mirror of
https://github.com/zebrajr/pytorch.git
synced 2025-12-06 12:20:52 +01:00
[Composable API] Add fully_shard debug function to print sharded tree structure, module names and managed param fqns (#99133)
Adding a fully_shard debug function to print sharded tree structure like following format, return module names and their managed parameter fqns as well. 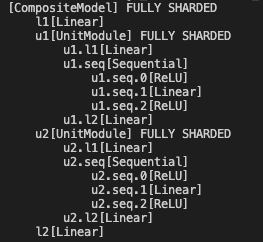 Pull Request resolved: https://github.com/pytorch/pytorch/pull/99133 Approved by: https://github.com/rohan-varma
{kind=link}
This commit is contained in:
parent
6b6dc4418d
commit
6ca991cacf
|
|
@ -0,0 +1,115 @@
|
||||||
|
# Owner(s): ["oncall: distributed"]
|
||||||
|
|
||||||
|
import sys
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.distributed as dist
|
||||||
|
from torch.distributed._composable import fully_shard
|
||||||
|
from torch.distributed.fsdp._debug_utils import (
|
||||||
|
_get_sharded_module_tree_with_module_name_to_fqns,
|
||||||
|
)
|
||||||
|
from torch.distributed.fsdp.wrap import ModuleWrapPolicy
|
||||||
|
from torch.testing._internal.common_dist_composable import CompositeModel, UnitModule
|
||||||
|
from torch.testing._internal.common_distributed import skip_if_lt_x_gpu
|
||||||
|
from torch.testing._internal.common_fsdp import FSDPTest
|
||||||
|
from torch.testing._internal.common_utils import run_tests, TEST_WITH_DEV_DBG_ASAN
|
||||||
|
|
||||||
|
if not dist.is_available():
|
||||||
|
print("Distributed not available, skipping tests", file=sys.stderr)
|
||||||
|
sys.exit(0)
|
||||||
|
|
||||||
|
if TEST_WITH_DEV_DBG_ASAN:
|
||||||
|
print(
|
||||||
|
"Skip dev-asan as torch + multiprocessing spawn have known issues",
|
||||||
|
file=sys.stderr,
|
||||||
|
)
|
||||||
|
sys.exit(0)
|
||||||
|
|
||||||
|
|
||||||
|
class TestUtils(FSDPTest):
|
||||||
|
@property
|
||||||
|
def world_size(self):
|
||||||
|
return 2
|
||||||
|
|
||||||
|
@property
|
||||||
|
def process_group(self):
|
||||||
|
return dist.distributed_c10d._get_default_group()
|
||||||
|
|
||||||
|
@skip_if_lt_x_gpu(2)
|
||||||
|
def test_get_sharded_module_tree_with_module_name_to_fqns(self):
|
||||||
|
model = CompositeModel(torch.device("cuda"))
|
||||||
|
fully_shard(
|
||||||
|
model,
|
||||||
|
policy=ModuleWrapPolicy({UnitModule}),
|
||||||
|
)
|
||||||
|
(
|
||||||
|
sharded_tree_info,
|
||||||
|
sharded_module_name_to_fqns,
|
||||||
|
) = _get_sharded_module_tree_with_module_name_to_fqns(model)
|
||||||
|
self.assertEqual(
|
||||||
|
list(sharded_module_name_to_fqns.keys()),
|
||||||
|
["[CompositeModel]", "u1[UnitModule]", "u2[UnitModule]"],
|
||||||
|
)
|
||||||
|
self.assertEqual(
|
||||||
|
list(sharded_module_name_to_fqns.values()),
|
||||||
|
[
|
||||||
|
["l1.weight", "l1.bias", "l2.weight", "l2.bias"],
|
||||||
|
[
|
||||||
|
"u1.l1.weight",
|
||||||
|
"u1.l1.bias",
|
||||||
|
"u1.seq.1.weight",
|
||||||
|
"u1.seq.1.bias",
|
||||||
|
"u1.l2.weight",
|
||||||
|
"u1.l2.bias",
|
||||||
|
],
|
||||||
|
[
|
||||||
|
"u2.l1.weight",
|
||||||
|
"u2.l1.bias",
|
||||||
|
"u2.seq.1.weight",
|
||||||
|
"u2.seq.1.bias",
|
||||||
|
"u2.l2.weight",
|
||||||
|
"u2.l2.bias",
|
||||||
|
],
|
||||||
|
],
|
||||||
|
)
|
||||||
|
# Test nested fully_shard
|
||||||
|
new_model = CompositeModel(torch.device("cuda"))
