tentative alias for `solve` under the name `gesv`, and add a deprecated warning to not promote usage.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/18060
Differential Revision: D14503117
Pulled By: zou3519
fbshipit-source-id: 99c16d94e5970a19d7584b5915f051c030d49ff5
Summary:
Fix a very common typo in my name.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17949
Differential Revision: D14475162
Pulled By: ezyang
fbshipit-source-id: 91c2c364c56ecbbda0bd530e806a821107881480
Summary: Adding new documents to the PyTorch website to describe how PyTorch is governed, how to contribute to the project, and lists persons of interest.
Reviewed By: orionr
Differential Revision: D14394573
fbshipit-source-id: ad98b807850c51de0b741e3acbbc3c699e97b27f
Summary:
as title
Pull Request resolved: https://github.com/pytorch/pytorch/pull/17476
Differential Revision: D14218312
Pulled By: suo
fbshipit-source-id: 64df096a3431a6f25cd2373f0959d415591fed15
Summary:
Based on https://github.com/pytorch/pytorch/pull/12413, with the following additional changes:
- Inside `native_functions.yml` move those outplace operators right next to everyone's corresponding inplace operators for convenience of checking if they match when reviewing
- `matches_jit_signature: True` for them
- Add missing `scatter` with Scalar source
- Add missing `masked_fill` and `index_fill` with Tensor source.
- Add missing test for `scatter` with Scalar source
- Add missing test for `masked_fill` and `index_fill` with Tensor source by checking the gradient w.r.t source
- Add missing docs to `tensor.rst`
Differential Revision: D14069925
Pulled By: ezyang
fbshipit-source-id: bb3f0cb51cf6b756788dc4955667fead6e8796e5
Summary:
one_hot docs is missing [here](https://pytorch.org/docs/master/nn.html#one-hot).
I dug around and could not find a way to get this working properly.
Differential Revision: D14104414
Pulled By: zou3519
fbshipit-source-id: 3f45c8a0878409d218da167f13b253772f5cc963
Summary:
This prevent people (reviewer, PR author) from forgetting adding things to `torch.rst`.
When something new is added to `_torch_doc.py` or `functional.py` but intentionally not in `torch.rst`, people should manually whitelist it in `test_docs_coverage.py`.
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16039
Differential Revision: D14070903
Pulled By: ezyang
fbshipit-source-id: 60f2a42eb5efe81be073ed64e54525d143eb643e
Summary:
This PR is a simple fix for the mistake in the first note for `torch.device` in the "tensor attributes" doc.

```
>>> # You can substitute the torch.device with a string
>>> torch.randn((2,3), 'cuda:1')
```
Above code will cause error like below:
```
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
<ipython-input-53-abdfafb67ab1> in <module>()
----> 1 torch.randn((2,3), 'cuda:1')
TypeError: randn() received an invalid combination of arguments - got (tuple, str), but expected one of:
* (tuple of ints size, torch.Generator generator, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
* (tuple of ints size, Tensor out, torch.dtype dtype, torch.layout layout, torch.device device, bool requires_grad)
```
Simply adding the argument name `device` solves the problem: `torch.randn((2,3), device='cuda:1')`.
However, another concern is that this note seems redundant as **there is already another note covering this usage**:
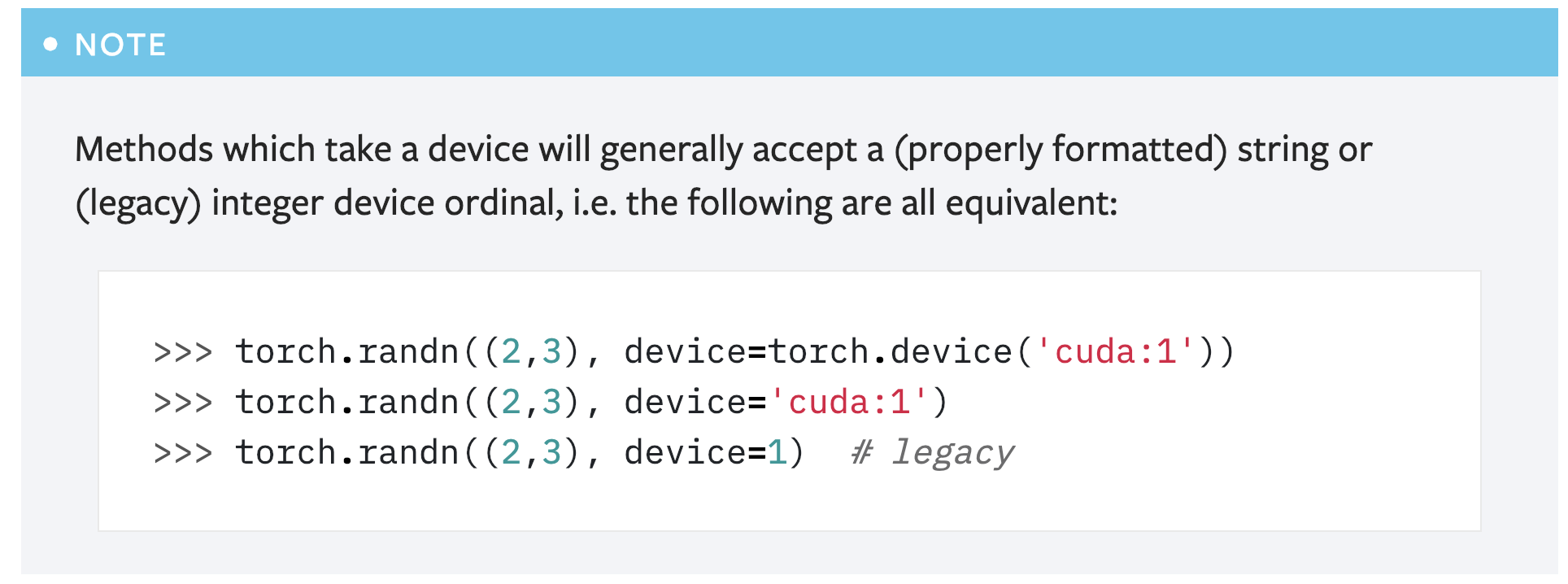
So maybe it's better to just remove this note?
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16839
Reviewed By: ezyang
Differential Revision: D13989209
Pulled By: gchanan
fbshipit-source-id: ac255d52528da053ebfed18125ee6b857865ccaf
Summary:
Some batched updates:
1. bool is a type now
2. Early returns are allowed now
3. The beginning of an FAQ section with some guidance on the best way to do GPU training + CPU inference
Pull Request resolved: https://github.com/pytorch/pytorch/pull/16866
Differential Revision: D13996729
Pulled By: suo
fbshipit-source-id: 3b884fd3a4c9632c9697d8f1a5a0e768fc918916
{kind=link}
{kind=link}
{kind=link}