|
||||||
|
fully_shard(new_model.u1)
|
||||||
|
fully_shard(new_model)
|
||||||
|
(
|
||||||
|
sharded_tree_info,
|
||||||
|
sharded_module_name_to_fqns,
|
||||||
|
) = _get_sharded_module_tree_with_module_name_to_fqns(new_model)
|
||||||
|
self.assertEqual(
|
||||||
|
list(sharded_module_name_to_fqns.keys()),
|
||||||
|
["[CompositeModel]", "u1[UnitModule]"],
|
||||||
|
)
|
||||||
|
self.assertEqual(
|
||||||
|
list(sharded_module_name_to_fqns.values()),
|
||||||
|
[
|
||||||
|
[
|
||||||
|
"l1.weight",
|
||||||
|
"l1.bias",
|
||||||
|
"u2.l1.weight",
|
||||||
|
"u2.l1.bias",
|
||||||
|
"u2.seq.1.weight",
|
||||||
|
"u2.seq.1.bias",
|
||||||
|
"u2.l2.weight",
|
||||||
|
"u2.l2.bias",
|
||||||
|
"l2.weight",
|
||||||
|
"l2.bias",
|
||||||
|
],
|
||||||
|
[
|
||||||
|
"u1.l1.weight",
|
||||||
|
"u1.l1.bias",
|
||||||
|
"u1.seq.1.weight",
|
||||||
|
"u1.seq.1.bias",
|
||||||
|
"u1.l2.weight",
|
||||||
|
"u1.l2.bias",
|
||||||
|
],
|
||||||
|
],
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
if __name__ == "__main__":
|
||||||
|
run_tests()
|
||||||
|
|
@ -58,7 +58,7 @@ class _FSDPState(_State):
|
||||||
self._is_root: Optional[bool] = None
|
self._is_root: Optional[bool] = None
|
||||||
self._handles: List[flat_param_file.FlatParamHandle] = []
|
self._handles: List[flat_param_file.FlatParamHandle] = []
|
||||||
self._fully_sharded_module_to_handles: Dict[
|
self._fully_sharded_module_to_handles: Dict[
|
||||||
nn.Module, flat_param_file.FlatParamHandle
|
nn.Module, List[flat_param_file.FlatParamHandle]
|
||||||
] = {}
|
] = {}
|
||||||
self.compute_device: Optional[torch.device] = None
|
self.compute_device: Optional[torch.device] = None
|
||||||
# All following attributes should only be used for root states:
|
# All following attributes should only be used for root states:
|
||||||
|
|
@ -204,7 +204,7 @@ def _get_param_to_fqns(
|
||||||
includes the FQNs across all encounters. (Default: ``True``)
|
includes the FQNs across all encounters. (Default: ``True``)
|
||||||
"""
|
"""
|
||||||
|
|
||||||
def module_fn(module, prefix, param_to_fqns):
|
def module_fn(module, prefix, tree_level, param_to_fqns):
|
||||||
for param_name, param in module.named_parameters(recurse=False):
|
for param_name, param in module.named_parameters(recurse=False):
|
||||||
local_fqns = (
|
local_fqns = (
|
||||||
param._fqns
|
param._fqns
|
||||||
|
|
@ -272,13 +272,14 @@ def _apply_to_modules(
|
||||||
to remove the prefix.
|
to remove the prefix.
|
||||||
"""
|
"""
|
||||||
|
|
||||||
def f(module: torch.nn.Module, prefix: str, *args, **kwargs):
|
def f(module: torch.nn.Module, prefix: str, tree_level: int, *args, **kwargs):
|
||||||
# Call the module function before recursing over children (pre-order)
|
# Call the module function before recursing over children (pre-order)
|
||||||
module_fn(module, prefix, *args, **kwargs)
|
module_fn(module, prefix, tree_level, *args, **kwargs)
|
||||||
for submodule_name, submodule in module.named_children():
|
for submodule_name, submodule in module.named_children():
|
||||||
if submodule is None:
|
if submodule is None:
|
||||||
continue
|
continue
|
||||||
new_prefix = prefix + submodule_name + "."
|
new_prefix = prefix + submodule_name + "."
|
||||||
|
new_tree_level = tree_level + 1
|
||||||
if filter_fqns is not None:
|
if filter_fqns is not None:
|
||||||
for fqn in filter_fqns:
|
for fqn in filter_fqns:
|
||||||
if fqn.startswith(new_prefix):
|
if fqn.startswith(new_prefix):
|
||||||
|
|
@ -308,9 +309,9 @@ def _apply_to_modules(
|
||||||
f"submodule_name = {submodule_name}"
|
f"submodule_name = {submodule_name}"
|
||||||
)
|
)
|
||||||
new_prefix = prefix
|
new_prefix = prefix
|
||||||
f(submodule, new_prefix, *args, **kwargs)
|
f(submodule, new_prefix, new_tree_level, *args, **kwargs)
|
||||||
|
|
||||||
f(root_module, "", *args, **kwargs)
|
f(root_module, "", 0, *args, **kwargs)
|
||||||
return return_fn(*args, **kwargs)
|
return return_fn(*args, **kwargs)
|
||||||
|
|
||||||
|
|
||||||
|
|
|
||||||
103
torch/distributed/fsdp/_debug_utils.py
Normal file
103
torch/distributed/fsdp/_debug_utils.py
Normal file
|
|
@ -0,0 +1,103 @@
|
||||||
|
from typing import Dict, List, Tuple
|
||||||
|
|
||||||
|
import torch
|
||||||
|
import torch.distributed.fsdp.flat_param as flat_param_file
|
||||||
|
from torch.distributed.fsdp._common_utils import (
|
||||||
|
_apply_to_modules,
|
||||||
|
_get_module_fsdp_state,
|
||||||
|
clean_tensor_name,
|
||||||
|
)
|
||||||
|
|
||||||
|
|
||||||
|
def _get_sharded_module_tree_with_module_name_to_fqns(
|
||||||
|
model: torch.nn.Module,
|
||||||
|
) -> Tuple[str, Dict[str, List[str]]]:
|
||||||
|
"""
|
||||||
|
It is used for composable fully_shard() code path, it returns
|
||||||
|
1. sharded module tree info: each line reprents a submodule name that contats the
|
||||||
|
submodule's FQN and its submodule class name, if the submodule is sharded by `fully_shard`,
|
||||||
|
the submodule name will add a postfix with ' FULLY SHARDED'. Each increased tree
|
||||||
|
level adds 4 spaces before the printed name. A printed sharded module tree info for a toy model
|
||||||
|
is like this:
|
||||||
|
[CompositeModel] FULLY SHARDED
|
||||||
|
l1[Linear]
|
||||||
|
u1[UnitModule] FULLY SHARDED
|
||||||
|
u1.l1[Linear]
|
||||||
|
u1.seq[Sequential]
|
||||||
|
u1.seq.0[ReLU]
|
||||||
|
u1.seq.1[Linear]
|
||||||
|
u1.seq.2[ReLU]
|
||||||
|
u1.l2[Linear]
|
||||||
|
u2[UnitModule] FULLY SHARDED
|
||||||
|
u2.l1[Linear]
|
||||||
|
u2.seq[Sequential]
|
||||||
|
u2.seq.0[ReLU]
|
||||||
|
u2.seq.1[Linear]
|
||||||
|
u2.seq.2[ReLU]
|
||||||
|
u2.l2[Linear]
|
||||||
|
l2[Linear]
|
||||||
|
2. a dict mapping from the concated module FQN and class name to a list of its managed
|
||||||
|
original parameters' FQNs. An example of the dict for the above toy sharded model is like this:
|
||||||
|
{'[CompositeModel]': ['l1.weight', 'l1.bias', 'l2.weight', 'l2.bias'],
|
||||||
|
'u1[UnitModule]': ['u1.l1.weight', 'u1.l1.bias', 'u1.seq.1.weight', 'u1.seq.1.bias', 'u1.l2.weight', 'u1.l2.bias'],
|
||||||
|
'u2[UnitModule]': ['u2.l1.weight', 'u2.l1.bias', 'u2.seq.1.weight', 'u2.seq.1.bias', 'u2.l2.weight', 'u2.l2.bias']
|
||||||
|
}
|
||||||
|
All FQNs are prefixed starting from ``model``.
|
||||||
|
|
||||||
|
Args:
|
||||||
|
model (torch.nn.Module): Root module (which may or may not be passed to
|
||||||
|
composable `fully_shard()`).
|
||||||
|
"""
|
||||||
|
|
||||||
|
def module_fn(
|
||||||
|
module, prefix, tree_level, sharded_tree_info, sharded_module_name_to_fqns
|
||||||
|
):
|
||||||
|
num_spaces = tree_level * 4
|
||||||
|
trimed_prefix = (
|
||||||
|
prefix[:-1] if (len(prefix) > 0 and prefix[-1] == ".") else prefix
|
||||||
|
)
|
||||||
|
prefixed_module_name = trimed_prefix + "[" + module.__class__.__name__ + "]"
|
||||||
|
printed_prefixed_module_name = " " * num_spaces + prefixed_module_name
|
||||||
|
|
||||||
|
state = _get_module_fsdp_state(module)
|
||||||
|
if state is None:
|
||||||
|
sharded_tree_info[0] += printed_prefixed_module_name + "\n"
|
||||||
|
return
|
||||||
|
|
||||||
|
handles = state._fully_sharded_module_to_handles.get(module, [])
|
||||||
|
|
||||||
|
if handles:
|
||||||
|
sharded_tree_info[0] += (
|
||||||
|
printed_prefixed_module_name + " FULLY SHARDED" + "\n"
|
||||||
|
)
|
||||||
|
else:
|
||||||
|
sharded_tree_info[0] += printed_prefixed_module_name + "\n"
|
||||||
|
|
||||||
|
for handle in handles:
|
||||||
|
param = handle.flat_param
|
||||||
|
assert type(param) is flat_param_file.FlatParameter
|
||||||
|
global_fqns = [
|
||||||
|
clean_tensor_name(prefix + name) for name in param._fqns
|
||||||
|
] # prefixed from the top level `model` (i.e. including `prefix`)
|
||||||
|
|
||||||
|
if prefixed_module_name in sharded_module_name_to_fqns:
|
||||||
|
sharded_module_name_to_fqns[prefixed_module_name].extend(global_fqns)
|
||||||
|
else:
|
||||||
|
sharded_module_name_to_fqns[prefixed_module_name] = global_fqns
|
||||||
|
|
||||||
|
def return_fn(sharded_tree_info, sharded_module_name_to_fqns):
|
||||||
|
return sharded_tree_info[0], sharded_module_name_to_fqns
|
||||||
|
|
||||||
|
# Use List to mutate its value in place while running the recursive functions
|
||||||
|
sharded_tree_info: List[str] = [
|
||||||
|
"",
|
||||||
|
]
|
||||||
|
sharded_module_name_to_fqns: Dict[str, List[str]] = {}
|
||||||
|
return _apply_to_modules(
|
||||||
|
model,
|
||||||
|
module_fn,
|
||||||
|
return_fn,
|
||||||
|
[key for key, _ in model.named_parameters()],
|
||||||
|
sharded_tree_info,
|
||||||
|
sharded_module_name_to_fqns,
|
||||||
|
)
|
||||||
|
|
@ -1100,7 +1100,7 @@ def _get_param_id_to_param_from_optim_input(
|
||||||
|
|
||||||
|
|
||||||
def _get_flat_param_to_fqn(model: torch.nn.Module) -> Dict[nn.Parameter, str]:
|
def _get_flat_param_to_fqn(model: torch.nn.Module) -> Dict[nn.Parameter, str]:
|
||||||
def module_fn(module, prefix, flat_param_to_fqn):
|
def module_fn(module, prefix, tree_level, flat_param_to_fqn):
|
||||||
for param_name, param in module.named_parameters(recurse=False):
|
for param_name, param in module.named_parameters(recurse=False):
|
||||||
if type(param) is not FlatParameter:
|
if type(param) is not FlatParameter:
|
||||||
continue
|
continue
|
||||||
|
|
@ -1533,7 +1533,7 @@ def _get_fqn_to_fsdp_param_info(model: nn.Module) -> Dict[str, FSDPParamInfo]:
|
||||||
to unique parameters.
|
to unique parameters.
|
||||||
"""
|
"""
|
||||||
|
|
||||||
def module_fn(module, prefix, fqn_to_param_info):
|
def module_fn(module, prefix, tree_level, fqn_to_param_info):
|
||||||
fsdp_state = _get_module_fsdp_state_if_fully_sharded_module(module)
|
fsdp_state = _get_module_fsdp_state_if_fully_sharded_module(module)
|
||||||
if fsdp_state is None:
|
if fsdp_state is None:
|
||||||
return
|
return
|
||||||
|
|
|
||||||
Loading…
Reference in New Issue
Block a user